【详述】问题详细描述
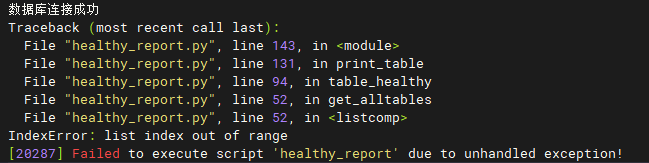
执行一个查询SQL,耗时3s左右,耗时太长,需要缩短执行时长,优化查询性能。
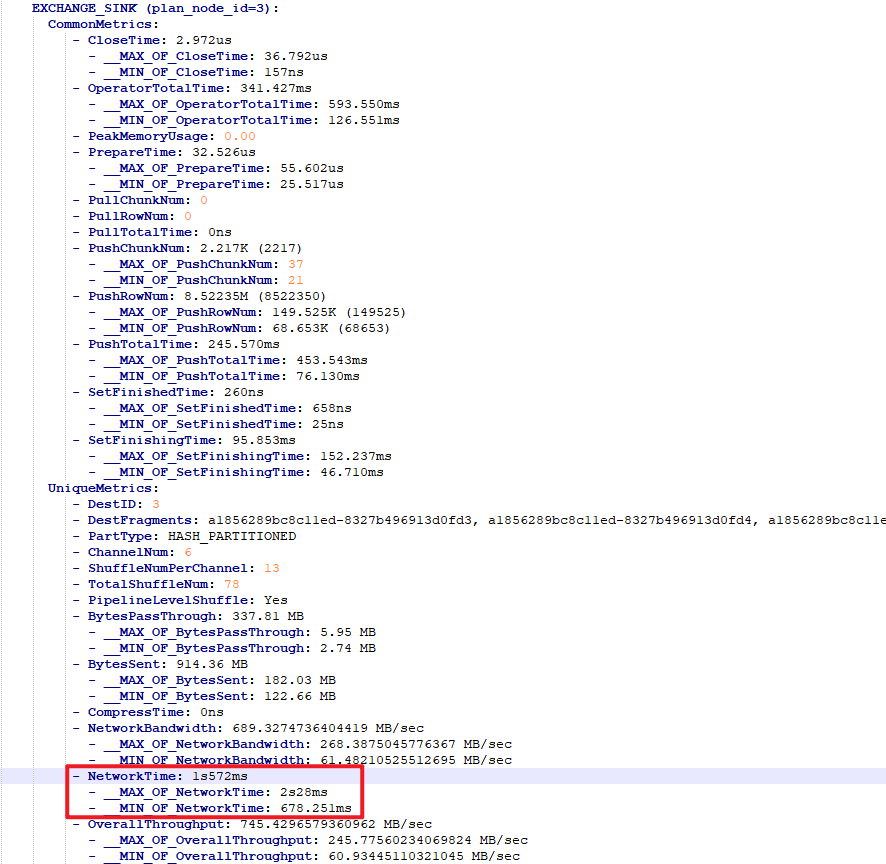
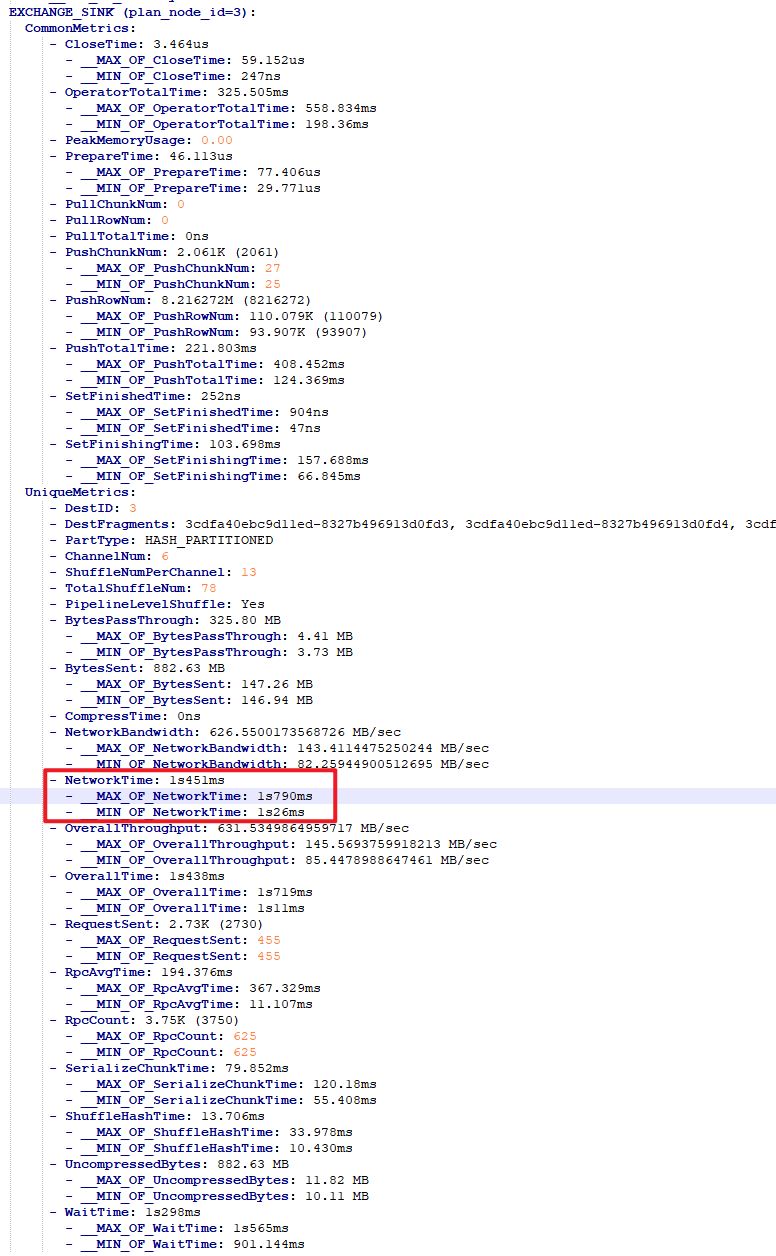
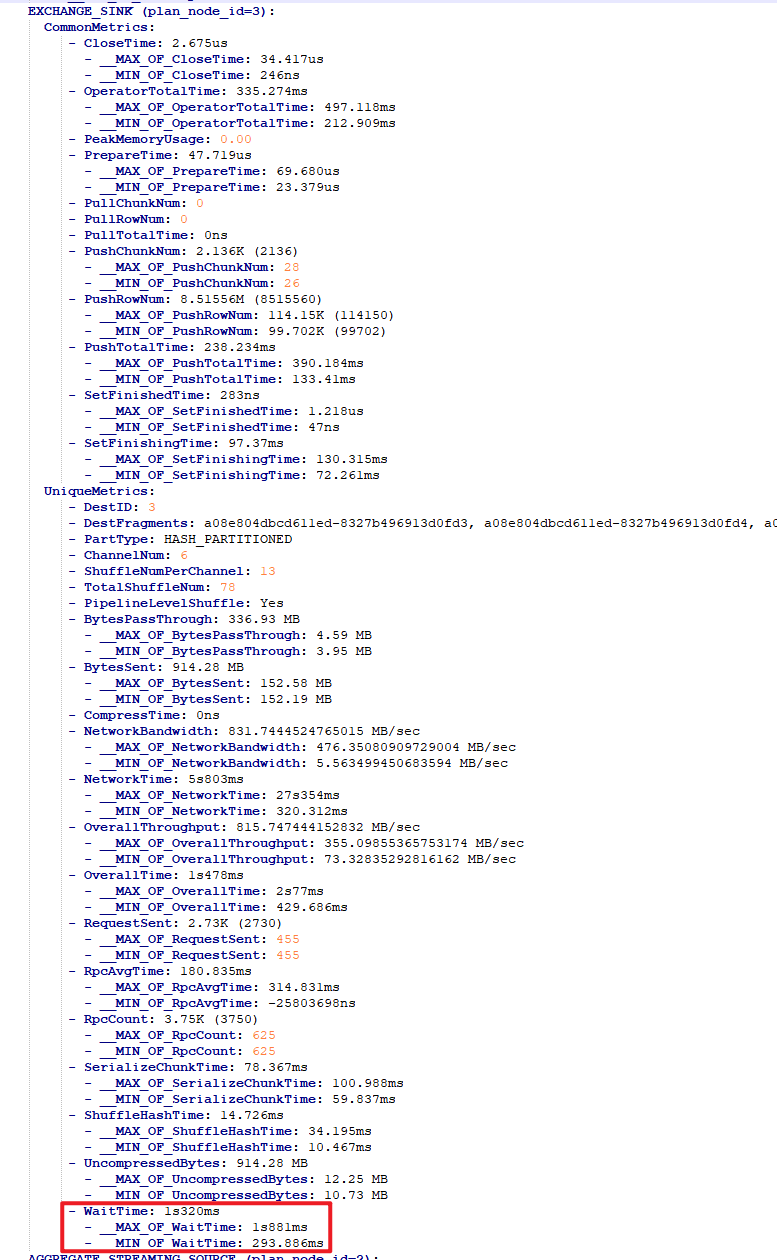
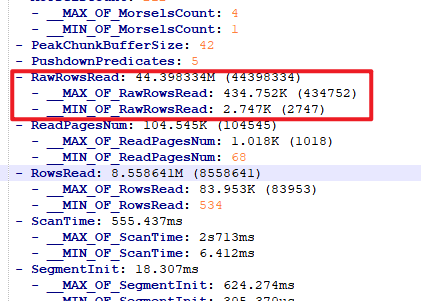
看Profile,显示Exchange Operator的Network耗时比较长,请问有什么优化建议吗?
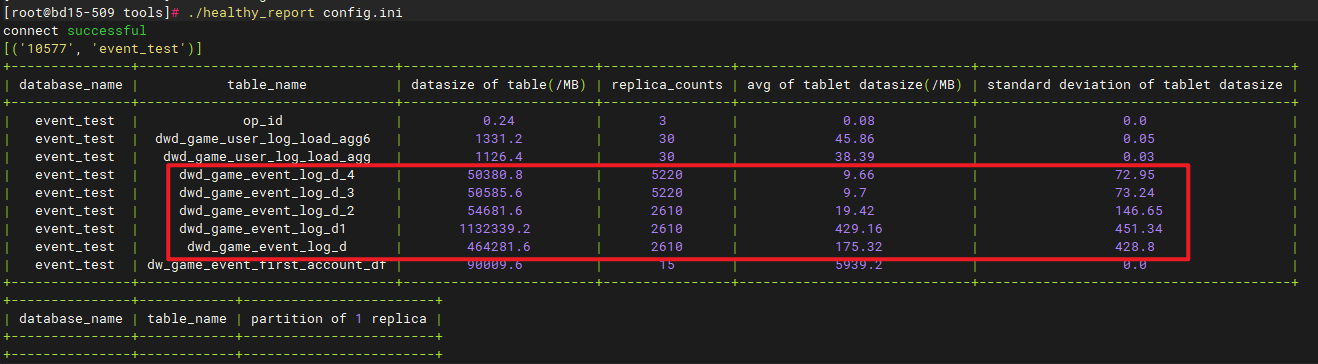
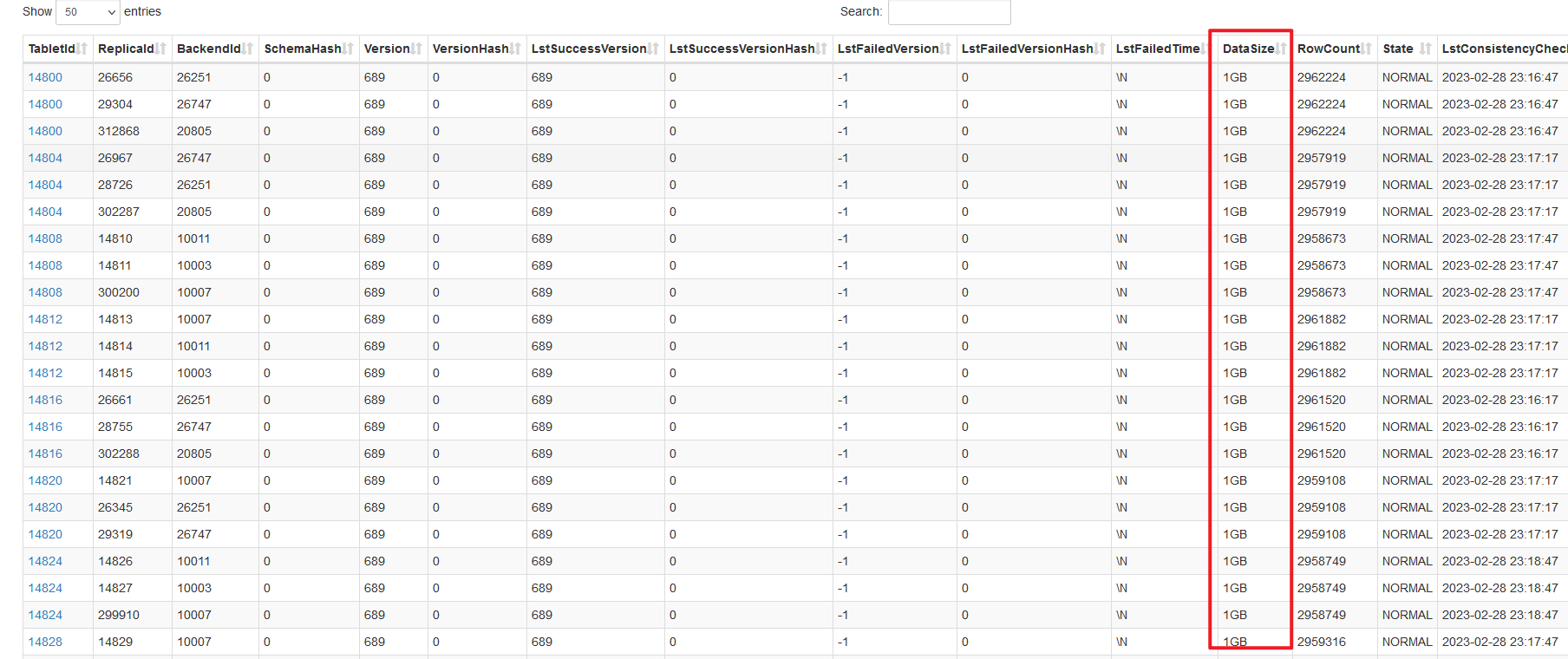
单分区4000万数据量
DDL:
CREATE TABLE dwd_game_event_log_d_2 (
dt date NULL COMMENT “分区”,
event_no varchar(65533) NULL COMMENT " 根据事件相关原始日志全字段生成MD5(32位小写),用于去重",
event_tp varchar(65533) NULL COMMENT “事件类型”,
event_id varchar(65533) NULL COMMENT " 事件id",
server_time datetime NULL COMMENT " 服务器时间, yyyy-MM-dd hh:mm:ss格式",
…
INDEX i_op_id (op_id) USING BITMAP COMMENT ‘’,
INDEX event_tp (event_tp) USING BITMAP,
INDEX event_id (event_id) USING BITMAP
) ENGINE=OLAP
DUPLICATE KEY(dt, event_no)
COMMENT “事件表”
PARTITION BY RANGE(dt)
(PARTITION p20230109 VALUES [(“2023-01-09”), (“2023-01-10”)),
PARTITION p20230110 VALUES [(“2023-01-10”), (“2023-01-11”)),
PARTITION p20230111 VALUES [(“2023-01-11”), (“2023-01-12”)),
PARTITION p20230112 VALUES [(“2023-01-12”), (“2023-01-13”)))
DISTRIBUTED BY HASH(event_no) BUCKETS 15
PROPERTIES (
“replication_num” = “3”,
“bloom_filter_columns” = “server_time, pre_account, server_id”,
“in_memory” = “false”,
“storage_format” = “DEFAULT”,
“enable_persistent_index” = “false”,
“compression” = “LZ4”
);
SQL:
select
376,op_id,pre_account,account,role_id,server_id
,min(coalesce(first_stime,first_time)) first_time
,min(reg_stime) act_time
,min(f_pay_stime) first_pay_time
,min(role_first_pay_stime) role_first_pay_time
,max(if(coalesce(first_opid,’’) <> ‘’,first_opid,null)) first_opid
,max(if(coalesce(first_server_id,’’) <> ‘’,first_server_id,null)) first_server_id
,max(if(coalesce(first_ip,’’) <> ‘’,first_ip,null)) first_ip
,max(if(coalesce(reg_ip,’’) <> ‘’,reg_ip,null)) act_ip
,max(if(coalesce(first_lang,’’) <> ‘’,first_lang,null)) first_lang
,max(if(coalesce(role_first_lang,’’) <> ‘’,role_first_lang,null)) role_first_lang
,max(role_level) role_level
,max(role_vip) role_vip
,max(if(coalesce(role_name,’’) <> ‘’ and length(role_name) >= 1,role_name,null)) role_name
,max(if(coalesce(role_career,’’) <> ‘’ and length(role_career) >= 1,role_career,null)) role_career
,count(distinct if(lower(event_id) = ‘rolelogin’,event_no,null)) login_num
from dwd_game_event_log_d_2 t11
where 1=1
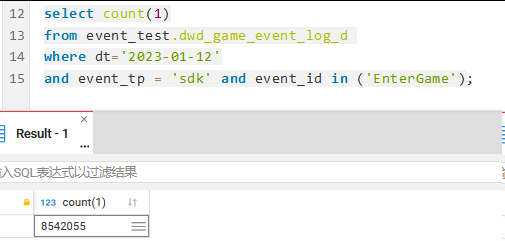
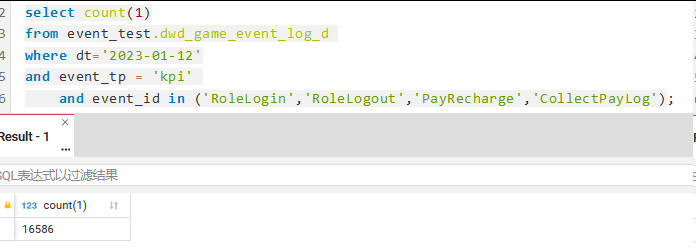
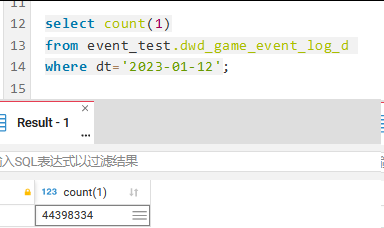
and dt=‘2023-01-12’
and TO_DATE(server_time) = ‘2023-01-12’
and (
(event_tp = ‘kpi’ and event_id in (‘Login’,‘Logout’,‘Recharge’,‘PayLog’))
or (event_tp = ‘sdk’ and event_id in (‘Enter’))
)
and length(pre_account) < 200
group by op_id,pre_account,account,role_id,server_id
【StarRocks版本】2.5.2
【集群规模】3fe(3 follower)+6be(fe与be混部)
【机器信息】48C/64G/千兆
【附件】
- Profile信息
profile.yaml (67.4 KB) - 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;

show variables like ‘%pipeline_dop%’;
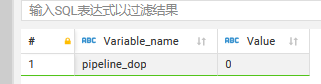
- pipeline是否开启:show variables like ‘%pipeline%’;
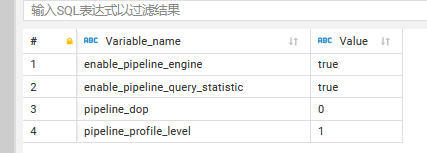
- 执行计划:
explain.txt (21.3 KB)