
Flink connector demo
一、背景
本文主要阐述用flink connector方式导入数据到StarRocks。
二、代码样例
样例demo代码:
flink4sr.rar (22.1 KB)
IDEA新建一个工程,在pom.xml文件中添加

dependency>
<groupId>com.starrocks</groupId>
<artifactId>flink-connector-starrocks</artifactId>
<!-- for flink-1.11, flink-1.12 -->
<version>x.x.x_flink-1.11</version>
<!-- for flink-1.13 -->
<version>x.x.x_flink-1.13</version>
</dependency>
示例pom文件如下:
pom.xml (8.1 KB)
添加后会自动下载依赖.
三、检查jdk
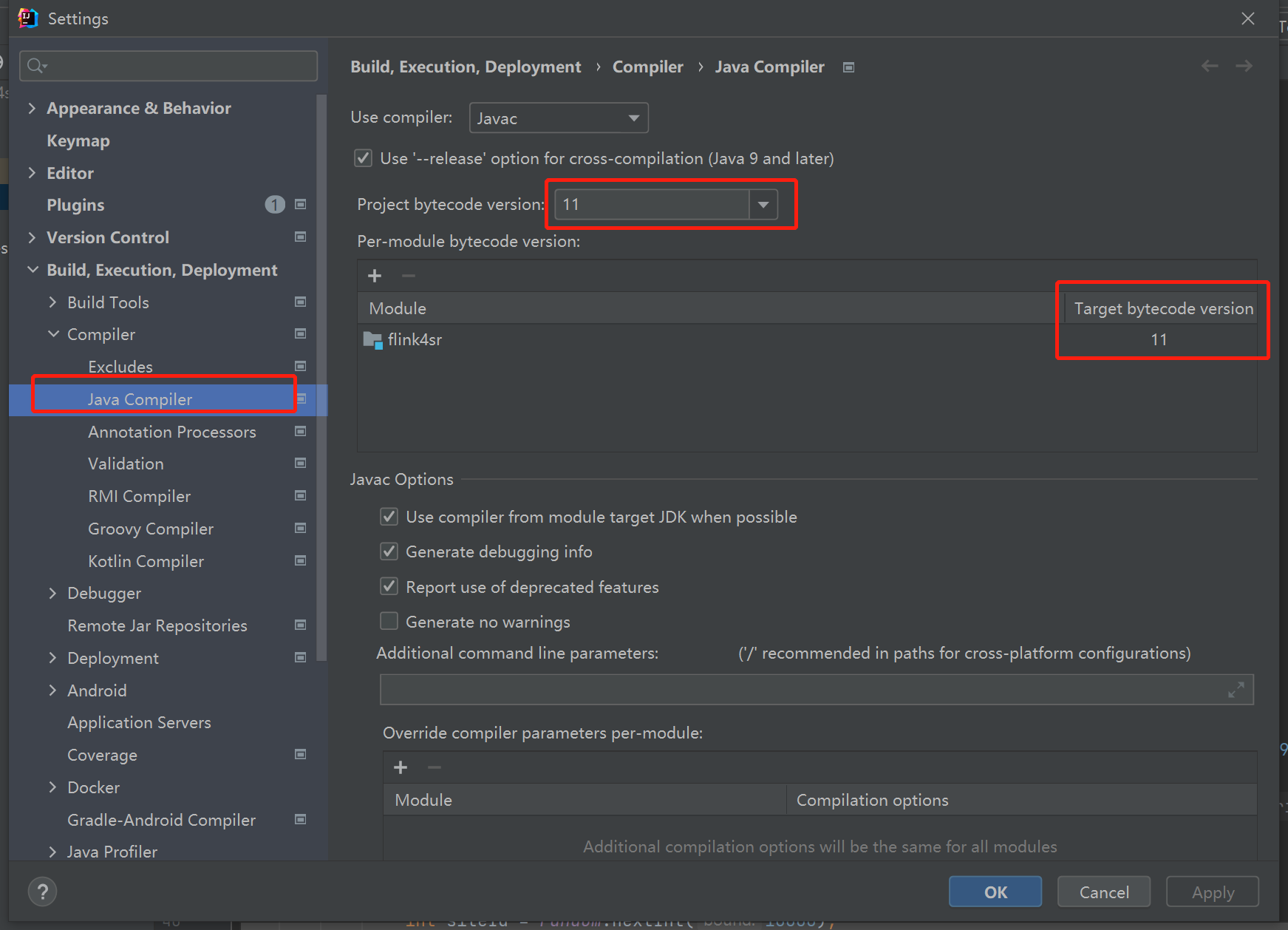
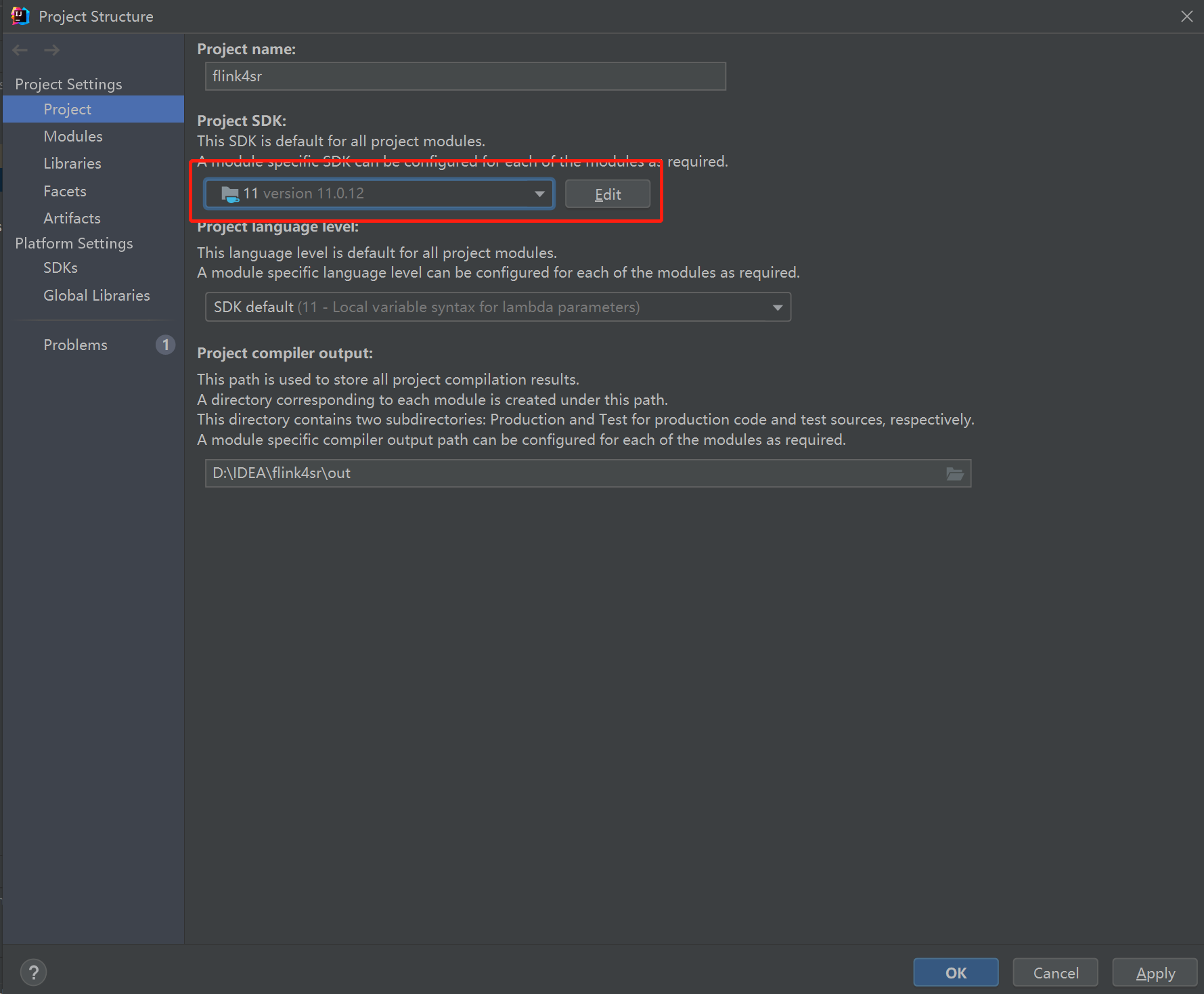
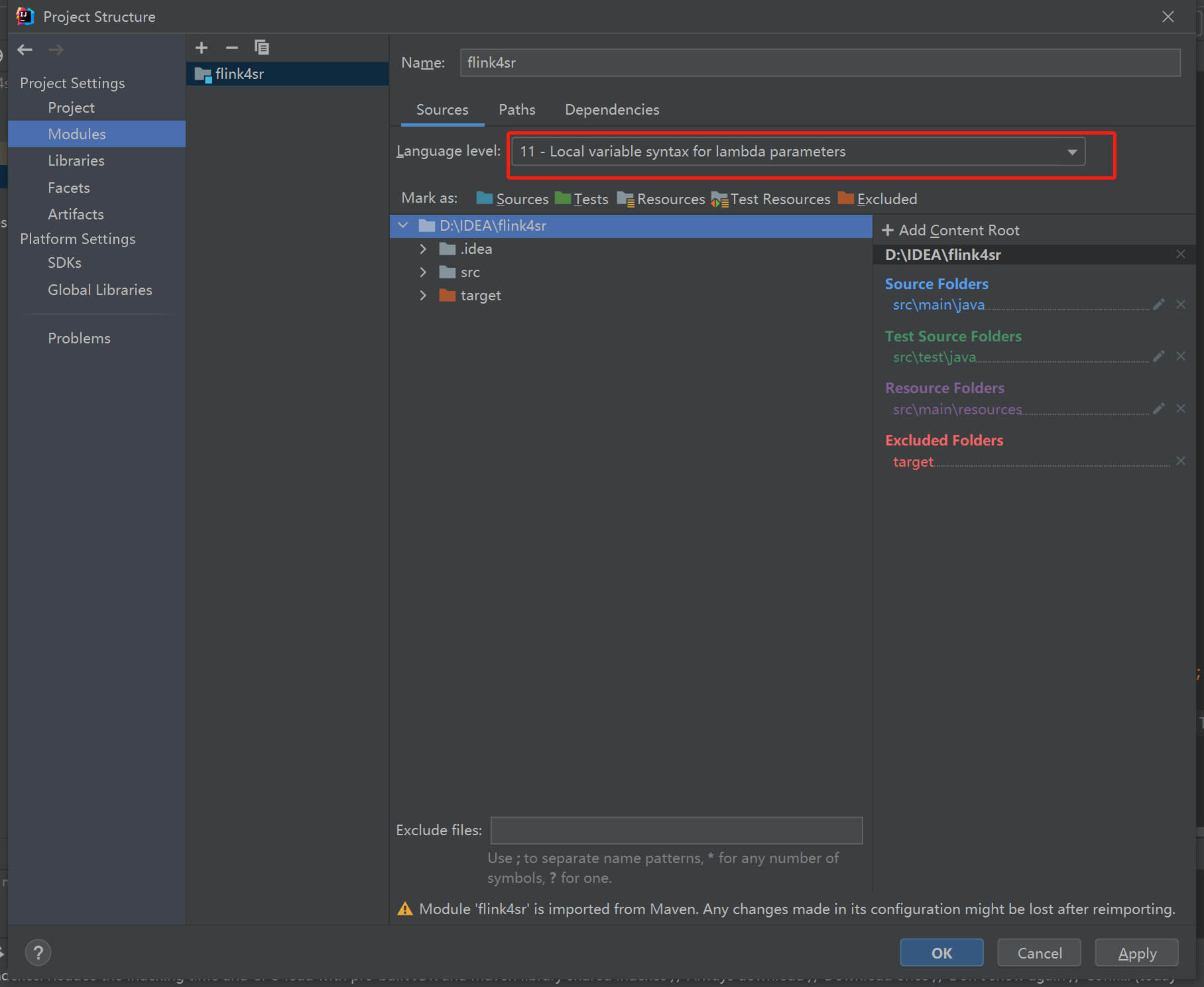
如果有以下报错Project JDK is not defined 时需要修改文件jdk环境为安装版本。

3.1 file–setting
3.2 file–Project Structure
3.3 file–Project Structure
以下为filnk-connect-starrocks的demo的使用示例:
四、StaticDataTest
4.1 DDL
create table StaticData(
`siteid` int,
`citycode` int,
`username` varchar(10),
`pv` int
)
engine = OLAP
DUPLICATE key (`siteid`)
distributed by hash(`siteid`) buckets 3
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
4.2 代码文件
StaticDataTest.java (3.1 KB)
4.3 运行demo文件
修改文件中相应jdbc-url,load-url,username,password,table-name,database-name等参数
执行demo:StaticDataTest.java
注:集群的fe/be的http port和fe的query_port需要能够访问(可以ping一下通不通)

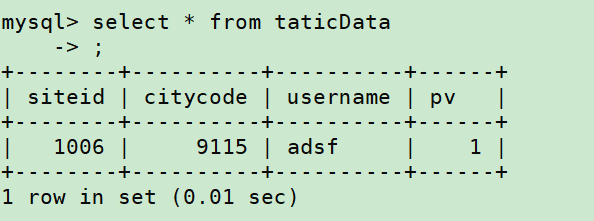
如图所示插入成功。
查询数据:
五、JsonDataTest
5.1 DDL
create table JsonData(
`siteid` int,
`citycode` int,
`username` varchar(10),
`pv` int
)
engine = OLAP
DUPLICATE key (`siteid`)
distributed by hash(`siteid`) buckets 3
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
5.2 代码文件
JsonDataTest.java (2.9 KB)
5.3 运行demo文件
修改文件中相应jdbc-url,load-url,username,password,table-name,database-name等参数
注:集群的fe/be的http port和fe的query_port需要能够访问(可以ping一下通不通)
这里我们在服务器起一个线程动态输入数据,需要先启动端口监听,再运行程序进行测试,否则程序运行会报错,可以通过StarRocks连接器中的sink.buffer-flush.interval-ms属性调整数据落库时间间隔
nc -lk port
注:nc -lk port 开启永久监听TCP端口,去掉k开启临时监听TCP端口
执行demo文件
在服务器起的进程端口窗口输入数据,本案例中siteid,citycode,pv三个字段的值程序自动生成,此处只需要填写value值即可

可以看到已经receive data
然后去数据库查询就可以看到数据已经写入

六、BeanDataTest
6.1 DDL
create table BeanData(
`siteid` int,
`citycode` int,
`username` varchar(10),
`pv` int
)
engine = OLAP
DUPLICATE key (`siteid`)
distributed by hash(`siteid`) buckets 3
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "DEFAULT"
);
6.2 代码文件
BeanDataTest.java (3.6 KB)
6.3 运行demo文件
修改文件中相应jdbc-url,load-url,username,password,table-name,database-name等参数
注:集群的fe/be的http port和fe的query_port需要能够访问(可以ping一下通不通)
这里我们在服务器起一个线程动态输入数据
nc -lk port
执行demo文件
在服务器起的进程端口窗口输入数据

可以看到已经receive data

然后去数据库查询就可以看到数据已经写入

七、常见问题
7.1 代码运行正常,但查询不到数据
如果代码运行正常且接收到数据,但是写入不成功时请确认当前机器能访问be的http_port端口,这里指能ping通集群show backends显示的ip:port。举个例子:如果一台机器有外网和内网ip,且fe/be的http_port均可通过外网ip:port访问,集群里绑定的ip为内网ip,任务里loadurl写的fe外网ip:http_port,fe会将写入任务转发给be内网ip:port,这时如果ping不通则写入失败。
比如fe的http_port和query_port可以访问,be的http_port不能。load url如果指定fe_ip:http_port,则提交任务后,fe会将任务指向be协调节点,则任务会因为无法连接be的http_port而超时,报错如下:

当然也可以开通fe的query_port和be的http_port的访问权限,在load_url里直接输入be_ip:http_port,不过不建议这样做,因为会将导入压力倾斜到一台be上。
7.2 代码执行报错:Failed to flush batch data to doris
代码执行报错,有报错信息 Failed to flush batch data to doris
//设置列分隔符
.withProperty("sink.properties.column_separator", "\\x01")
//设置行分隔符
.withProperty("sink.properties.row_delimiter", "\\x02")
此类问题常见于数据分隔符选取不对,如数据字段中包含指定分割符,则在导入过程中会解析字段失败,导入不成功,可以修改相应sink部分的分隔符参数,调整后重新运行代码尝试。
如果不清楚文件字段具体有哪些字符不存在可以指定为分割符,也可以将上述两个参数修改为一下参数,让数据以json格式导入。
.withProperty("sink.properties.format", "json")
.withProperty("sink.properties.strip_outer_array", "true")
7.3 部分数据格式不正确,导致批次数据写入全部失败
Flink connector默认导入容忍0错误,如果出现有极少数脏数据导致导入失败,可以设置以下参数容忍失败部分数据导入。
.withProperty("sink.properties. max_filter_ratio ", "0.2")
如 "sink.properties. max_filter_ratio ", "0.2" ,表示可以容忍20%的数据错误,如果单次导入数据中有超过20%的数据导入失败,则该批任务写入不成功,全部失败。