【详述】问题详细描述
单表查询想要达到秒级返回
【背景】做过哪些操作?
添加过索引,创建了物化视图
【业务影响】
【StarRocks版本】例如:2.4.1
【集群规模】例如:3fe(1 follower+2observer)+18be
【机器信息】CPU虚拟核/内存/网卡,例如:
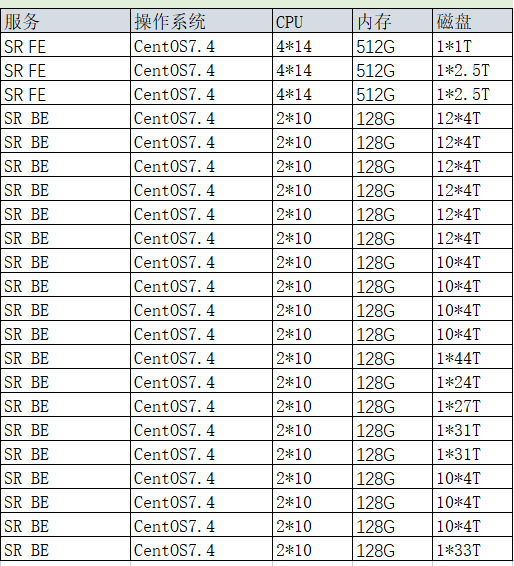
【附件】
- Profile信息
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
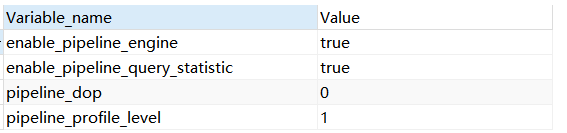
10 - pipeline是否开启:show variables like ‘%pipeline%’;
- 执行计划:explain costs + sql
plan.txt (20.4 KB) - be节点cpu和内存使用率截图
建表语句:
建表语句.txt (12.7 KB)
数据量:3893973473
query_profile.txt (45.3 KB)