【详述】问题详细描述
【背景】Streamload写入,时不时会报错,有时候甚至会达到重试次数3,然后抛出异常:
2023-02-27 13:43:45,292 WARN com.starrocks.connector.flink.manager.StarRocksSinkManager [] - Failed to flush batch data to StarRocks, retry times = 0
com.starrocks.connector.flink.manager.StarRocksStreamLoadFailedException: Failed to flush data to StarRocks, Error response:
{“Status”:“Fail”,“BeginTxnTimeMs”:101,“Message”:“call frontend service failed, address=TNetworkAddress(hostname=10.5.140.21, port=9020), reason=THRIFT_EAGAIN (timed out)”,“NumberUnselectedRows”:0,“CommitAndPublishTimeMs”:0,“Label”:“f63a6304-c179-4296-b8ab-89ab8c8b311f”,“LoadBytes”:0,“StreamLoadPlanTimeMs”:0,“NumberTotalRows”:0,“WriteDataTimeMs”:0,“TxnId”:448487,“LoadTimeMs”:0,“ReadDataTimeMs”:0,“NumberLoadedRows”:0,“NumberFilteredRows”:0}
{}
at com.starrocks.connector.flink.manager.StarRocksStreamLoadVisitor.doStreamLoad(StarRocksStreamLoadVisitor.java:104) ~[flink-connector-starrocks-1.2.1_flink-1.13_2.11.jar:?]
at com.starrocks.connector.flink.manager.StarRocksSinkManager.asyncFlush(StarRocksSinkManager.java:324) ~[flink-connector-starrocks-1.2.1_flink-1.13_2.11.jar:?]
at com.starrocks.connector.flink.manager.StarRocksSinkManager.lambda$startAsyncFlushing$0(StarRocksSinkManager.java:161) ~[flink-connector-starrocks-1.2.1_flink-1.13_2.11.jar:?]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_252]
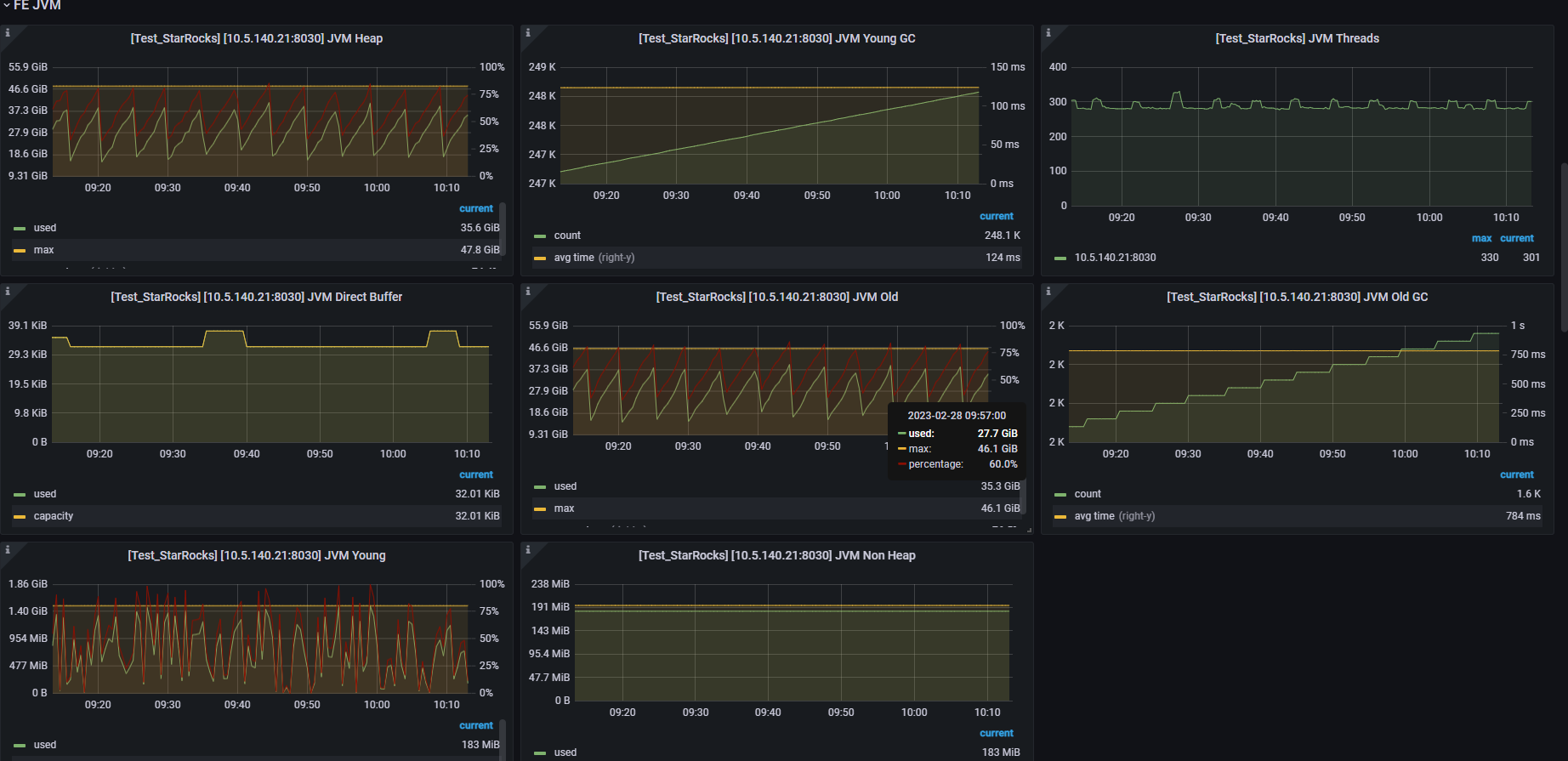
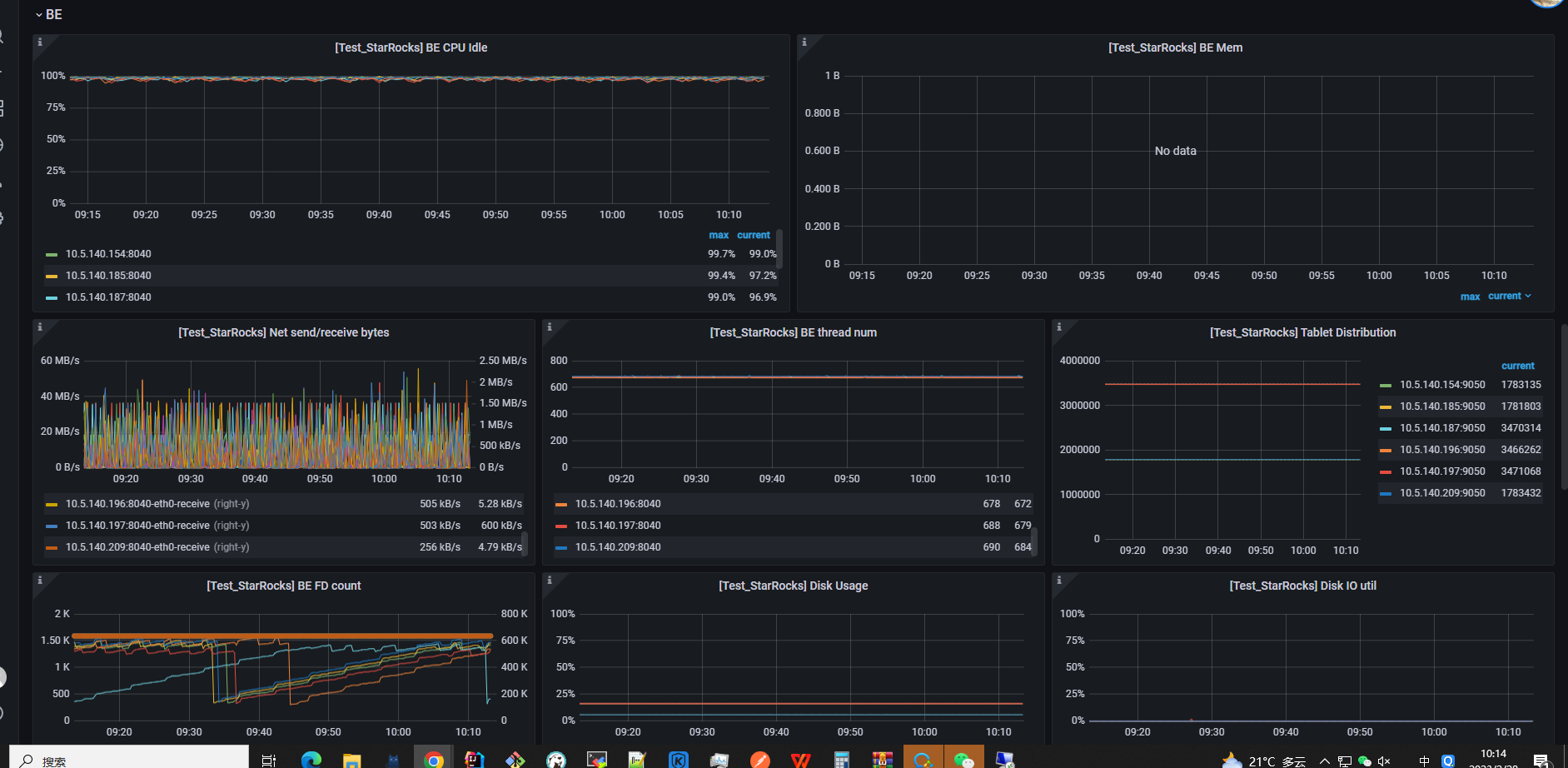
FE分配了48G内存,几乎没有访问,但是却经常报超时。
【StarRocks版本】StarRocks-2.5.1 。 2月17号下载的版本
【集群规模】1fe+6be