
StarRocks 2.4版本的metric信息有部分变化,这里基于官方提供的模板改造了一版适用于2.4的“伪汉化”模板,供大家测试。新模板的变化有:
1)调整两处内存参数,使可以正常获取2.4版本的内存指标;
2)删除所有测试中发现值始终为0的疑似废弃的指标项并调整布局;
3)调整Create Rollup指标项为Schema Change指标,因原来的SC项无法获取到值;
4)指标名称保持英文,指标说明则按照测试的结果以及逻辑推测进行了尽可能详细的中文释义(鼠标移至指标栏左上角叹号处即可查看)。
Json模板下载地址:
StarRocks-Overview-24-zh_cn-RC3.json (163.6 KB)
TODO1:确认指标描述正确,且各项指标的中文说明能够“见文知意”。
TODO2:调研并添加其他有价值的监控项,例如资源组、主键模型Compaction等。
各指标项释义整理:

-
Cluster Number:监控的StarRocks集群数。
-
Frontends Status:FE节点状态,挂掉的FE会显示为其他颜色的点。如果所有FE都是存活状态,则所有点都应为亮绿色。
-
Backends Status:BE节点状态,挂掉的BE会展示为其他颜色的点。如果所有的BE状态正常,所有的点都会是亮绿色。

-
Cluster FE JVM Heap Stat:StarRocks集群各个FE的JVM堆内存使用百分比。
-
Cluster BE CPU ldle:每个StarRocks集群的BE CPU“空闲”情况。注意:Idle是“空闲”的意思。
-
Cluster BE Mem Stat:每个StarRocks集群的BE内存使用情况概览。
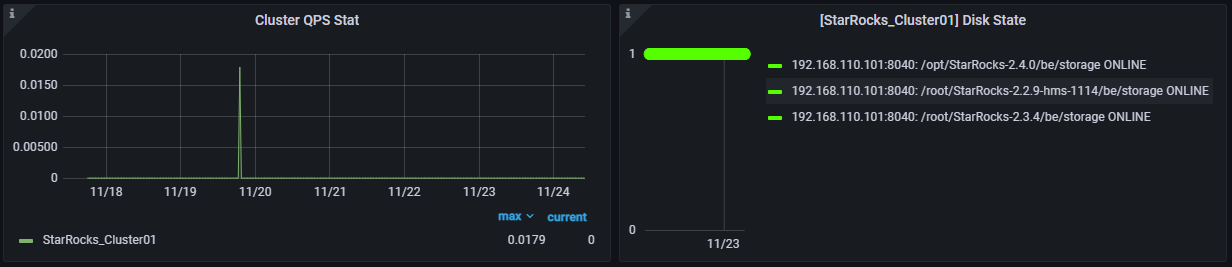
-
Cluster QPS Stat:按集群分组的QPS统计信息。每个集群的QPS是在所有FE处理的所有查询请求数的总和。
-
Disk Stat:磁盘状态。绿色点表示该磁盘处于联机状态。红点表示该磁盘处于离线状态,处理离线状态的磁盘表示可能磁盘损坏,需要运维修复或者更换磁盘进行处理。

-
FE Node:总的FE节点数。
-
FE Alive:当前正常的FE节点数。若集群状态正常,则该值应等于总的FE节点数。
-
BE Node:集群中BE的节点总数。
-
BE Alive:当前集群中正常存活的BE节点数,如果这个数量和BE Node的数量不一致说明集群中有掉线的BE节点,需要去查看处理。
-
Used Capacity:当前所有BE合计使用的磁盘空间。
-
Total Capacity:所有BE存储目录所在磁盘的合计容量。注意:该指标仅表示磁盘容量大小,不表示可用空间。

-
Max Replayed Journal Id:StarRocks FE的最大重放元数据日志ID。正常Leader的journal id最大,其他非Leader FE节点的值基本保持一致,且会略小于Leader节点的值。如果有FE节点的journal id值和其他节点差别特别大,说明这个节点元数据版本太旧,访问该节点查询时数据会存在不一致的风险。这种情况下可以将该节点从集群中删除,然后再作为一个新的FE节点加入进来。
-
Image Counter:该项为StarRocks Leader FE元数据image生成计数器,同时也是Leader节点将元数据镜像成功推送到其他非Leader节点的计数器。这两项指标会以合理的时间间隔增加,且通常它们应该相等。
-
BDBJE Writer:BDBJE写入情况,正常都是毫秒级别,如果出现秒级的写入速度就需要警惕,严重的元数据写入延迟可能会引起写入错误。通常高延迟的情况可能是磁盘性能较弱,此时建议为FE元数据目录更换性能更优的磁盘。在StarRocks中,使用BDBJE完成元数据操作日志的持久化、FE高可用等功能。左侧Y轴显示99th写入延迟,右侧的Y轴显示日志每秒写入次数。
-
Scheduling Tablets:正在进行调度任务的Tablet数量。这些Tablet可能处于Recovery或Balance的过程中。
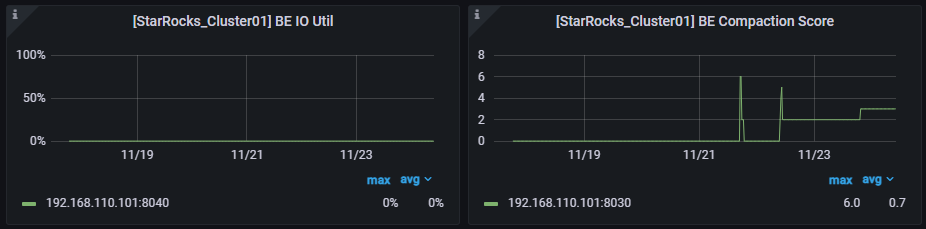
-
BE IO Util:各个BE节点的磁盘IO使用率。
-
BE Compaction Score:各个BE节点的Compaction Score值。通常该值需要维持在100以内,而在大部分批量导入或低频导入场景下,该值通常为10-20或者更低。如果该值过高,不仅会影响导入,还会影响集群的查询性能,此时我们就需要及时的降低导入频率。

-
RPS:各个FE的每秒请求数。这里的请求包括发送到FE的所有请求。
-
QPS:各个FE的每秒查询数。查询仅包括Select请求。
-
99th Latency:各个FE的99th查询延迟情况。99th Percentile Latency:处理速度最快的99%的操作中,最长的延迟时间,单位为毫秒。例如该指标的值为10毫秒,表示99%的请求可以在10毫秒内得到处理。

-
Query Percentile:左Y轴表示每个FE的75th到99.9th查询延迟的情况。右侧Y轴表示每分钟的查询速率。
-
Query Error:左Y轴表示累计错误查询次数。右侧Y轴表示每分钟的错误查询率。通常,错误查询率应为0。
-
Connections:各个FE当前的连接数。

-
Broker Load Job:已完成的Broker Load作业数。
-
Insert Load Job: 已完成的Insert导入任务数。
-
Load Submit:导入作业提交数和完成数的计数器。如果是Routine Load导入,则两条线显示为并行。此外,右Y轴显示每小时导入作业的提交速率。
-
Schema Change Job:正在进行的Schema Change任务数。

-
Txn Begin/Success on FE:显示FE中事务开始和成功的数量和速度。
-
Txn Failed/Reject on FE:显示FE中失败的事务请求,包括被拒绝的请求和失败的事务请求。
-
Publish Task on BE:BE中Publish Task请求总数和错误率。

-
FE JVM Heap:指定FE的JVM堆内存使用情况。左Y轴显示已使用堆内存及使用最大堆内存,右Y轴显示使用的百分比。
-
JVM Non Heap:指定FE的JVM非堆内存使用情况。左Y轴显示“已使用/提交”的非堆内存大小。
-
JVM Direct Buffer:指定FE的JVM直接缓冲区使用情况。左Y轴显示已用/容量直接缓冲区大小。
-
JVM Threads:FE JVM线程数。

-
JVM Young:指定FE的JVM Young Generation内存占用。左Y轴显示已使用/最大Young Generation内存大小。右Y轴显示使用的百分比。
-
JVM Old:指定FE的JVM Old Generation内存占用。左Y轴显示已使用/最大Old Generation内存大小。右Y轴显示使用的百分比。通常,使用百分比应小于80%。
-
JVM Young GC:指定FE的JVM Young GC统计信息。左Y轴显示Young GC的次数。右Y轴显示每个Young GC的耗时。
-
JVM Old GC:指定FE的Full GC状态展示。左Y轴显示Full GC的次数。右Y轴显示每个Full GC的耗时。

-
BE CPU Idle:BE CPU的空闲状态,值越小表示CPU越繁忙。注意:Idle是“空闲”的意思。
-
BE Mem:各个BE节点的内存使用情况。

-
Net Send/Receive Bytes:除IO外的所有设备的网络发送(左Y轴)/接收(右Y轴)的字节速率。
-
Disk Usage:各BE节点存储目录的磁盘空间使用率。
-
Tablet Distribution:每个BE节点上的Tablet分布情况。原则上分布是均衡的,如果差别特别大,就需要去分析原因。

-
BE FD Count:BE的文件描述符(File Descriptor)使用情况。左侧Y轴显示BE使用的FD数量。右侧Y轴显示系统对每个进程的FD软限制数。备注:文件描述符通过ulimit -n进行配置。
-
BE Thread Num:各BE进程的线程数。
-
Disk IO Util:磁盘IO使用率。该值越高表示I/O越繁忙。备注:当集群配置多块磁盘时,当前该值为多块磁盘IO的平均值。

-
Base Compaction:BE的Base Compaction速率。右侧Y轴表示Base Compaction涉及数据的累计字节数。
-
Compaction Cumulate:BE的Cumulative Compaction速率。右Y轴表示累计的Cumulative Compaction数据字节数。

-
BE Scan Bytes:BE的数据量扫描速率。该参数表示处理查询请求时的数据读取速率。
-
BE Scan Rows:BE的数据行扫描速率。该参数表示处理查询请求时的数据行读取速率。

-
Tablet Meta Write:左侧Y轴表示保存在RocksDB中的tablet元数据的写入速率。右侧Y轴表示每次写入操作的持续时间。
-
Tablet Meta Read:左侧Y轴表示读取RocksDB中的tablet元数据的速率。右侧Y轴表示每次读取操作的持续时间。

-
Tablets Report:左Y轴表示Tablets Report任务的失败率,通常应为0。右Y轴表示所有BE中Tablets Report任务的总数。备注:BE每60秒向FE汇报所有Tablet的信息,来让FE获取BE中Tablet的健康状态等信息。
-
Single Tablet Report:左Y轴表示单独的Tablet Report任务的失败率,通常应为0。右Y轴表示所有BE中单独的Tablet Report任务的总数。备注:单独的Tablet上报任务包括Schema Change任务等。
-
Finish Task Report:左Y轴表示Task Report任务的失败率,通常应为0。右Y轴表示所有BE中完成上报任务的Tablet总数。

-
Base Compaction Task:左Y轴表示Base Compaction任务的失败率,通常应为0。右Y轴表示所有BE中生产的Base Compaction任务总数。
-
Cumulative Compaction Task:左Y轴表示Cumulative Compaction任务的失败率,通常应为0。右Y轴表示所有BE中生产的Cumulative Compaction任务总数。
-
Delete:左Y轴表示Delete任务的失败率,通常应为0。右Y轴表示所有BE中Delete任务涉及的tablet总数。

-
Schema Change:左Y轴表示创建Schema Change任务的失败率,通常应为0。右Y轴表示所有BE中创建Schema Change时涉及Tablet的总数。(该项使用的原来的Create Rollup指标)
-
Create Tablet:左Y轴表示创建Tablet任务的失败率,通常应为0。右Y轴表示所有BE中创建Tablet任务涉及的Tablet总数。
-
Clone:左Y轴表示Clone任务的失败率,通常应为0。右Y轴表示所有BE中Clone任务涉及的Tablet总数。
