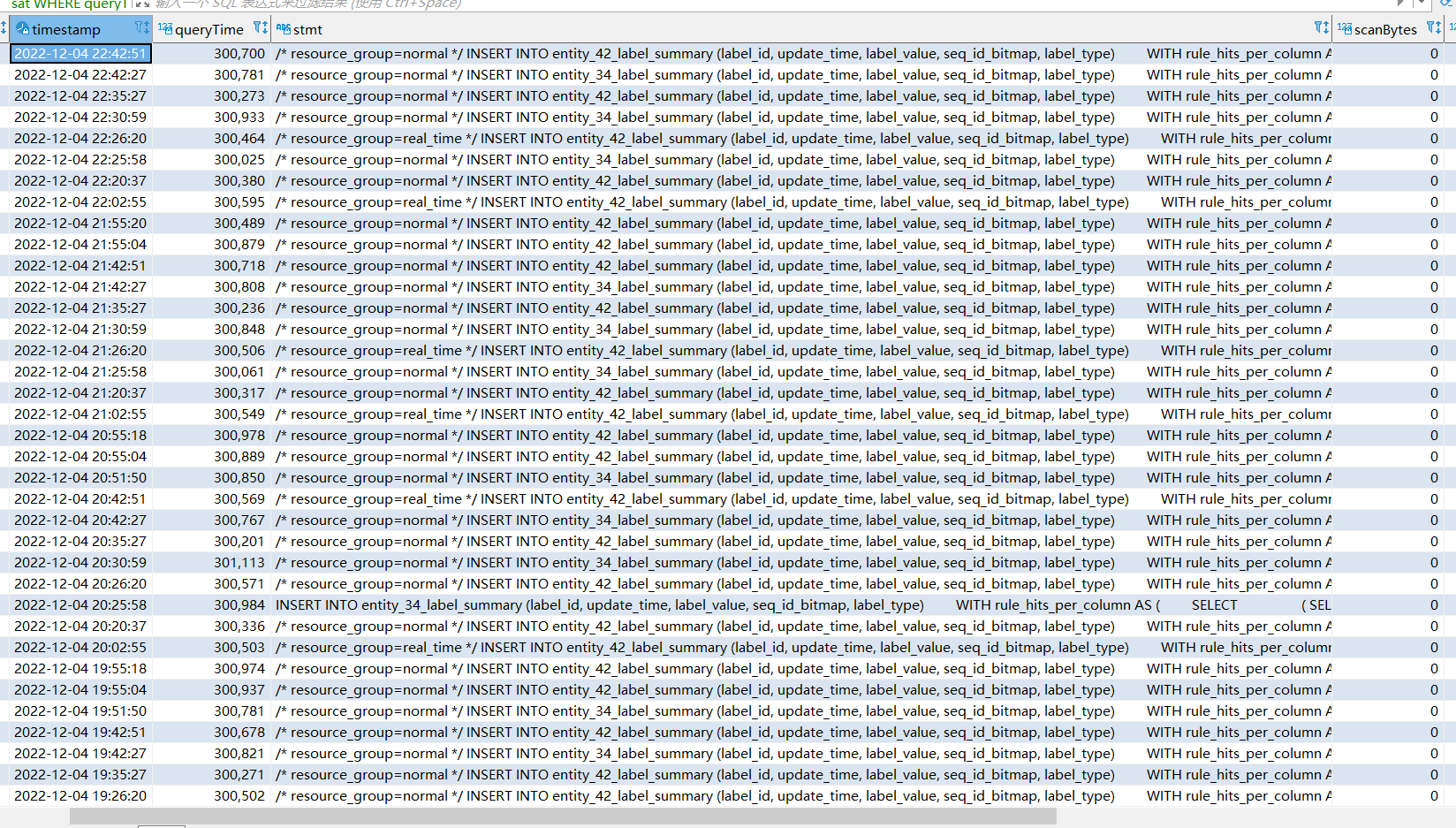
【详述】大量insert into select超时,排查问题时筛选出一些其中的select执行,发现执行时间也都是几秒中,而且数据量也不大。请问怎么去定位问题原因
【背景】
【业务影响】
【StarRocks版本】例如:2.3.3
【集群规模】例如:3fe(3 follower)+5be(fe与be分部)
【机器信息】3fe:4核16G;5be:8核32G
【附件】
-审计日志
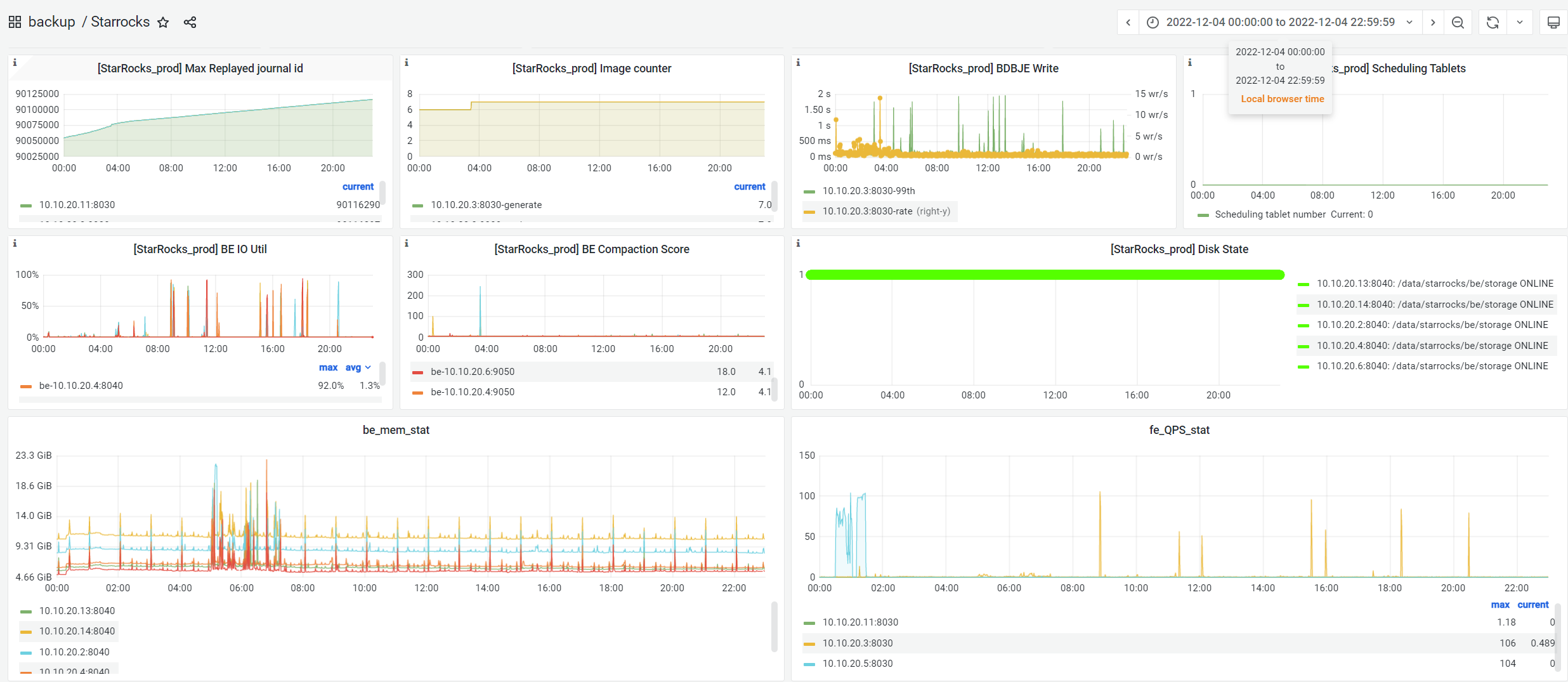
-Grafana监控情况

【详述】大量insert into select超时,排查问题时筛选出一些其中的select执行,发现执行时间也都是几秒中,而且数据量也不大。请问怎么去定位问题原因
【背景】
【业务影响】
【StarRocks版本】例如:2.3.3
【集群规模】例如:3fe(3 follower)+5be(fe与be分部)
【机器信息】3fe:4核16G;5be:8核32G
【附件】
-审计日志
您可根据queryid去fe master看下有什么异常信息,然后从fe.log找一下txnid, 再grep txnid be.log 看下具体有什么错误信息
fe master下的fe.warn.log里有大量这个日志,请问是什么原因?
WARN (Connect-Scheduler-Check-Timer-0|13) [ConnectContext.kill():499] kill timeout query, 10.100.0.72:34904, kill connection: false
WARN (Connect-Scheduler-Check-Timer-0|13) [ConnectContext.checkTimeout():533] kill query timeout, remote: 10.100.0.72:43372, query timeout: 300
是超过query_timeout 系统自动kill查询。query_timeout可以调大一些试试
好的 
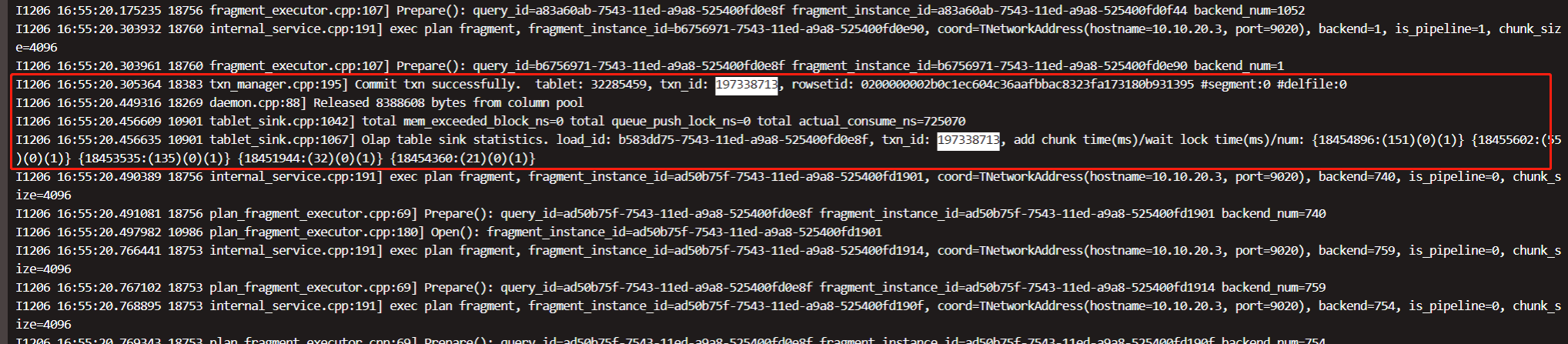
一条插入超时的sql,在fe.log中找到对应txn_id,然后去be.INFO中找对应的信息。
Olap table sink statistics. load_id: b583dd75-7543-11ed-a9a8-525400fd0e8f, txn_id: 197338713, add chunk time(ms)/wait lock time(ms)/num: {18454896:(151)(0)(1)} {18455602:(55)(0)(1)} {18453535:(135)(0)(1)} {18451944:(32)(0)(1)} {18454360:(21)(0)(1)}
提示kill connection: false,实际上还是没有杀死连接是么
当时大量insert超时是因为程序里有个无脑重试insert操作,应该是导致库锁住了。修复后问题有明显解决。