
【详述】
相同的sql查询hive外表,偶尔查询很慢需要几十秒,但是马上再查就又很快;
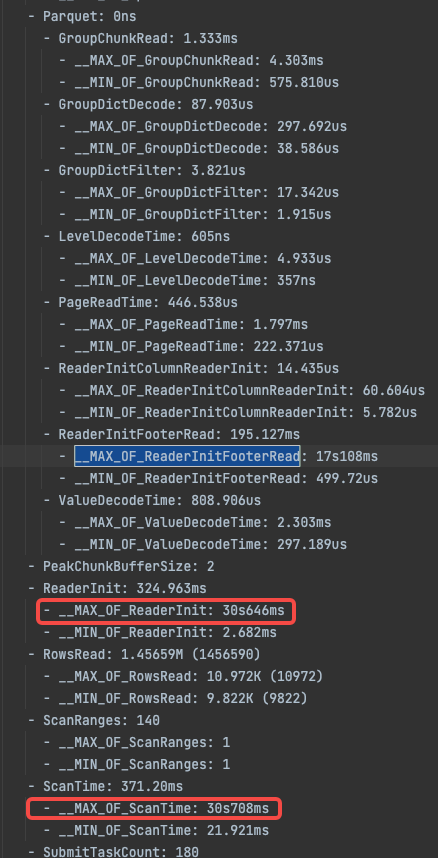
复现后发现是个别 Scan 慢(__MAX_OF_ScanTime大),看日志有个别文件读的慢,但是文件size不大几十kb且对应datanode看起来压力也不大;所以不确定是读 hdfs 慢还是解析慢(__MAX_OF_ReaderInitFooterRead这个时间比较长)。辛苦帮解答下是 hdfs 的问题还是解析 parquet 文件慢
【背景】做过哪些操作?
【业务影响】
【StarRocks版本】2.4.4
【集群规模】例如:3fe + 5be
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】haibo-self@163.com
【附件】
附上1个sql的2个profile,第一个是跑的慢的,第二个是正常跑的;可以看到主要是 scanTime 的差异
slowB_1.txt (126.0 KB)
slowB_2.txt (132.8 KB)
