
【详述】版本从2.3.2升级到2.3.4 或者2.4后线上运行的UDAF运行异常
文件是min_by的java实现
MinBy2.java (2.0 KB)
麻烦贴下报错信息和相关的错误截图,谢谢!

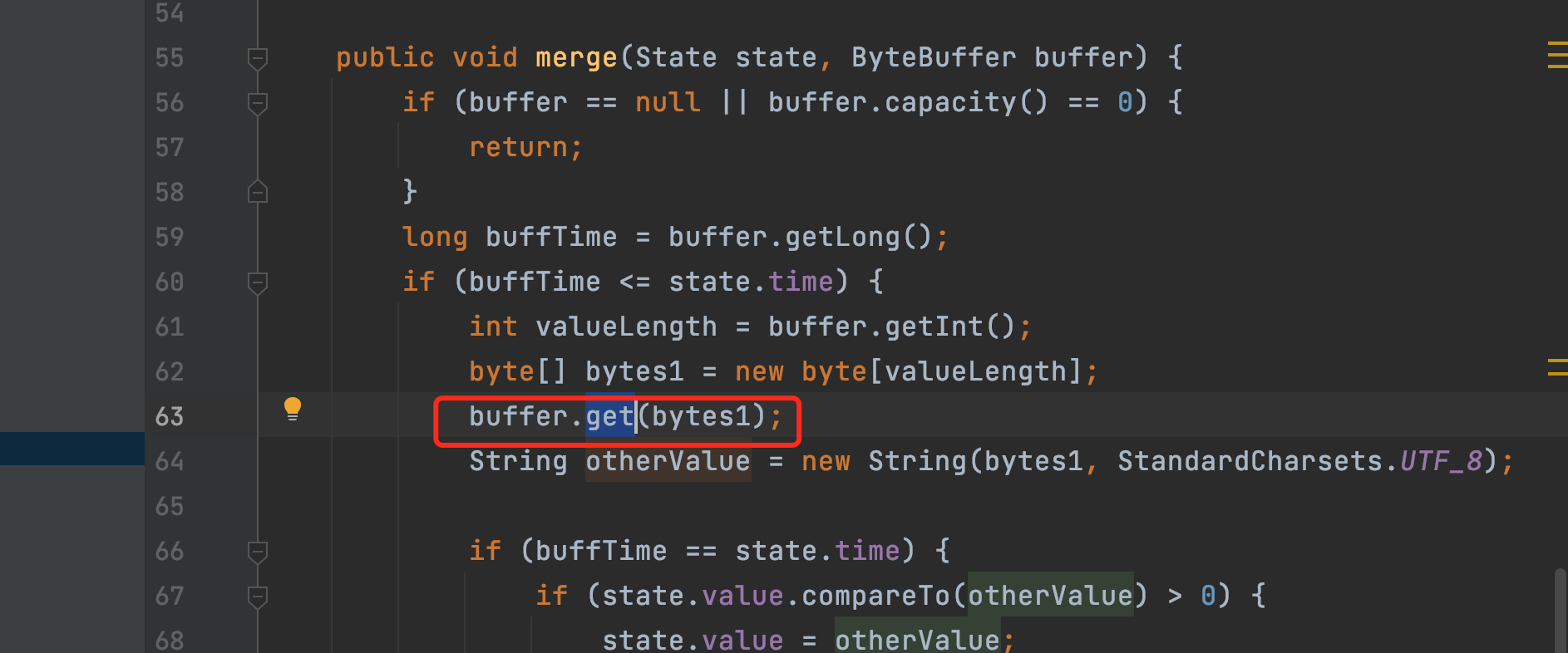
2.3.2的时候是可以运行的对吧
是的 线上是2.3.2 是正常运行的
能简化下最小的复现场景么。比如建表和查询调用函数的sql,我们复现下
把min_by那个merge里面 <= 去了试试,应该是写的不对。低版本是恰好撞上去了,可以运行
那是我们的业务处理逻辑 是必须的判断
集群环境 数据量足够大 任何表都行;
sql: select min_by({vachar_column},{long_column}) from table 就可以
这个是UDF写的问题,得改UDF,参考一下我们提供的example,之前用的<=是不规范的。

我们也碰到了类似问题
看了回复。同样不是很理解这里的<=判断不规范是指什么? 可以具体说一下嘛
这里只是业务逻辑的判断吧,通过比较 buffer 中的bufftime 和原 state 中的time 值,来判断是否要更新后面的取值。
我们在预研starrocks,2.3.2 的版本中 出现了跑udaf 导致be崩溃的问题,看问题在2.4.2 中解决了。但是升级后 出现了这篇同样的问题。麻烦帮忙看一下吧
所有序列化之后的值,在反序列化阶段都需要读出来。比如我某条记录序列化的时候写了10byte,那么我发序列化的时候必须读10byte,否则剩下的内容就会被下一条数据读取
按照您的提示 我们测试下哈 虽然还是有疑问
已经按照你说的做了代码修改:
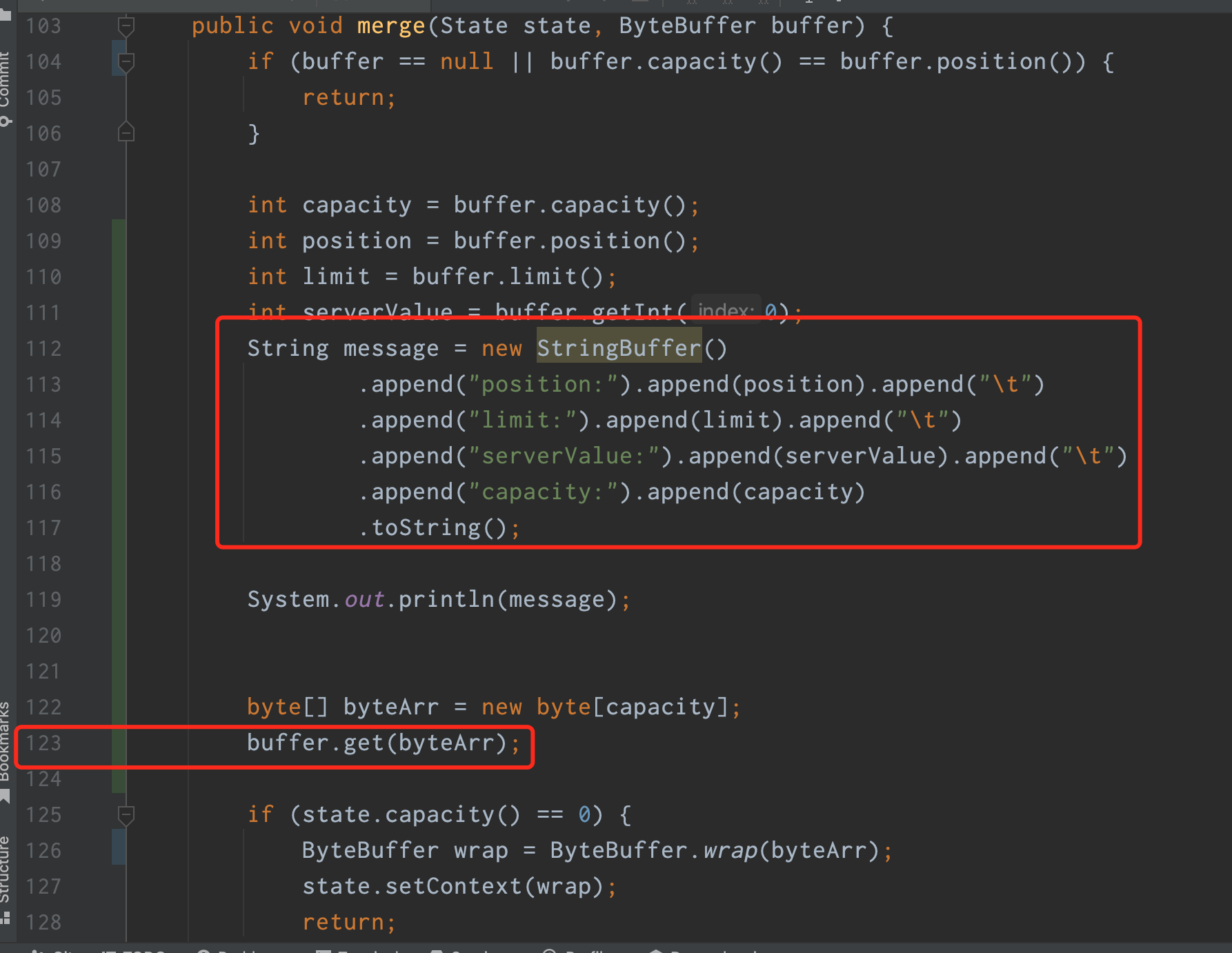
但是其中输出的日志不太明白:
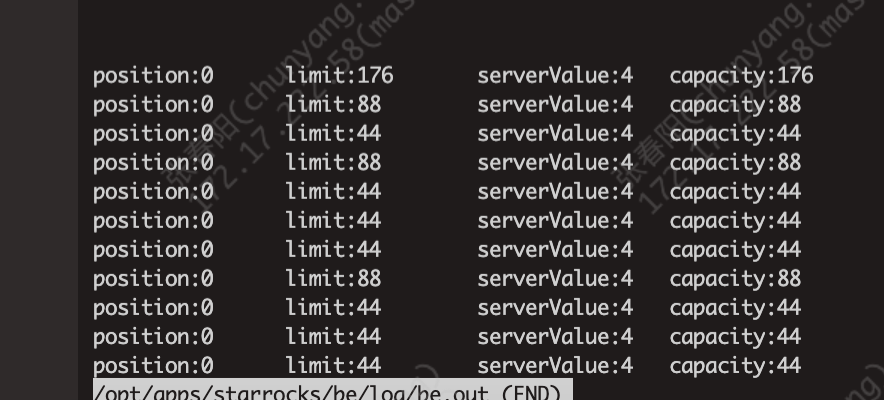
1.同一查询State#serializeLength()返回值是固定的–本例中是44, 为什么会出现capacity成倍上涨的情况呢
2. 对于这种State#serializeLength()返回值是固定的的逻辑,还可以获取buffer中的有效值,但是对于漏斗这种逻辑,怎么实现从buffer中获取有效值呢
3. 104行有 buffer.capacity() == buffer.position()的判断,因为在之前的测试中有发现,会有传入的buffer中有buffer.capacity() == buffer.position()的情况