
【详述】kafka采集数据到分区,有时VisibleVersion特别大,导致这个分区储存特别大,查询这个分区也慢
【背景】kafka采集数据到分区,有时VisibleVersion特别大,导致这个分区储存特别大,查询这个分区也慢,但用hdfs全量采集过来,VisibleVersion小,储存没之前那么大,查询起来不慢,这是什么原因?
【业务影响】
【StarRocks版本】例如:2.3.4
【集群规模】例如:2fe + 6be(fe与be混部)
【机器信息】16核 32线程
看下该表下的所有的分区,是不是存储数据规模不一样,您也帮忙确认下VisibleVersion是否会有变化
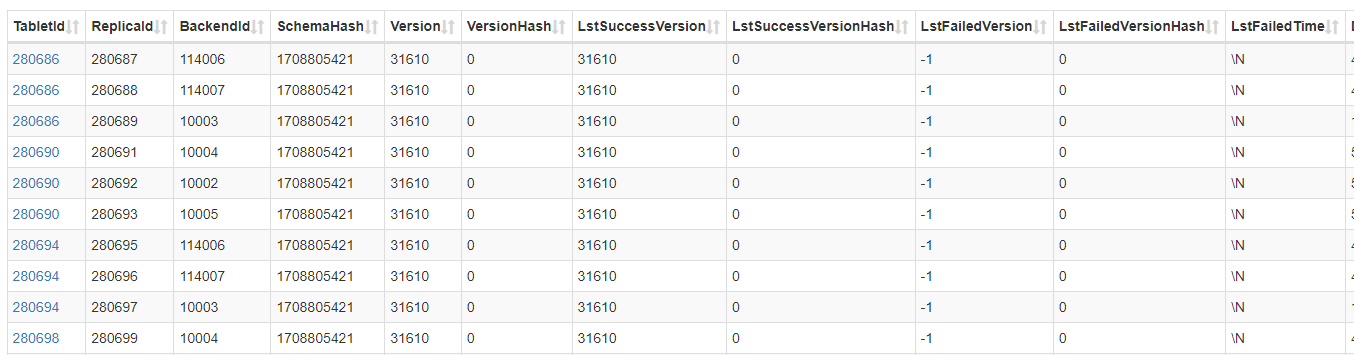

kafka采集的是json格式的,hdfs是ORC的
麻烦show backends;看下
