版本2.5.1
3台FE:36,37,38机器
7台BE:32-38
配置:32c,64g,3T*3机械硬盘
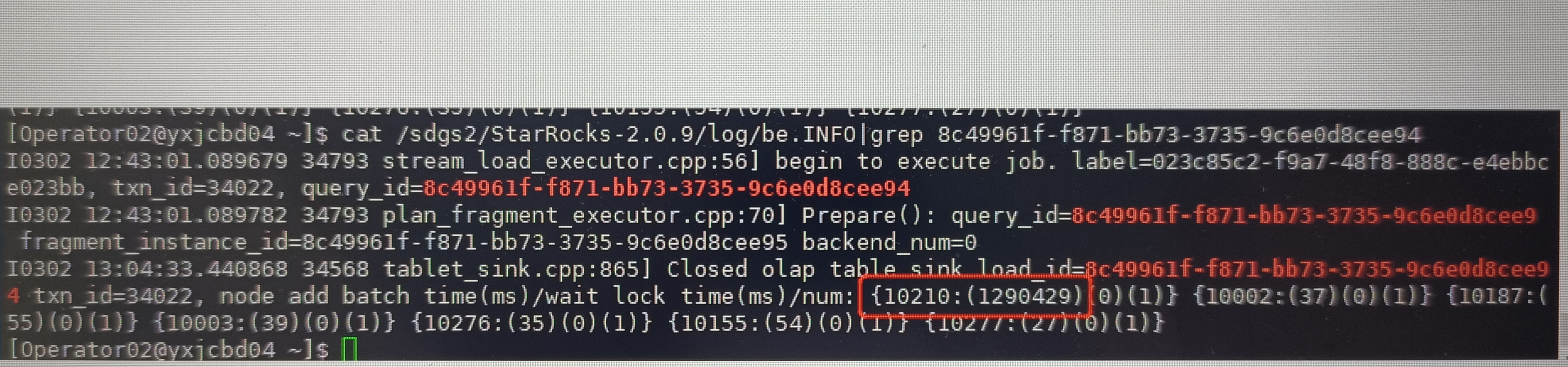
我正在通过自研的程序导入数据,用的streamload,每次提交5w条数据,正常6秒写入成功。然后我通过dbeaver查看某张表的数据,发现卡住了,如下图
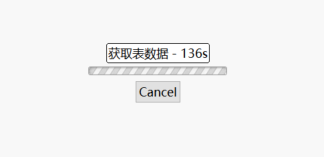
此时streamload也卡住了,因为streamload的超时时间我设置的很高,所以卡了半个小时以后提交成功了,这半个小时里整个数据库什么都做不了。

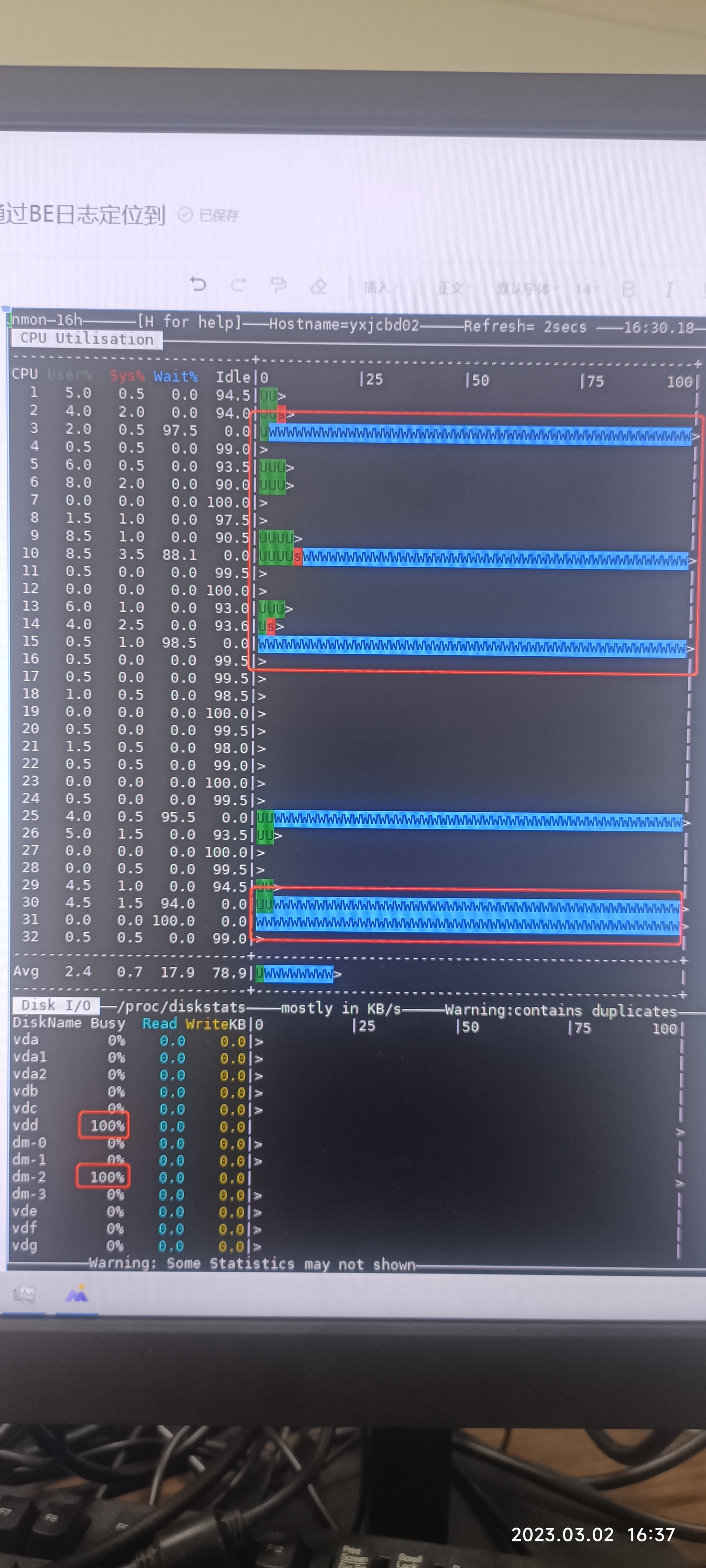
我的集群没什么负载,只有那一个streamload在跑,每块硬盘写入速度300MB/S
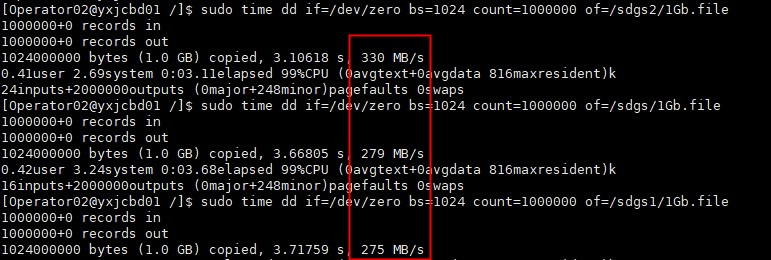
所有FE跟BE看上去都正常,心跳也都正常,也没什么错误日志
我重启3个FE后依旧如此
我尝试通过官方脚本停止BE,执行命令后BE变成了僵尸进程

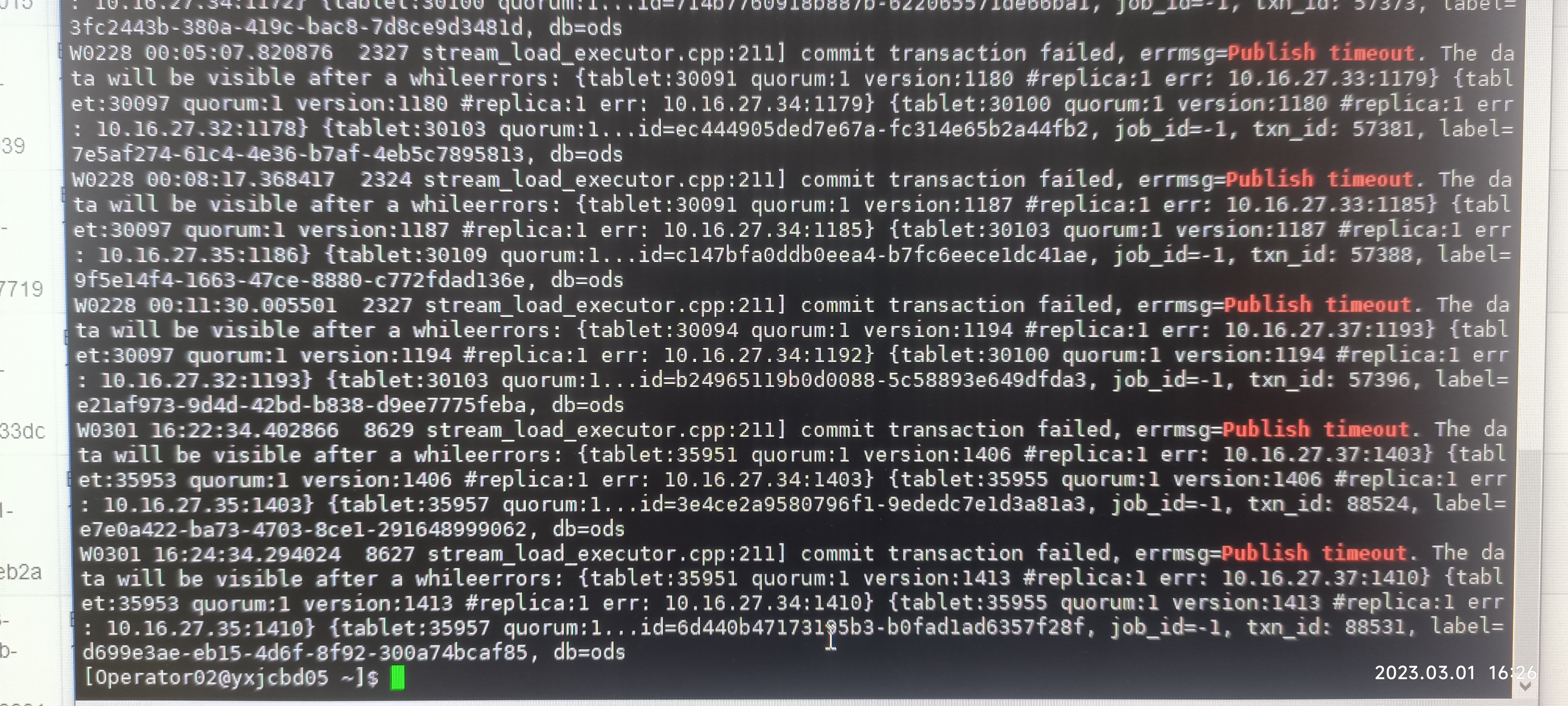
日志中经常有如下的告警,不知这个告警是否重要
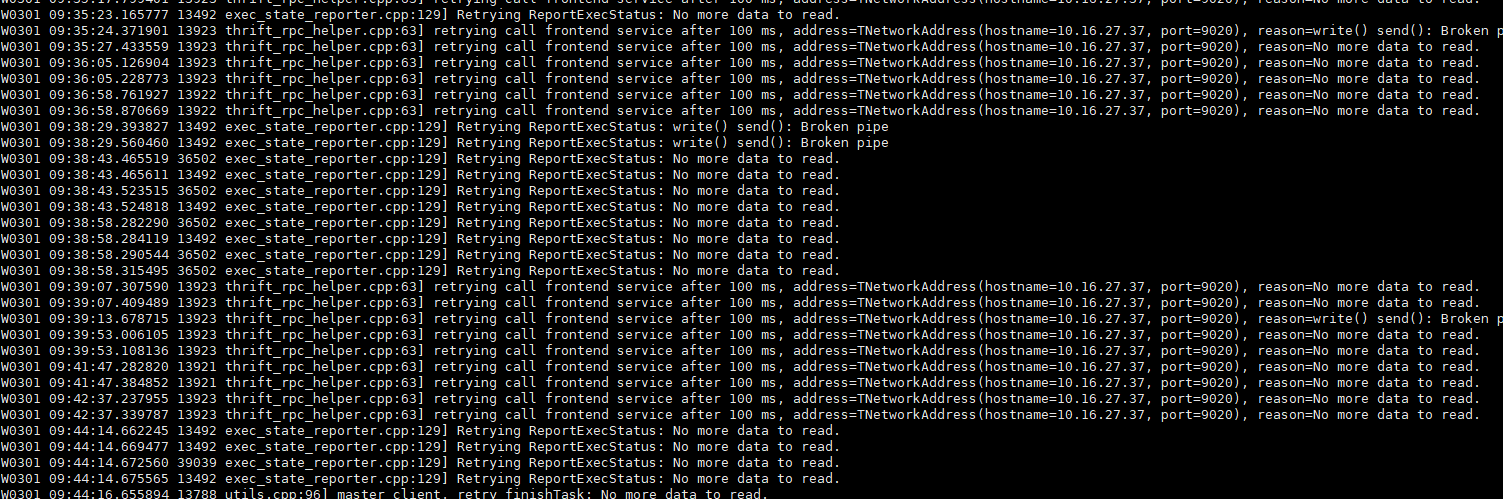
当我同时开启4个streamload时也会像上面这个过程一样卡住,尝试多次都这样,现在这个情况没法用啊,再次强调:集群没什么负载