
万物皆数据的时代,各行各业对数据分析架构的要求日益拔高,打破传统的数据湖应需而生。企业得以用更低廉的成本、更完善的 ACID 支持、更实时的方式,导入并存储所有结构化、半结构化和非结构化数据。得益于数据湖良好的伸缩性和灵活性,企业还可适应数据的任何变化,无需对基础设施进行重大更改。
然而,数据湖架构在数据分析上仍面临着许多挑战,于是 解决数据湖限制、结合了数据湖和数据仓库优势的新系统——Lakehouse 开始出现,直接在数据湖的低成本存储上实现与传统数据仓库中类似的数据结构和数据管理功能。
自 2.0 版本,StarRocks 就已积极投入 新一代流批融合的极速 Lakehouse 的建设。如今,用户可通过 StarRocks 进行数据湖分析,享受存算分离、弹性伸缩等前沿技术带来的降本增效。同时,通过 localcache、外表物化视图等特性,用户无需数据导入即可享受到堪比数仓分析的极速性能体验,更加敏捷地从数据湖中获取灵感和洞见,驱动业务增长。
这个冬天,StarRocks 社区推出 极速湖仓分析技术专场 StarRocks Lakehouse Meetup ,旨在帮助开发者深入了解数据湖分析的前沿技术与最佳实践,和开发者共同探讨大数据领域的前沿技术。
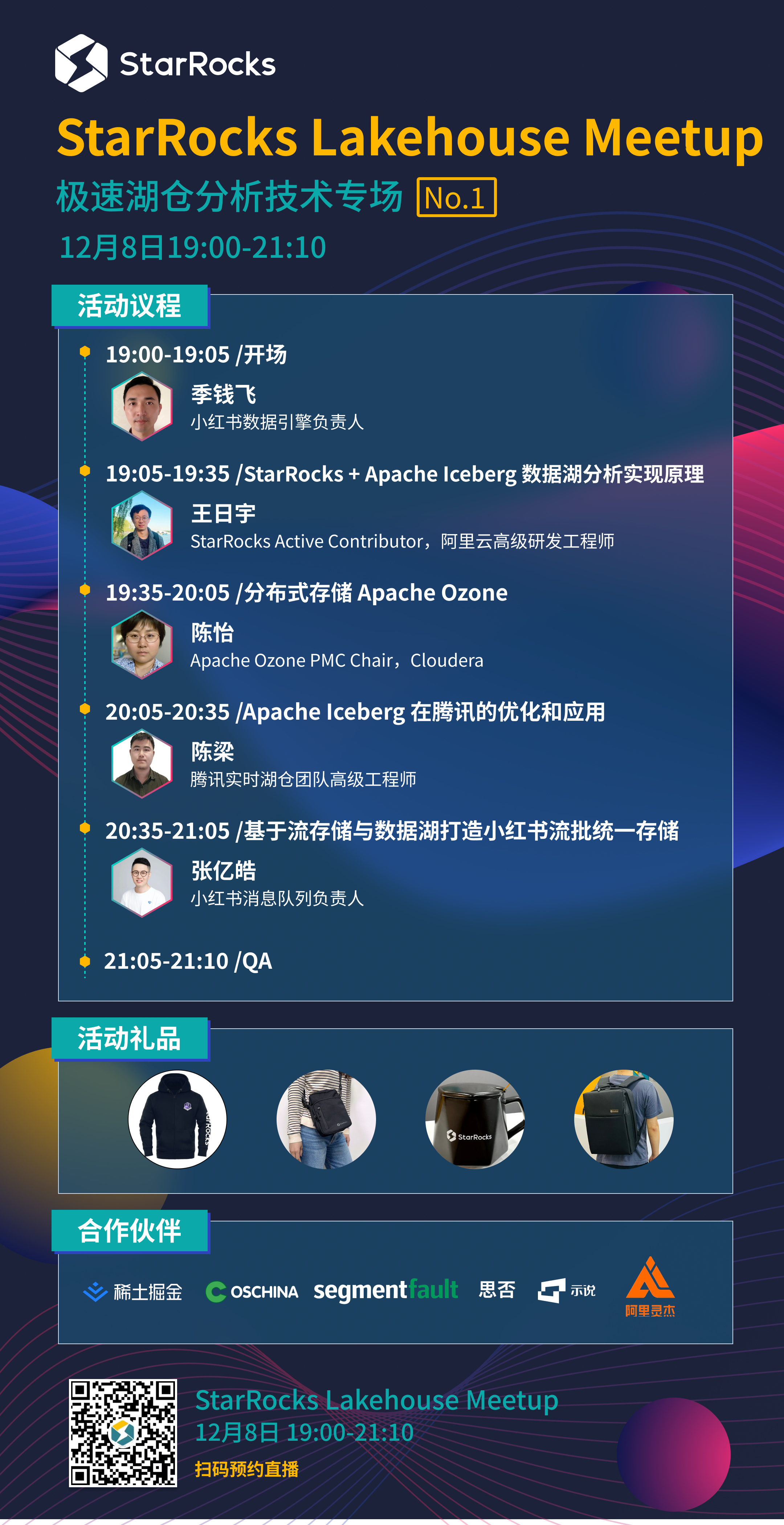
12 月 8 日(周四)19:00 ,StarRocks Lakehouse Meetup 第一期将在线上开讲,届时,来自 阿里云 EMR 团队、Apache Ozone 社区、腾讯实时湖仓团队、小红书数据引擎团队 的技术大咖将现身直播,以 Apache Iceberg 为主线,并对 Apache Ozone 、流批统一存储等技术展开探讨。
更多议程及活动细节可参见下方海报,赶快扫码预约直播吧!
StarRocsk Lakehouse Meetup 第一期直播间 QA 汇总:
王日宇 StarRocks+Apache Iceberg 数据湖分析实现原理:
Q1. Happen Lee:请问 iceberg 的缓存一致性怎么保证呢?是通过 catalog 吗?
A:FE端iceberg目前没有元数据缓存,BE端数据缓存是通过filename + filesize校验来确保唯一。
Q2. Happen Lee:外表如果进行了 schema change 的话, StarRocks 能自动同步吗?
A:可以的
Q3. 非:EMR 的 StarRocks 预计什么时候支持 dataworks
A:现在已经支持了,少部分功能还在完善
Q4.  :EMR starrocks 支持跟 EMR hadoop 部署在同一个集群吗?
:EMR starrocks 支持跟 EMR hadoop 部署在同一个集群吗?
A:可以混部,但不建议
Q5. ky:物化视图也是和 Flink 一样,用 MySQL 的 binlog来实现增量数据计算的是吧?
A:实现思路类似,实时增量物化视图会用binlog,类似这个概念,但不是mysql的binlog,是自研的
Q6. terrence:Iceberg string 没有长度限制, SR 有 1M 限制,外表使用上有限制吗?
A:也有限制的,未来我们会考虑放开
Q7. 浪里白侠:Hudi 外表是否可以通过 hudi 本身元数据访问,非 hive metastore
A:目前不可以,需要同步到 metastore
Q8. Gavin Huang:物化视图支持主键表了吗?
A:支持了。另外外表也支持物化视图了,预计2.5版本会发
陈怡 Apache Ozone:
Q1. 亮亮:Ozone 中的元数据节点的HA是如何实现的,需要像 HDFS 那样外挂 zookeeper 吗?
A:Ozone 的元数据节点HA利用RAFT协议实现,RAFT协议包含了节点间的健康检查和选主等功能,所以Ozone不再需要依赖ZK。
陈梁 Apache Iceberg 在腾讯的优化和应用:
Q1. Heng:二级索引 index的方案合入 iceberg 社区了么?
A:我们正在整合cbo stats指标并和社区puffin 融合, index这块只是其中一部分, 相对完备之后,会考虑往社区提proposal
Q2. 叫我 Jeff 啊:能否基于 Iceberg 解决数仓领域拉链表的问题呢?有无相关的应用案例
A:有的,我们主要是借助mergeiInto + timetravel的能力来实现的
张亿皓 小红书基于流存储与数据湖打造流批统一存储:
Q1. Shenhuayu:实时湖仓链路是从湖到 SR 吗?
不是的,StarRocks是直接对接湖的catalog,直接读iceberg数据的,不需要做数据同步
Q2. 1 文不值:流批的读有统一的 SDK 或 KPI 吗?
统一的API现在还没有,我们后面是考虑利用flink的流批一体功能,通过类似hybrid source的方式来统一读取流批数据