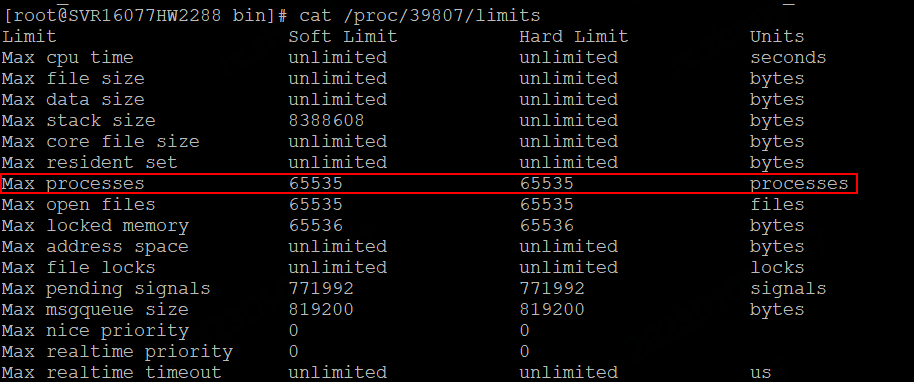
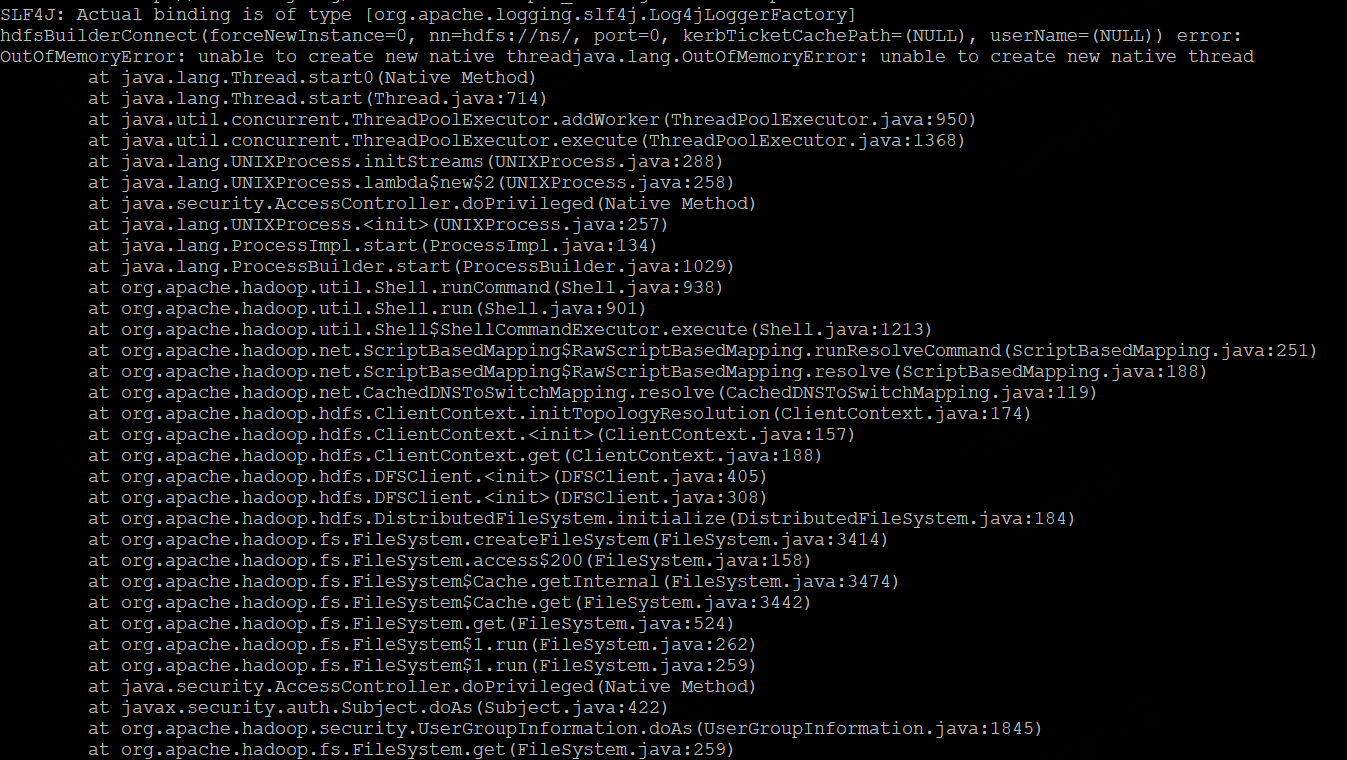
Hive Metastore 相关
问题一描述
- 建表出现:set_ugi() not successful, Likely cause: new client talking to old server. Continuing without it.
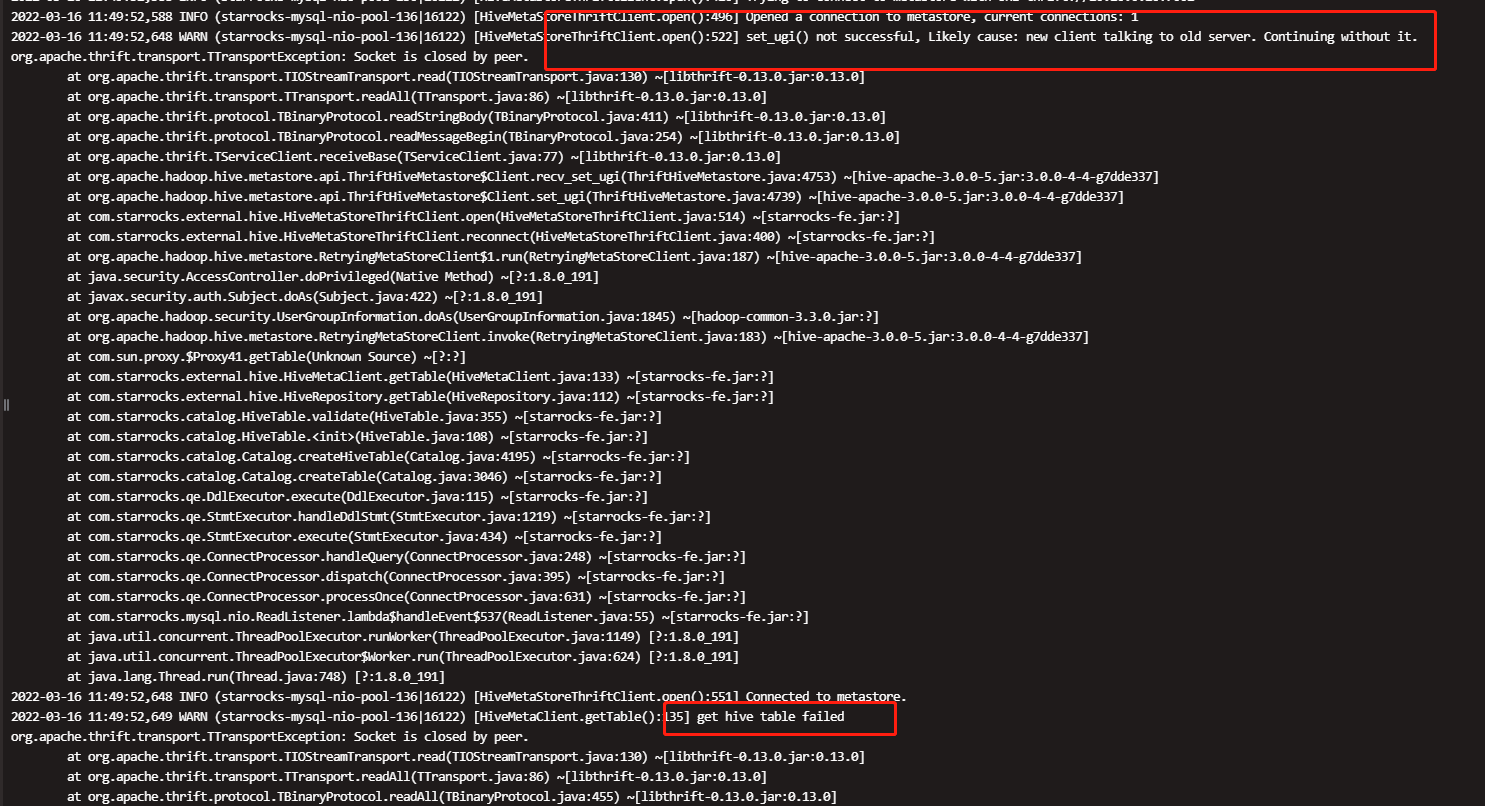
2.get hive table failed org.apache.thrift.transport.TTransportException: Socket is closed by peer.
解决方案
- 确认是否开启了 kerberos 认证
- Kerberos 认证方法:外部表 @ External_table
- Kerberos 配置/日志及调试方法:Kerberos 配置/日志及调试方法
- 如果没有开启 kerberos 认证,可以去检查下hadoop_env.sh的username配置是否正确(要跟 启动hive metastore service的user保持一致 )
- 确认连接的hive metastore 地址是否正确,如连接的地址不正确,也会报这个错误。
- 查看上游是否为华为 MRS 服务;需要 HMS 分支单独适配
- 查看上游是否为 腾讯 TBDS ;需要 tbds 分支单独适配
- k8s环境出现该问题
- echo $USER判断当前环境是否存在,如不存在,需要在fe or be /conf/hadoop_env.sh中设置HADOOP_USER_NAME
- 查看hadoop namenode中core-site.xml是否存在hadoop.proxyuser.***, 如果存在对应用户,需要将HADOOP_USER_NAME设置为该值。
- 如果用户提出trino可以访问hms,可以参考trino hive connector中关于hadoopuser的配置。
- 询问hive metastore版本,可以替换hive_metastore/lib/下面的libthrift为starrocks fe/lib下面的包。
问题二描述
创建外表时出现以下错误(kerberos 场景下)
SQL 错误 [1064] [42000]: get hive table from meta store failed: Unable to instantiate com.starrocks.external.hive.HiveMetaStoreThriftClient
解决方案
- 只需要检查 FE 节点配置,建表只需要 FE 和 Hive / Hudi 通信
- 检查 krb5 是否能正常鉴权。需要加 krb5 debug 参数后在 fe.out 查看
1. JAVA_OPTS="-Dsun.security.krb5.debug=true" - 检查 hive-site.xml 文件
1. 缺少个信息,至少需要 hive-site 中拥有那些字段信息? - 检查 hdfs / core 是否正确
1. 至少 hdfs dfs -ls / 可以查看到数据 - 该问题一般和 “GSS initiate failed” 文件同频率出现
问题三描述
建表出现:Failed to get current notification event id. msg: Internal error processing get current notificationEventId
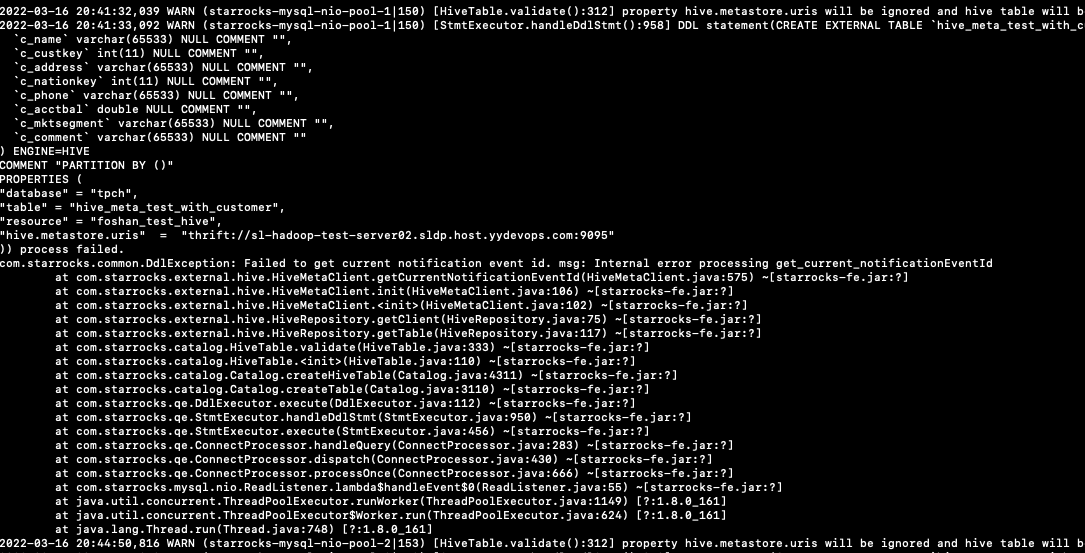
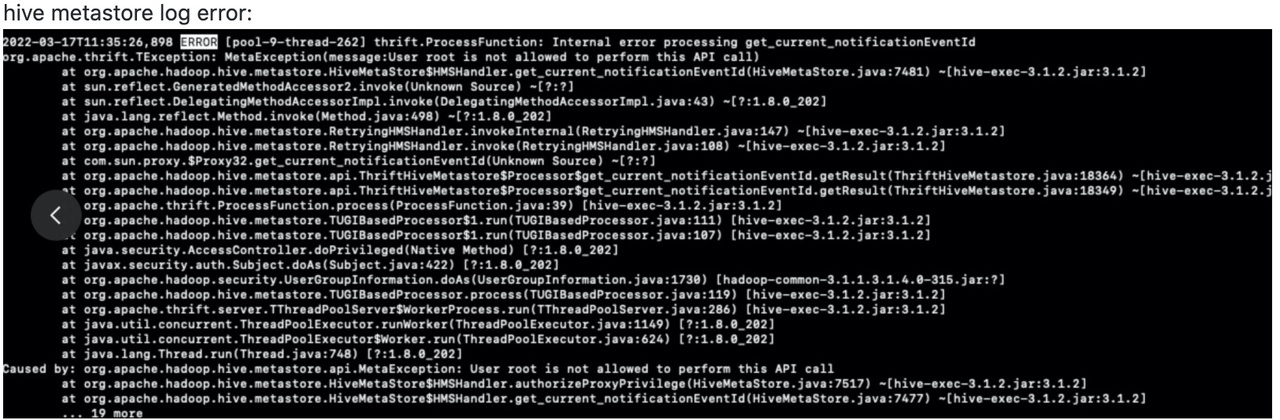
解决方案
- 检查 HMS 日志是否存在
User XX is not allowed to perform this API call类似的日志,如果有的话说明当前启动 StarRocks 的用户没有权限访问 HMS 的相关接口,在fe/conf/hadoop_env.sh 里面配置一下这个 $HADDOP_USER_NAME,比如 hive,具体用户可以配置成hive metastore进程的user.
问题四描述
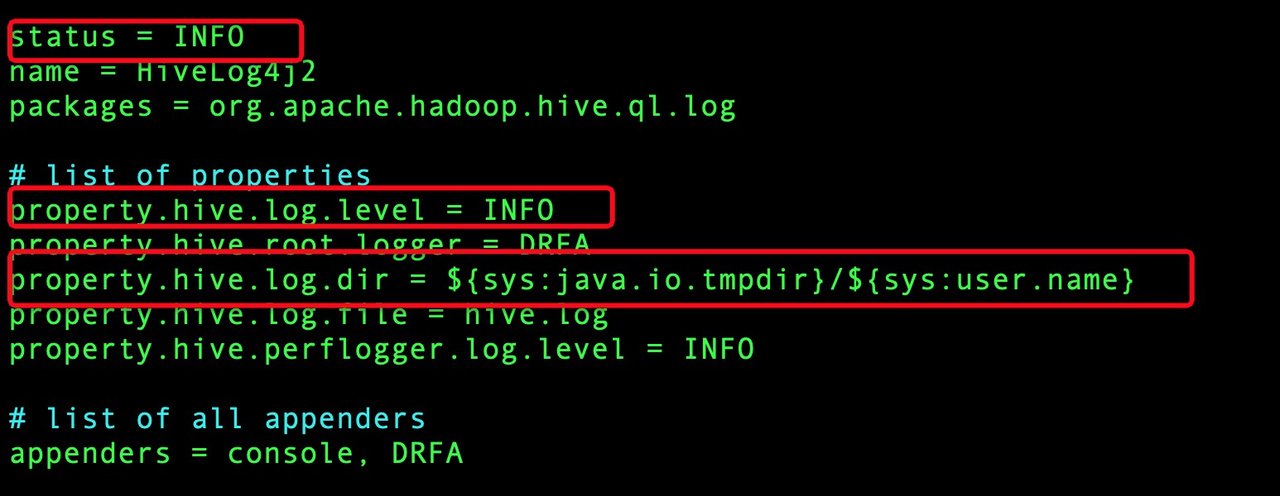
用户查看hive metastore日志没有发现任何错误信息
解决方案
- Hive metastore查看日志需要配置hive/conf/hive-log4j2.properties. 主要修改property.hive.log.dir路径。如需debug信息,可以按照图中红框内进行修改。
问题五描述

用户开启 Fe Hive Metastore元数据增量同步报错,获取Fe日志查看event message 类型(messageFormat)为gzip * 检查 hive 版本
解决方案
- 检查当前 hive 版本下metastore.event.message.factory的默认value
Fe集成的hive-apache-3.0.0-7-sources.jar中默认类型为JSONMessageFactory

客户的默认类型为GzipJSONMessageEncode
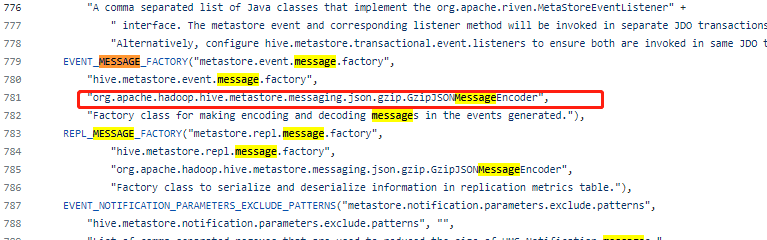
用户手动修改代码的默认Message类型后,报错不复现
问题六描述
通过hive 外表方式查有数据的 hive表会报错:get table default.sr view table test1 partition meta info failed.
解决方案
- 检查所有的 fe和be fe/conf (be/conf)目录下hdfs-site.xmls、core-site.xml文件是否配置了
认证相关
问题一描述
org.apache.thrift.transport.TTransportException: GSS initiate failed
解决方案
- 先确认是否按照 外部表 @ External_table 进行了 kerberos 相关的配置
- 确认 HADOOP_USER_NAME 是否和 hive 配置的一样
- 确保jdk是支持jce扩展,默认不支持AES 256加密解密,可以解压$JAVA_HOME/jre/lib/security/local_policy.jar查看,如果不支持,需要去Oracle官网下载并替换
local_policy.jar和US_export_policy.jar。(这两个文件在$JAVA_HOME/jre/lib/security/),目前我们最新企业版本里面最的jdk是已经添加了这个扩展包
定位方法:在fe/conf/fe.conf文件中的JAVA_OPTS或JAVA_OPTS_FOR_JDK_9加上-Dsun.security.krb5.debug=true或者be/conf/hadoop_env.sh中添加HADOOP_OPTS="$HADOOP_OPTS -Dsun.security.krb5.debug=true",会在fe.out或者be.out中打印debug日志:unsupported key type found the default TGT: 18
问题二描述
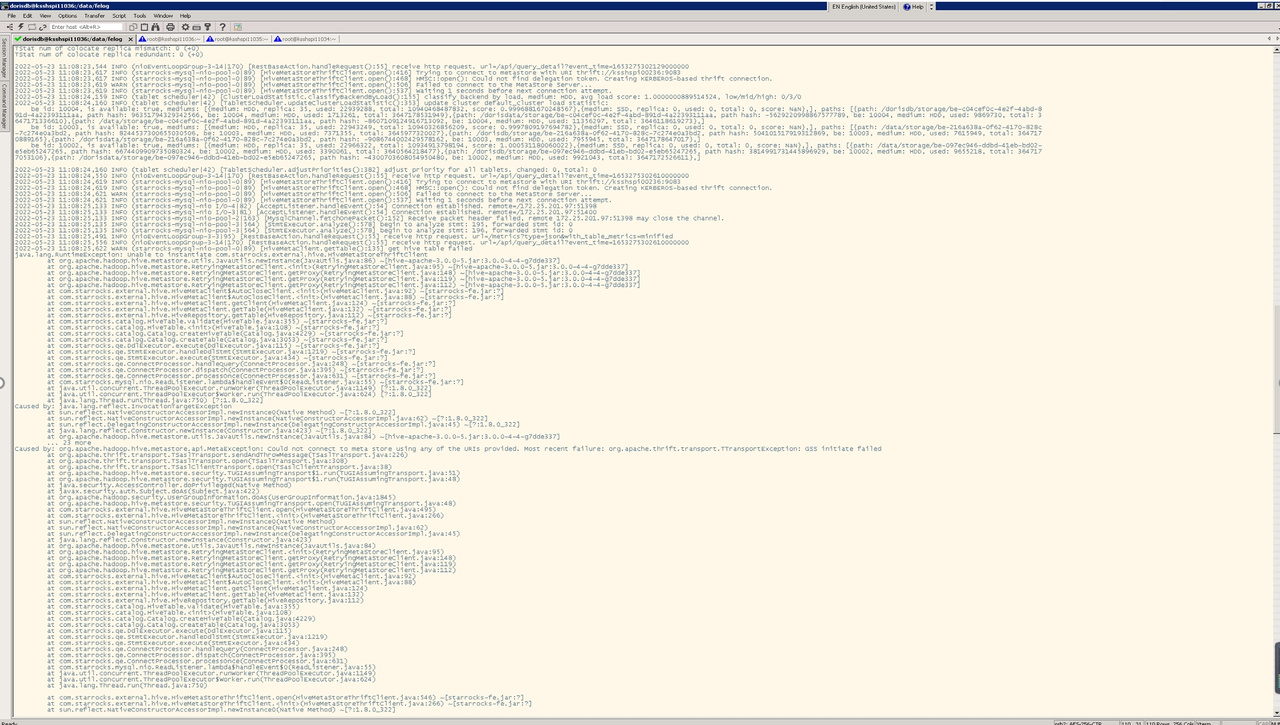
用户遇到kerberos权限认证的问题 1. 执行 klist 检查是否出现
解决方案
- klist
klist: No credentials cache found (ticket cache FILE:/tmp/krb5cc_0)
如果出现,执行 kinit -kt /home/c101/puser.keytab puser
- 打开hive-env.sh
添加如下参数
export HADOOP_OPTS="-Dsun.security.krb5.debug=true ${HADOOP_OPTS}"
检查日志,是否出现 Caused by: GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)
如果出现,将hadoop的core-site文件拷贝到了hive的配置文件夹,并且设置了hadoop.security.auth_to_local为DEFAULT
- 检查 hms 以及 防火墙
- 确保将文件 krb5.conf file 配置到 /etc/ 以及 {AgentInstallDir}/apps/jdk/1.8.0_202/jre/lib/security
- Kerberos 配置/日志及调试方法:Kerberos 配置/日志及调试方法
https://docs.oracle.com/javase/8/docs/technotes/guides/security/jgss/tutorials/KerberosReq.html
问题三描述
开启 FE 组件 “-Dsun.security.krb5.debug=true” 后信息
提示 no tgt,cannot get creds krbexception fail to create credential 63 No service creds
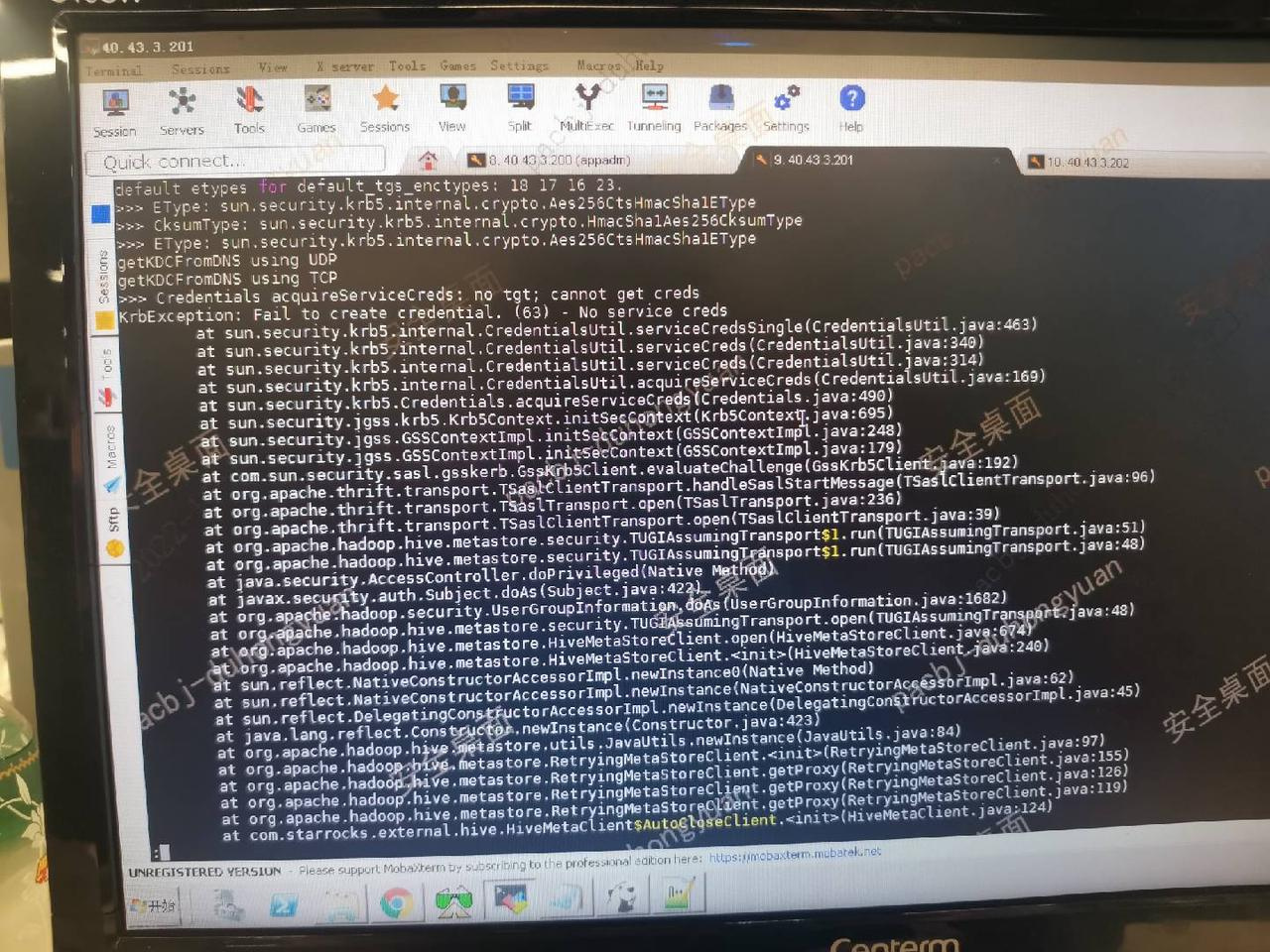
解决方案
查看 -Djava.security.krb5.conf=/root/krb5.conf 信息是否配置正确
比如 -Djava.security.krb5.conf 是否写错
比如 路径是否没有权限读取、路径位置是否正确 等
问题四描述
在外表上查询时,MySQL client 出现 hdfsOpenFile failed: file hdfs://nfsed/xxx/db/table/partiiton/xxx.parquet
BE 节点开启 “-Dsun.security.krb5.debug=true” 信息
在 be.out 文件查看以下内容
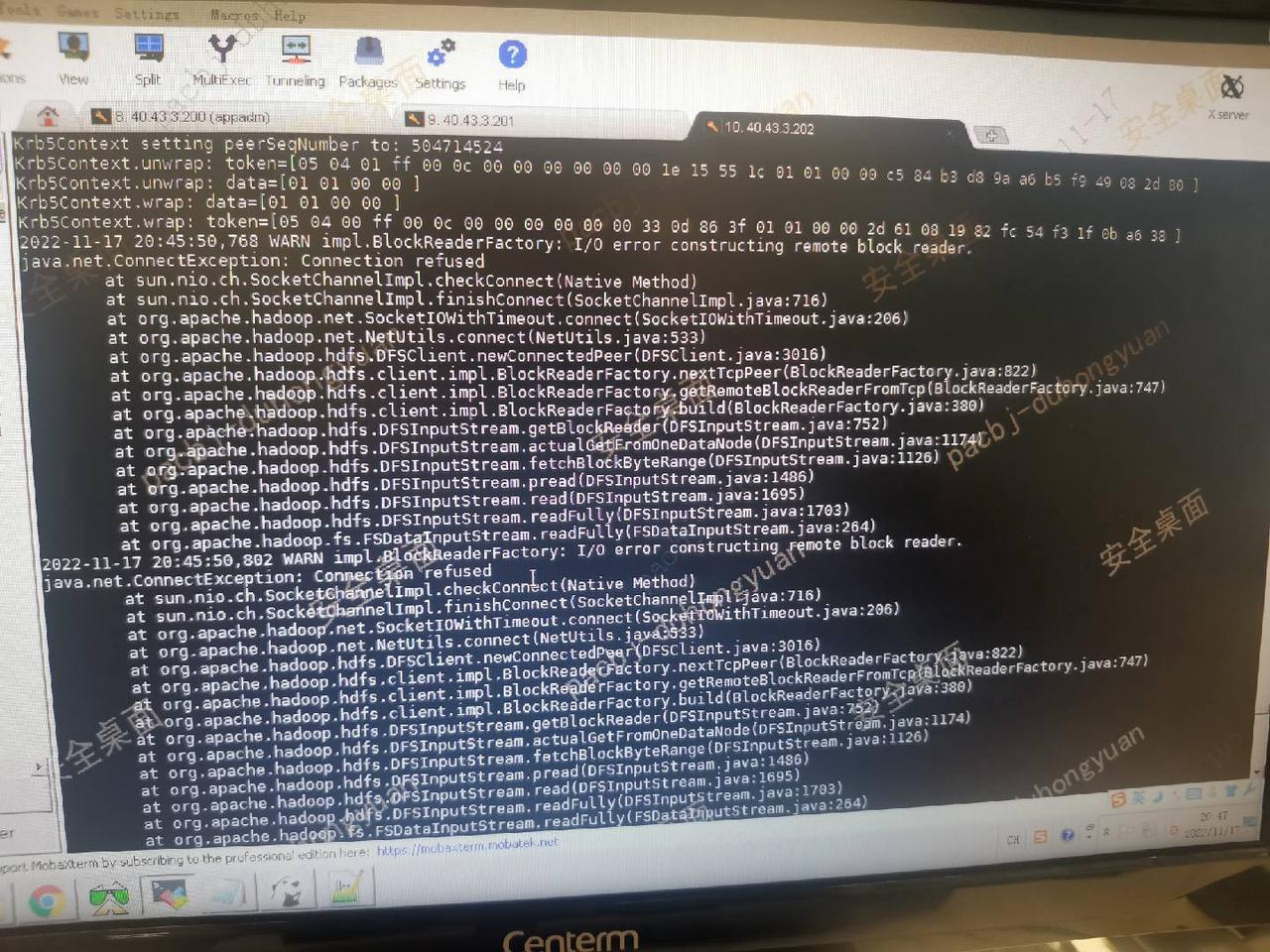

解决方案
- 尝试指定刷新外表元数据
- refresh external table XXX
- refresh external table XXXX partition (“stat_dt=2022-01-01”) 刷新指定分区
- Select * from XXX where stat_dt = “2022-01-01” limit 1
- 如上不行,检查所有 BE 节点的 kerberos 认证步骤是否合理
- Hive / hdfs / core 三个文件
- 读取 krb5 文件的参数
- Klist 票据有效期 和 票据归属系统用户
- 检查 hdfs 中的 nameservice 的主机是否可以解析
- 当多个节点中,有一个节点鉴权不成功时,其他正常的节点也会出现这个错误。
HDFS 相关
问题一描述
访问 HDFS 报 EOF错误
解决方案
- 不管是 be 还是 fe 节点,都检查下 conf/hadoop_env.sh 中 HADOOP_USER_NAME 有没有正确设置,一般是用的环境变量 $USER,可能和 hadoop 的配置不一样
问题二描述
2022-04-20 11:41:39,263 WARN (thrift-server-pool-14 577) [Coordinator.updateFragmentExecStatus():1560] one instance report fail errorCode IO_ERROR fail to hdfsPreadFully file, file=hdfs://xxx/user/hive/warehouse/xxx.db/xxx/dt=2022-04-05/000124_0, error=error=Error(255): Unknown error 255, root_cause=NoSuchMethodError: readFully, query_id=c90779d6-c05b-11ec-817e-0242f07c9722 instance_id=c90779d6-c05b-11ec-817e-0242f07c972c
解决方案
- 确认下 fe和be 的lib文件夹下,hadoop相关的jar包是否存在
- 确认conf/hadoop_env.sh里面,存在 export HADOOP_CLASSPATH=${STARROCKS_HOME}/lib/hadoop/common/ :${STARROCKS_HOME}/lib/hadoop/common/lib/ :${STARROCKS_HOME}/lib/hadoop/hdfs/ :${STARROCKS_HOME}/lib/hadoop/hdfs/lib/
问题三描述
查hive外表报 open file failed (我们默认对hive文件大小 是不限制的 )
解决方案
- 可以通过more hadoop_env.sh检查HADOOP_USER_NAME这个参数是否正确,不正确会导致报错:open file failed
- be节点用户权限不对,需要切换权限
之前有个用户报这个错误,
kerberos部署的时候是给 A 用户授权了
他一直连不上
最后发现,用的是B用户去连的
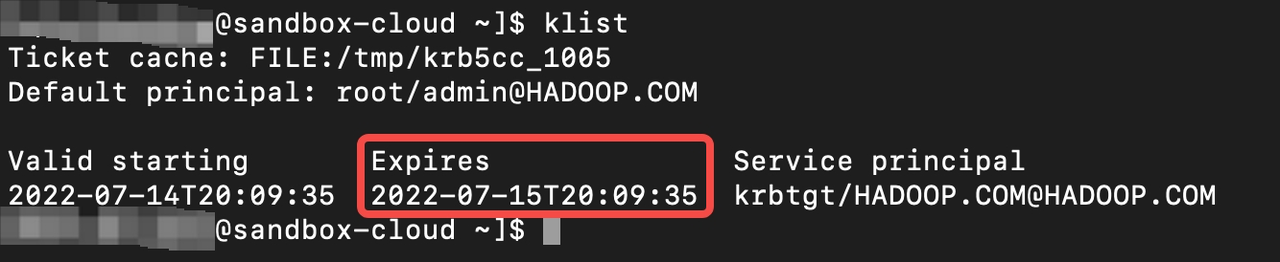
- 检查 be.info 是否有 open file failed关键字
- 检查be.out确认kerberos认证是否过期
S3相关
问题一描述
访问报告“IO error: No response body.”错误
解决方案
- 如果是ec2机器,可以不配置ak/sk以及endpoint,可以使用自带的IAM role进行访问,但是不能配置 AWS_EC2_METADATA_DISABLED
- 如果不是ec2机器,那么必须配置ak/sk/endpoint,可以配置
AWS_EC2_METADATA_DISABLED=true - 检查s3 bucket是否必须SSL访问。
object_storage_access_key_id = xxx
object_storage_secret_access_key = xxx
object_storage_endpoint = http://oss-cn-zhangjiakou-internal.aliyuncs.com
object_storage_max_connection = 102400
问题二描述
报不存在 cosn 文件系统
解决方案
fe的conf下,core-site.xml添加如下配置:
fs.cosn.impl
org.apache.hadoop.fs.s3a.S3AFileSystem
fs.AbstractFileSystem.cosn.impl
org.apache.hadoop.fs.s3a.S3A
性能相关
问题一描述
文件格式为 ORC,HDFS_SCAN 耗时太长,IoCounter 非常大(> 1k)
解决方案
- orc 文件的大小是不是都比较小,几百KB或者几MB
- 可以找一个 orc 文件看看
hive --orcfiledump <orc-hdfs-file>结果,确认 stripe size 是不是都很小,几百KB或者几MB
环境相关
问题一描述

解决方案
- 用户可能jump server来启动be,启动时没有指定JAVA_HOME,需要在bashrc中配置JAVA_HOME,如果用户环境中存在多版本不方便配置在bashrc中,可以在be/bin/start_be.sh中配置JAVA_HOME为绝对路径即可。
问题二描述
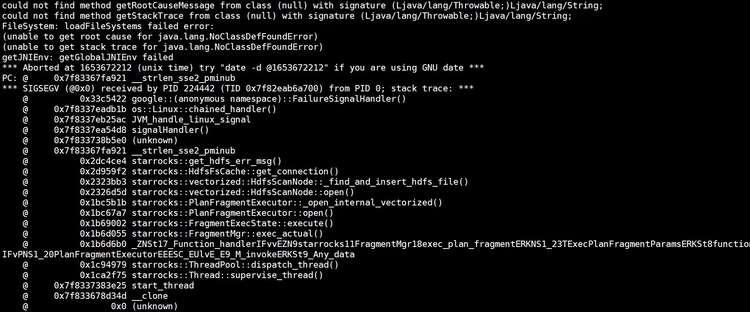
关键词:java.lang.NoClassDefFoundError
解决方案
- JAVA_HOME必须指定为 JDK8 的路径
- 低版本升级高版本可能出现conf/hadoop_env.sh配置不对
- 查看 BE 是否加载了 hadoop class 信息,在 hadoop env 文件内声明
- export HADOOP_CLASSPATH= xxx
- 客户集群升级时没升级conf目录中的文件,但是高版本配置变了导致的问题,例如集群升级:1.17.3升级到2.0.5
问题三描述
BE报错 NoClassDefFoundError: com/amazonaws/AmazonServiceException
FE报错 ClassNotFoundException: Class org.apache.hadoop.fs.s3a.auth.IAMInstanceCredentialsProvider
解决方案
SR 2.0.5
FE报错是因为他们替换了hadoop-aws jar(自带的是3.3.0, 他们的是 3.1.3)
BE报错是因为他们缺少了aws-java-sdk-bundle jar, 可以使用 1.11.1026 这个版本
Broker load相关
问题一描述
Broker load + kerberos 创建任务失败,获取不到 KDC realm 信息 Broker load 创建任务后任务失败,show load 看到以下信息。
JobId: 18019
Label: label123
State: CANCELLED
Progress: ETL:N/A; LOAD:N/A
Type: BROKER
EtlInfo: NULL
TaskInfo: resource:N/A; timeout(s):14400; max_filter_ratio:0.0
ErrorMsg: type:ETL_RUN_FAIL; msg:Broker list path failed. path=hdfs://hacluster/simon_t1/*,broker=TNetworkAddress(hostname:192.168.0.194, port:8000),msg=java.lang.IllegalArgumentException: Can't get Kerberos realm, cause by: Can't get Kerberos realm
CreateTime: 2022-10-26 17:32:59
EtlStartTime: 2022-10-26 17:32:59
EtlFinishTime: 2022-10-26 17:32:59
LoadStartTime: 2022-10-26 17:32:59
LoadFinishTime: 2022-10-26 17:33:00
URL: NULL
JobDetails: {"Unfinished backends":{},"ScannedRows":0,"TaskNumber":0,"All backends":{},"FileNumber":0,"FileSize":0}
3 rows in set (0.00 sec)
解决方案
在 broker 启动脚本第 42 行位置添加以下信息,用于指定 Broker 进程可以读取到 krb5 的配置文件。
黄色部分根据自己实际路径更改
export JAVA_OPTS="-Xmx1024m -Djava.security.krb5.conf=/etc/krb5.conf -Dfile.encoding=UTF-8"
问题二描述
Broker load 导入 HDFS 时使用 * 匹配目录 创建任务时使用了 * 匹配目录下所有文件。
LOAD LABEL hudi_test.label1234561
(
DATA INFILE("hdfs://hacluster/user/hive/warehouse/simon.db/hudi123/*")
INTO TABLE hudi123
FORMAT AS "parquet"
)
WITH BROKER "bname"
(
"hadoop.security.authentication" = "kerberos",
"kerberos_principal" = "all@F0BDED41_321E_4A7D_9E48_152A14FE1E36.COM",
"kerberos_keytab" = "/opt/user.keytab"
);
JobId: 18042
Label: label1234561
State: CANCELLED
Progress: ETL:N/A; LOAD:N/A
Type: BROKER
EtlInfo: NULL
TaskInfo: resource:N/A; timeout(s):14400; max_filter_ratio:0.0
ErrorMsg: type:LOAD_RUN_FAIL; msg:Init parquet reader fail. Invalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.
CreateTime: 2022-10-26 18:19:03
EtlStartTime: 2022-10-26 18:19:04
EtlFinishTime: 2022-10-26 18:19:04
LoadStartTime: 2022-10-26 18:19:04
LoadFinishTime: 2022-10-26 18:19:04
URL: NULL
JobDetails: {"Unfinished backends":{"e7623070-9243-460e-95f2-59fe74b0afc9":[]},"ScannedRows":0,"TaskNumber":1,"All backends":{"e7623070-9243-460e-95f2-59fe74b0afc9":[11001]},"FileNumber":2,"FileSize":434773}
7 rows in set (0.00 sec)
解决方案
- 使用 hdfs dfs -ls / 查看指定目录下是否有隐藏文件
- 星号 * 也会匹配这种隐藏文件
hdfs dfs -ls /user/hive/warehouse/simon.db/hudi123
Found 3 items
drwx------ - all hive 0 2022-10-26 11:26 /user/hive/warehouse/simon.db/hudi123/.hoodie
-rw------- 3 all hive 93 2022-10-26 11:26 /user/hive/warehouse/simon.db/hudi123/.hoodie_partition_metadata
-rw------- 3 all hive 434680 2022-10-26 11:26 /user/hive/warehouse/simon.db/hudi123/0f384463-22ee-4353-9550-6827801c8c48-0_0-5-5_20221026112649.parquet
问题三描述
Broker load + Kerberos 导入时出现 failure to login
Failure to login for principal: krbtgt@HADOOP.com from keytab /appdata/user.keytab javax.security.auth.login.loginexecption: unable to obtain password from user
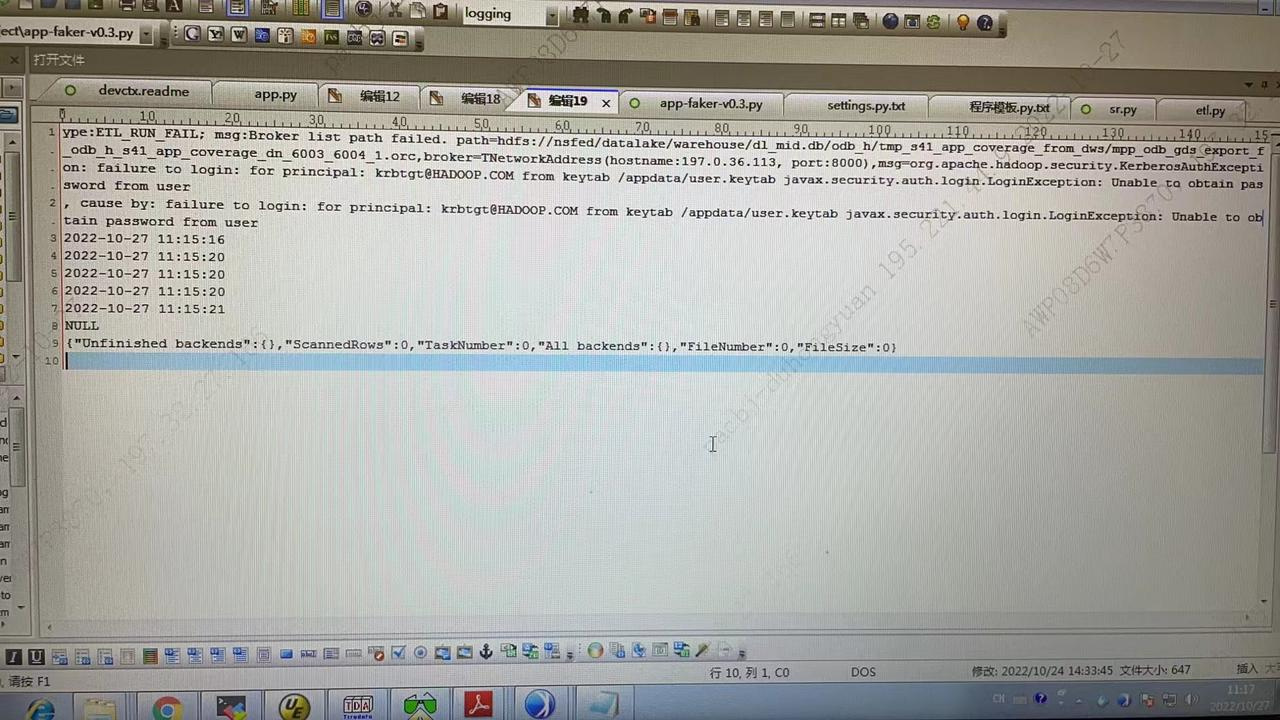
解决方案
- 检查 load borker 任务中的参数是否正确
"hadoop.security.authentication" = "kerberos",
"kerberos_principal" = "all@F0BDED41_321E_4A7D_9E48_152A14FE1E36.COM",
这是用户名,不是主机名;使用 klist -kt user.keytab 可以查看到 用户名,在 default principal: 后面显示
"kerberos_keytab" = "/opt/user.keytab"
这个文件 broker 进程要能有权限读取
问题四描述
Broker 导入 Hudi / Hive 的 parquet 格式数据提示无效的 列名 FE 日志打印如下信息
2022-10-26 19:39:14,838 WARN (loading_load_task_scheduler_pool-5|287) [LoadTask.exec():65] LOAD_JOB=18069, error_msg={Failed to execute load task}
com.starrocks.common.LoadException: Invalid Column Name:abb
at com.starrocks.load.loadv2.LoadLoadingTask.actualExecute(LoadLoadingTask.java:163) ~[starrocks-fe.jar:?]
at com.starrocks.load.loadv2.LoadLoadingTask.executeOnce(LoadLoadingTask.java:135) ~[starrocks-fe.jar:?]
at com.starrocks.load.loadv2.LoadLoadingTask.executeTask(LoadLoadingTask.java:113) ~[starrocks-fe.jar:?]
at com.starrocks.load.loadv2.LoadTask.exec(LoadTask.java:59) [starrocks-fe.jar:?]
at com.starrocks.task.MasterTask.run(MasterTask.java:35) [starrocks-fe.jar:?]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_302]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_302]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_302]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_302]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_302]
解决方案
检查 StarRocks 创建的内表的列名和字段顺序是否与 Hive / Hudi 的表是否一致。
导入时默认要求顺序和字段名一致方可导入