【StarRocks版本】2.5.3
【集群规模】3fe(1 master+2follower)+20be(fe与be混部)
【机器信息】机械硬盘
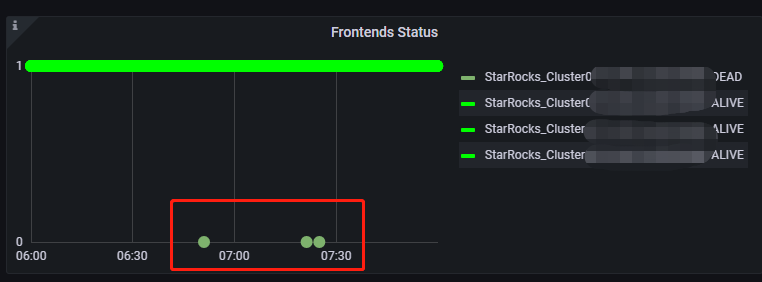
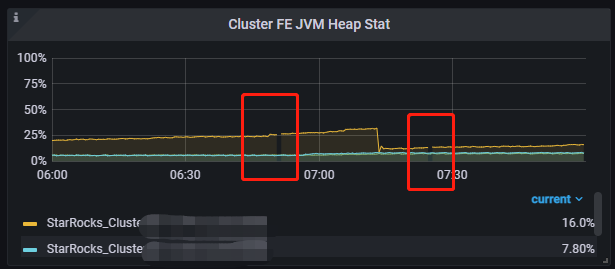
fe leader节点频繁异常,grafana上平均一天要异常几次,但fe leader异常时,jvm内存占用、集群CPU、磁盘io等占用都不算高。
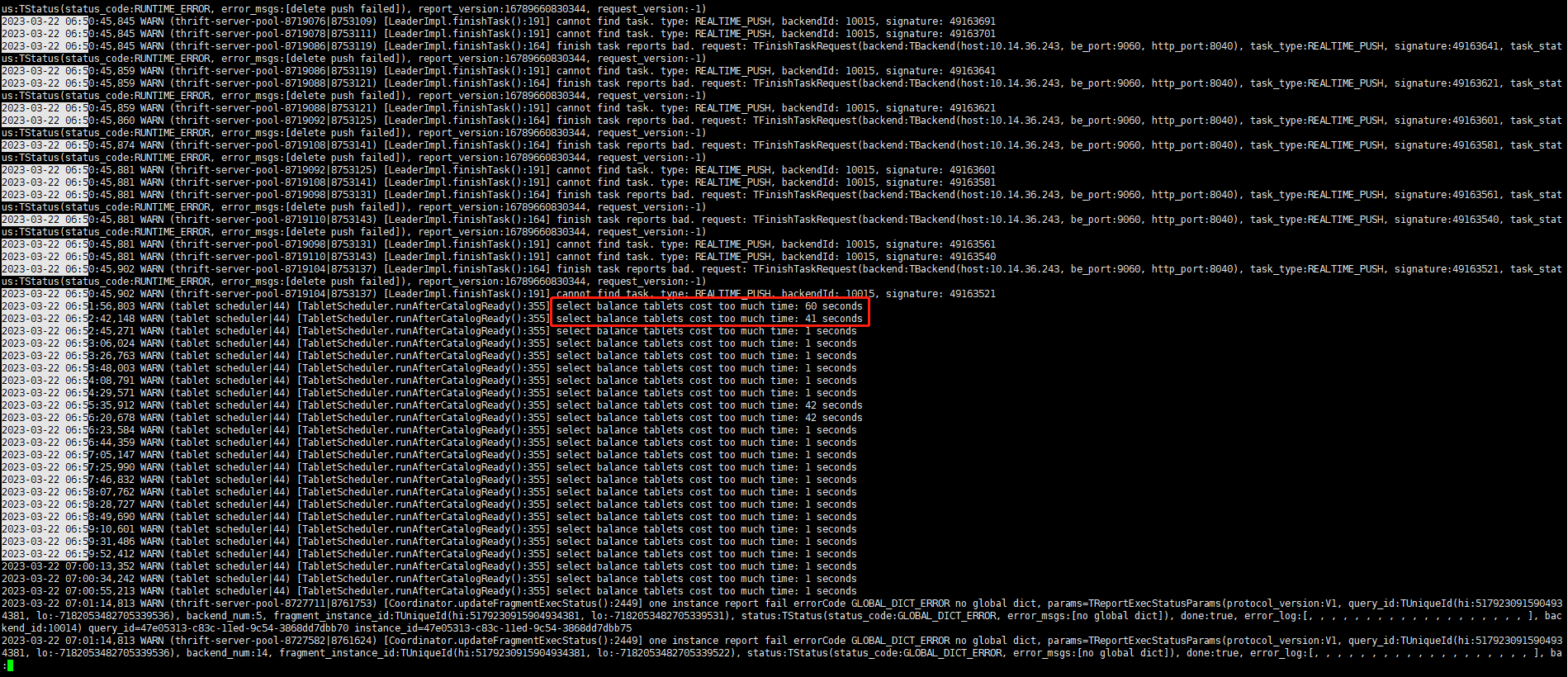
从fe.warn.log上看,fe leader异常时都会出现select balance tablets cost too much time的告警,请问这该如何优化?

【StarRocks版本】2.5.3
【集群规模】3fe(1 master+2follower)+20be(fe与be混部)
【机器信息】机械硬盘
fe leader节点频繁异常,grafana上平均一天要异常几次,但fe leader异常时,jvm内存占用、集群CPU、磁盘io等占用都不算高。
从fe.warn.log上看,fe leader异常时都会出现select balance tablets cost too much time的告警,请问这该如何优化?
麻烦提供下fe.log,fe.gc.log和meta/bdb/je.info.0
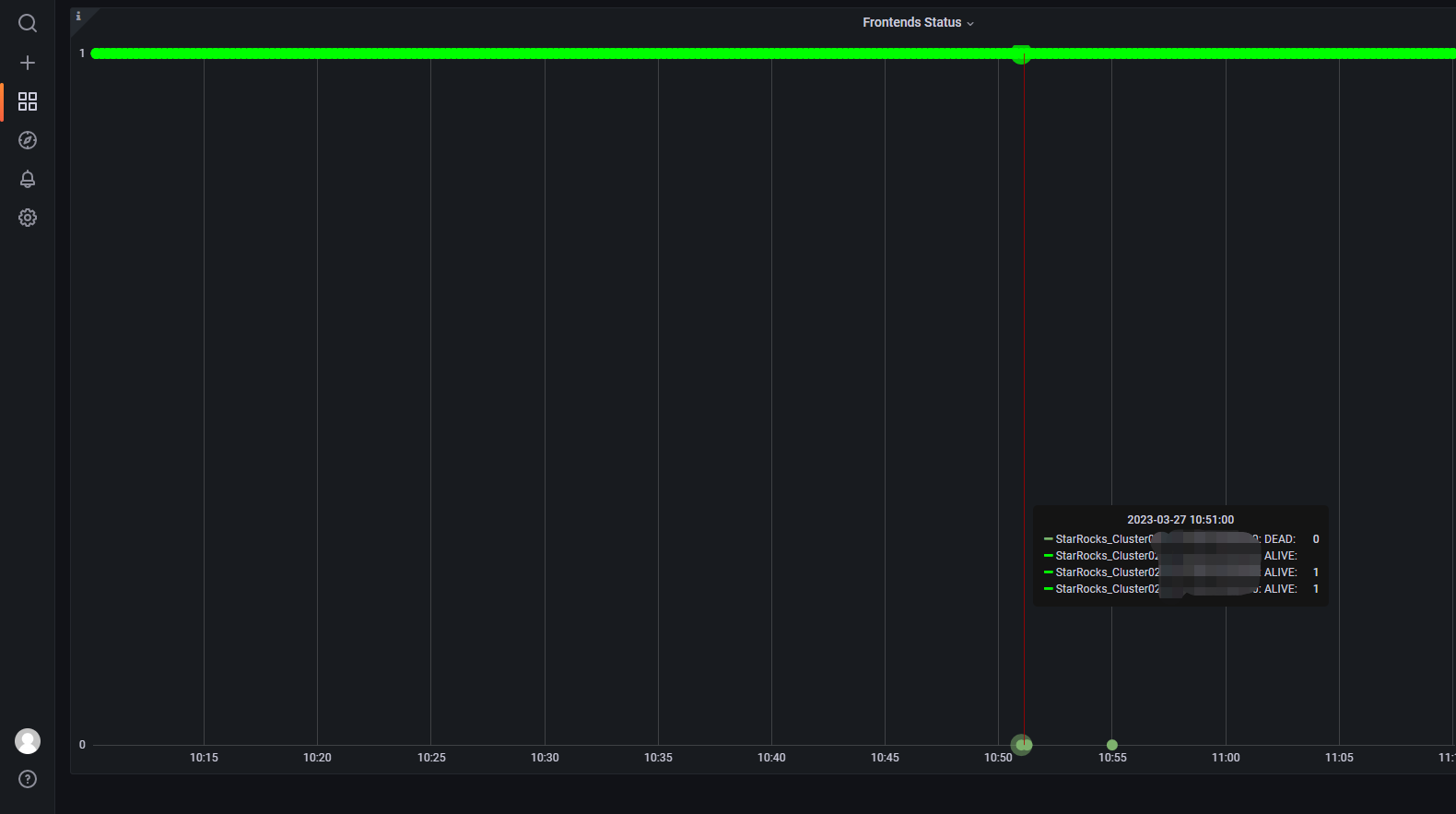
今天(2023-03-27)上午10点51到55分,grafana上显示fe leader又有异常了:
以下是异常时点的相关日志:
fe.log.zip (25.0 MB)
fe.gc.log.zip (93.6 KB)
je.info.0.zip (179 字节)
看日志当时应该是db锁占用的时间比较长,metrics接口超时导致的。
metrics接口在监控这边配置的是多长时间超时?
 默认的10s
默认的10s
我把prometheus的scrape_interval和scrape_timeout都调大到60s后,grafana上没再观察到fe leader异常的现象了。请问这里db锁主要是做什么用的呢,为什么会占用10s以上?谢谢
应该是导入比较频繁导致的,你当时的导入频率是多少?