
【详述】问题详细描述
【背景】做过哪些操作?
【业务影响】
【StarRocks版本】例如:2.4.4
【集群规模】例如:3fe(1 follower+2observer)+5be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群4-小李或者邮箱,谢谢
【附件】
- fe.log/beINFO/相应截图
- 慢查询:
- Profile信息,获取Profile,通过Profile分析查询瓶颈
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
- pipeline是否开启:show variables like ‘%pipeline%’;
- be节点cpu和内存使用率截图
- 查询报错:
- query_dump,怎么获取query_dump文件
- be crash
- be.out
flink 1.14.5。写入sr 2.4.4版本 突然报如下错误
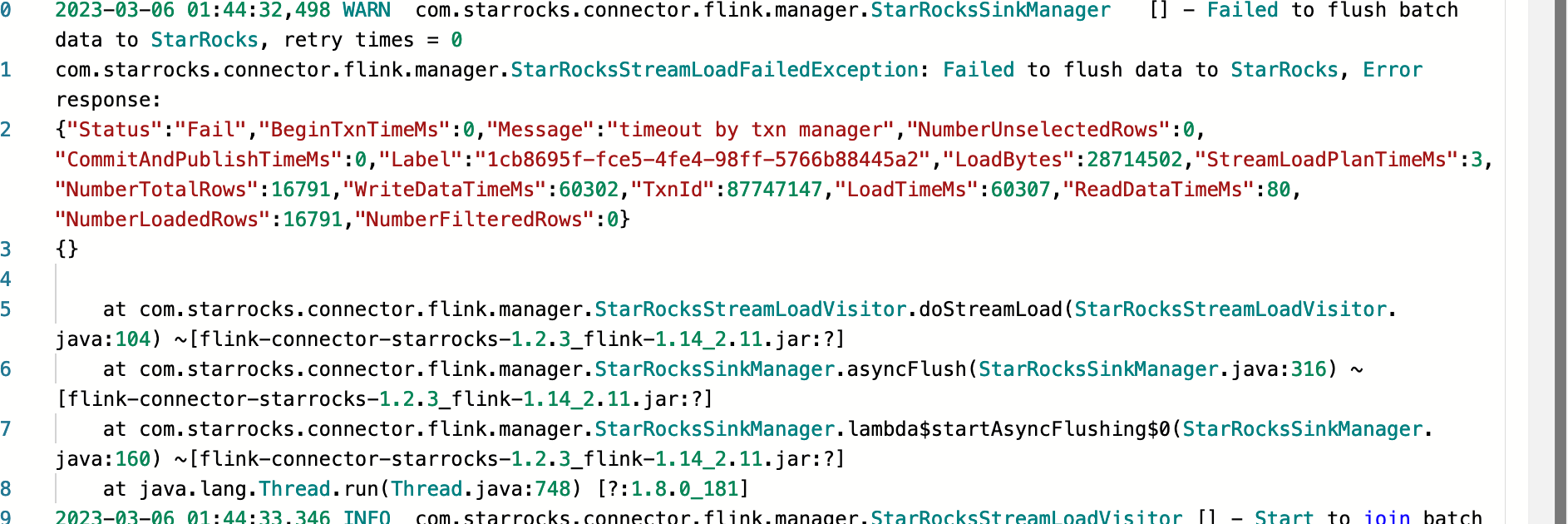
be的warring日志
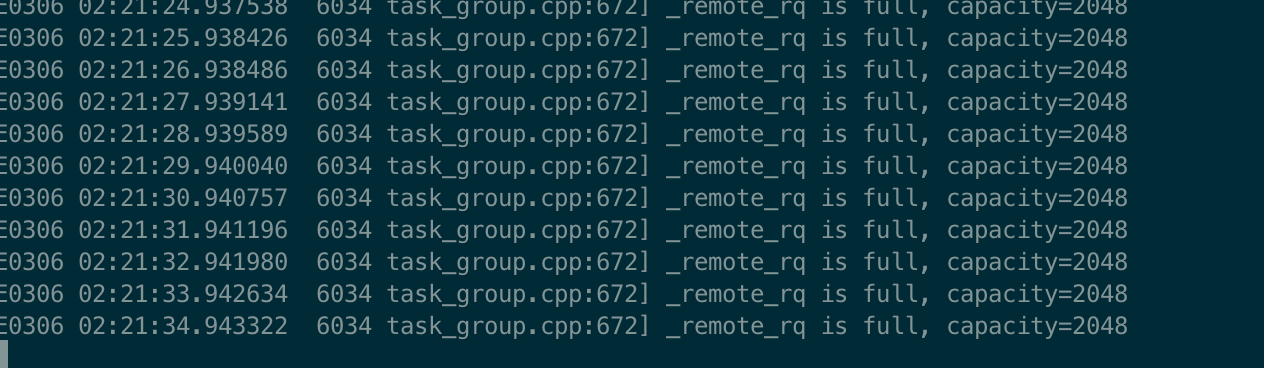
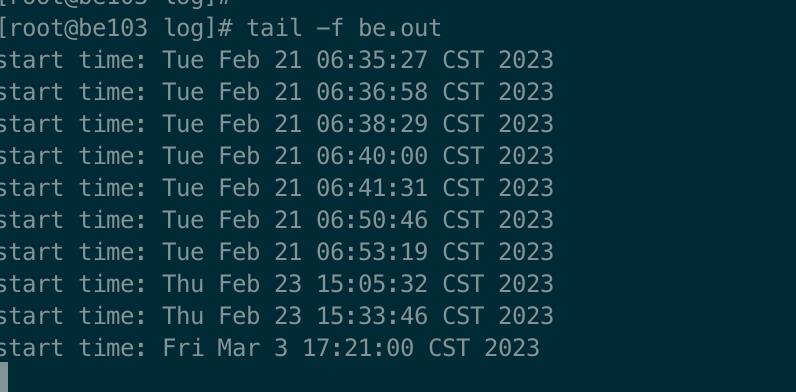
be.out 日主
重启问题be 后。报如下错误。 现在这个be 起不来了
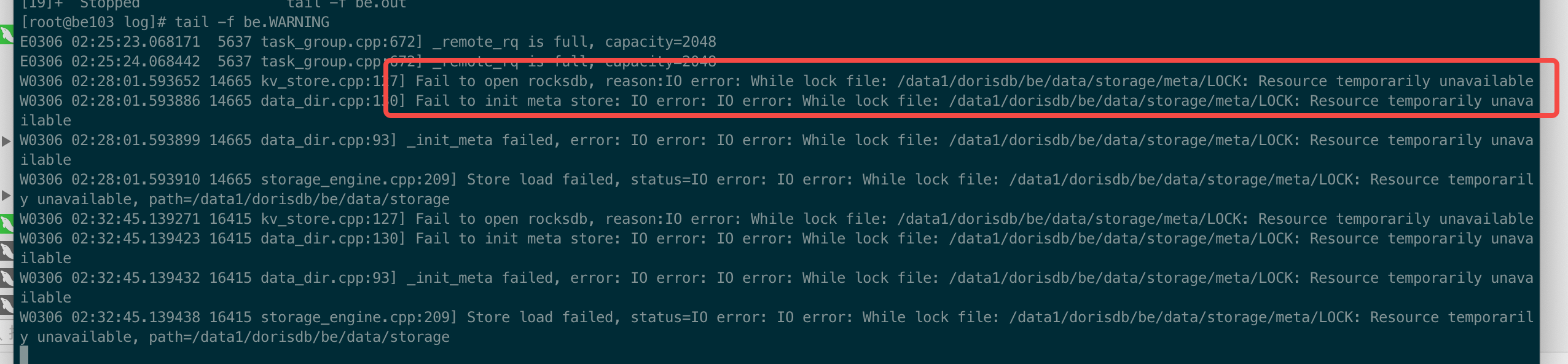
重启ecs服务器, 阿里云的人说是有一人磁盘损坏 拉不起来了, 是由于磁盘损坏出这个错误还是这种情况下 重启服务器 会损坏磁盘 ?
另外早上实时任务写入报错,

按理说。我表是3副本 为什么挂掉一个节点 就写不进去了