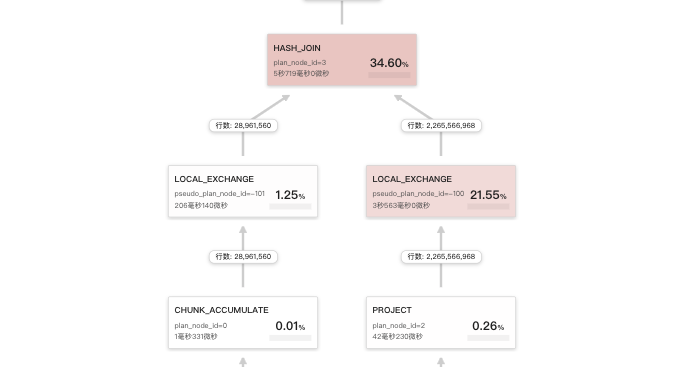
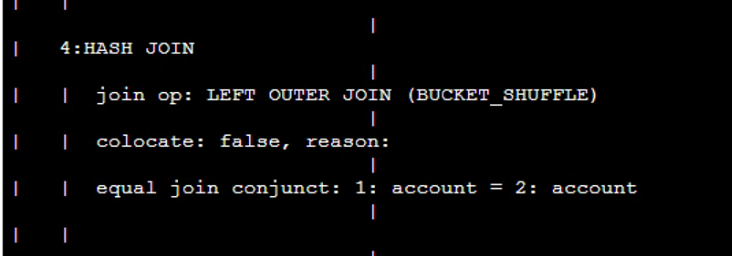
【详述】查询profile分析
【背景】做过哪些操作?
【业务影响】测试,无影响
【StarRocks版本】2.5.1
【集群规模】3fe + 11be
【机器信息】CPU虚拟核/内存/网卡,例如:16C/64G/千兆
【联系方式】pengjun_a@aspirecn.com
【附件】
数据量蛮大的 机器配置是16c的是吗 这个您那边预期是多少? 然后这个查询唯一优化点在于数据有点倾斜 可以更改下
min和max差别有点明显 可以执行下这个 工具看下tablet分布是否均衡 工具:tools.tar(1).gz (23.9 MB)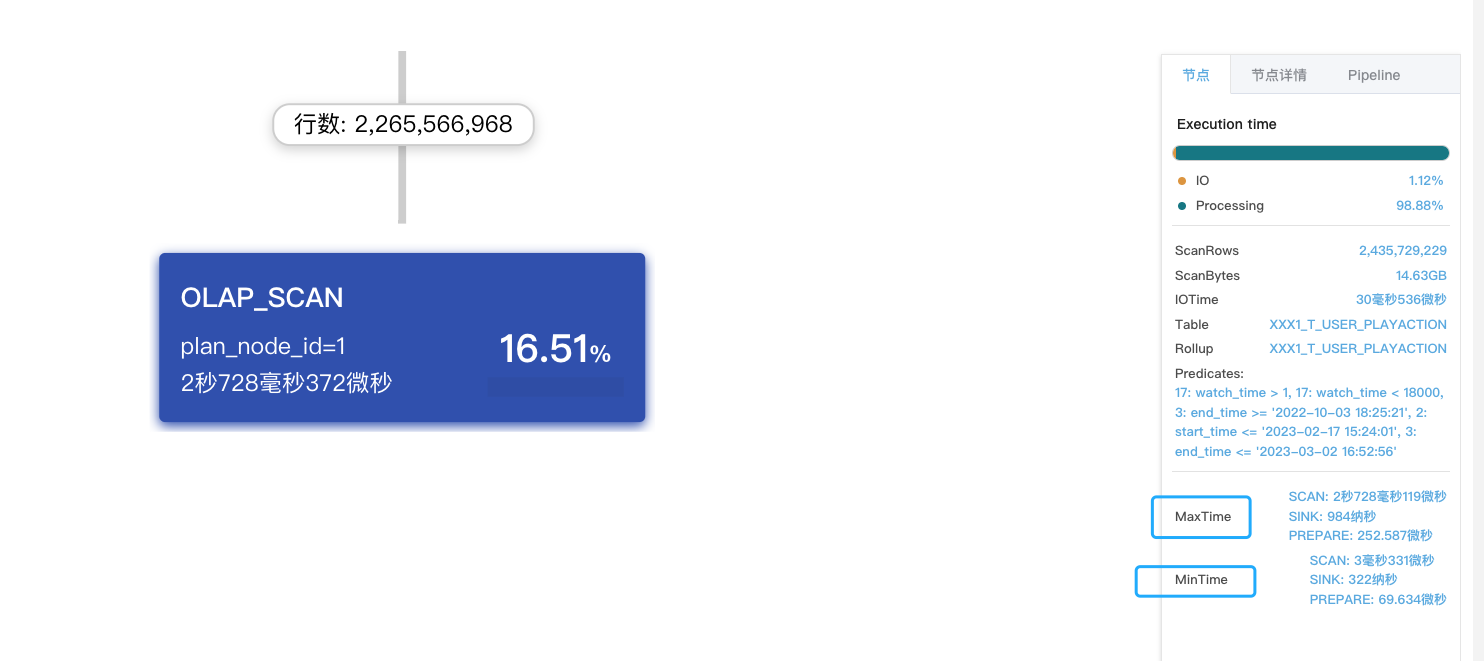
下载完成后编辑config.ini信息,然后执行
./healthy_report config.ini
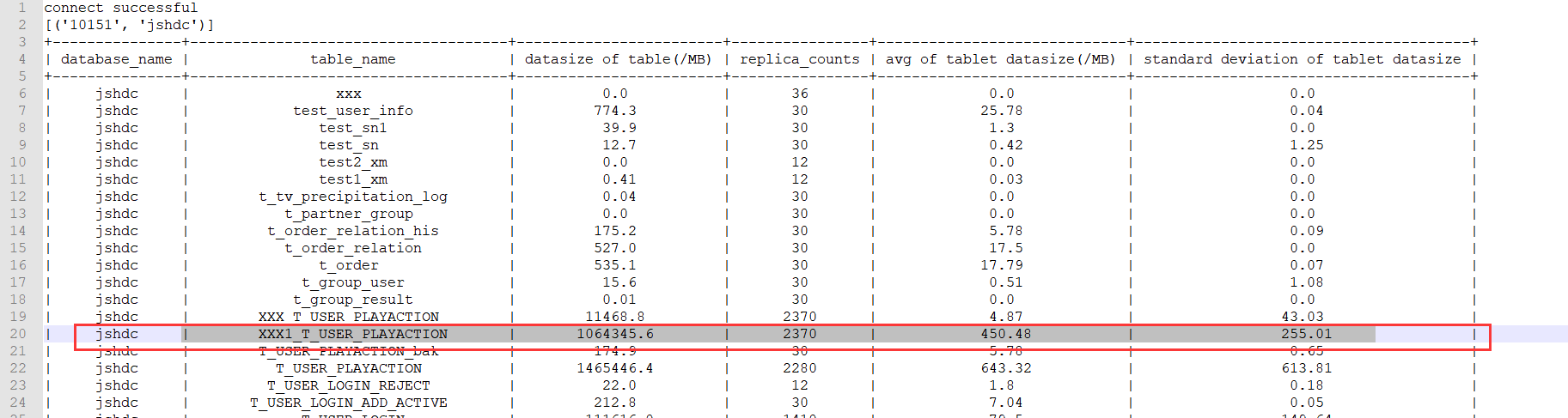
可以获取以下信息:
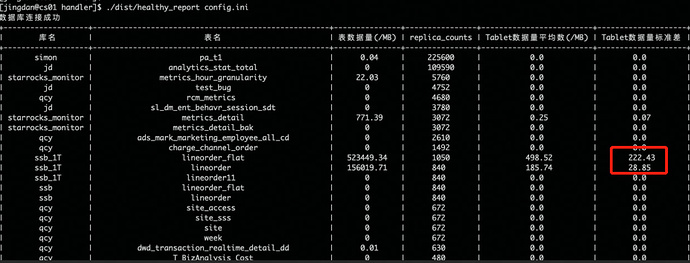
以上信息中关注下标准差那列,如果异常高,则表示该表需要重新选取hash键,建表不合理有严重的数据倾斜问题。
除此还可以关注下tablet数据平均值是否合理,一般建议该值在100MB-1GB之间,对于表总体数据量比较小时可以容忍小一点,数据量大的表建议在1G左右,如果该值与建议值差异较大,可以适当调整建表语句的bucket数量大小。
预期在3-5秒以内,该表的分桶平均数据大小450M,符合100M-1GB的原则,标准差为255,因为要做colocation,分桶健不能改,其实每周的数据差不多,为什么分布不均衡?
关于tablet的大小怎么预估,与哪些值有关?
这两个表join为啥要走colocate呢?现在看着右表太大了,左右表调整下顺序,加下hint 走broadcast看看