SR版本2.4.0
3BE 16c * 64G
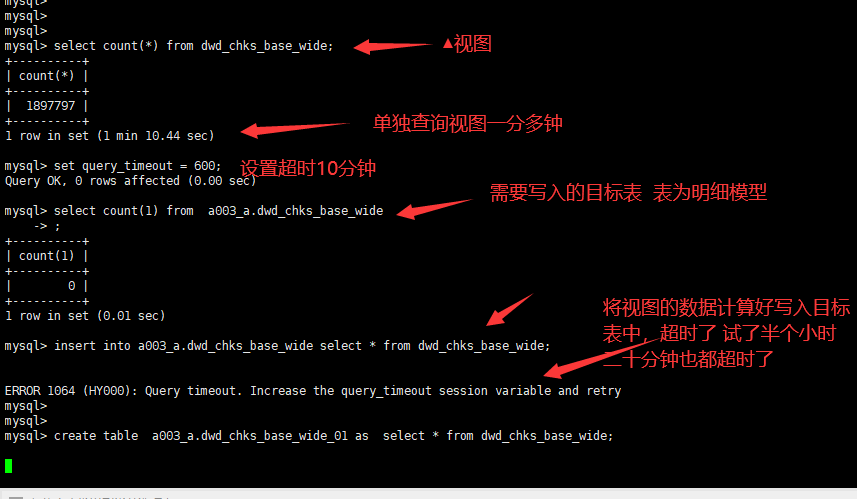
写入目标表为明细模型表
信息描述
这是运行的profile:
profile.txt (125.7 KB)
这是运行过程中be 内存信息:
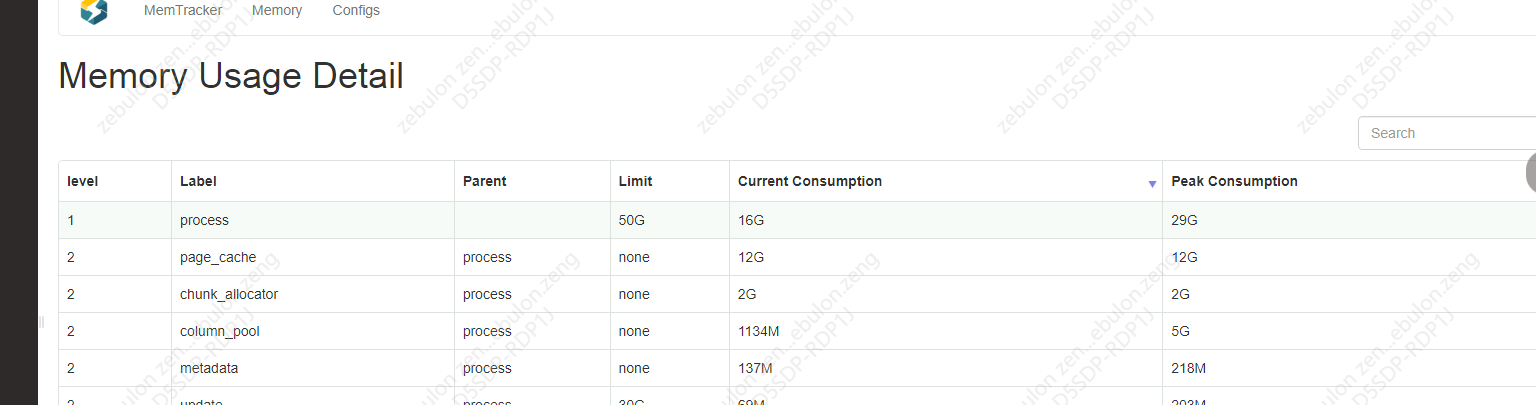
节点io情况
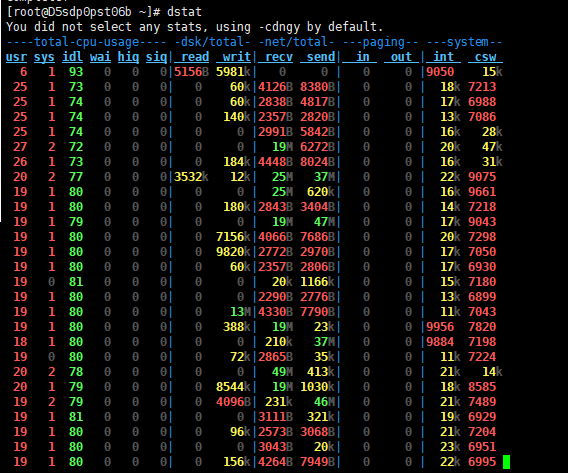
其中be进程cpu在200%左右(16core)
整体资源都处于空闲状态
这是视图sql:
view.sql (23.1 KB)

SR版本2.4.0
3BE 16c * 64G
写入目标表为明细模型表
信息描述
这是视图sql:
view.sql (23.1 KB)
请问下写入的表是什么模型的呢?
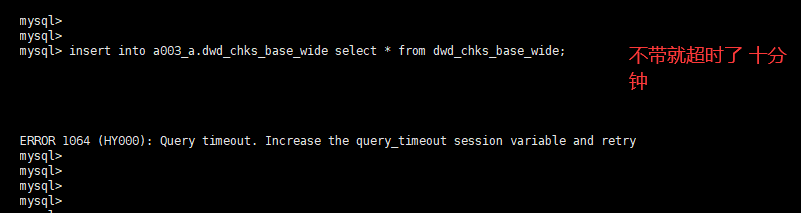
写入是明细模型,基于视图直接create as来创建的
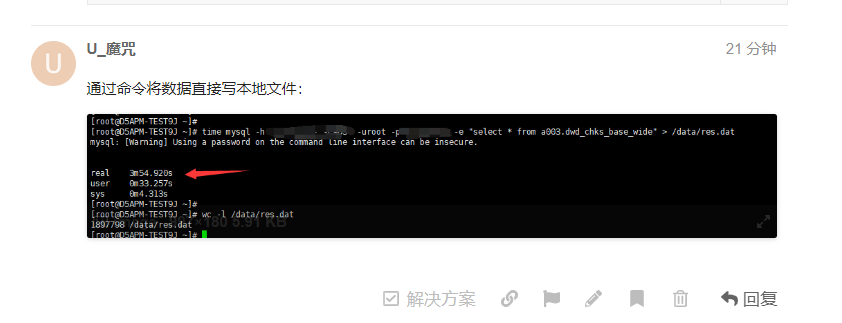
可以试下select * 查询需要多长时间么?count(*) 跟查询数据逻辑不太一样。有很多优化。
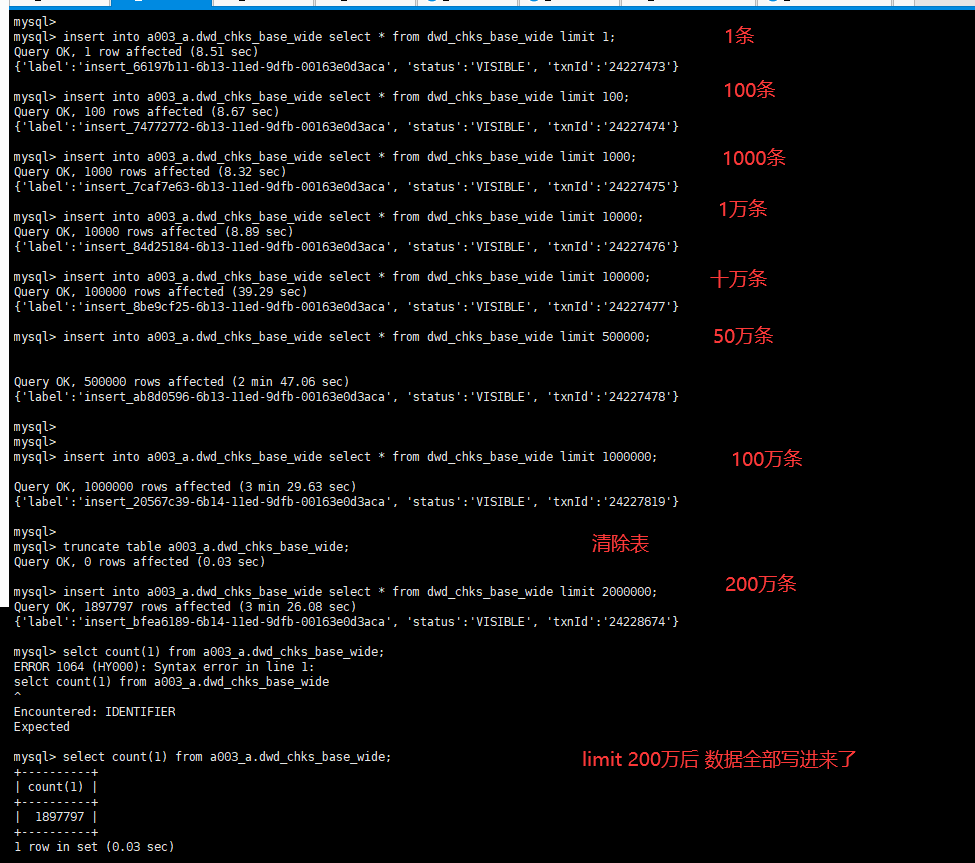
可以试下 limit 1 ,100 ,10000 导入。我们看下效率
可以看下新表的bucket数是多少。看下是不是这个的原因
嗯嗯,这个确实有点问题。我们后续改进下。
目前可以先加一些 很大的 limit 来规避下。
好的,麻烦了,如果后面有fix麻烦提供下,我们持续跟进下,我们现在也还在离线预研中,新版本出来可以优先升级
hi,方便提供下view查询的profile么?
大佬 这个问题2.4.2还没修复么?有计划哪个版本处理么?
3.3.1版本修复了么