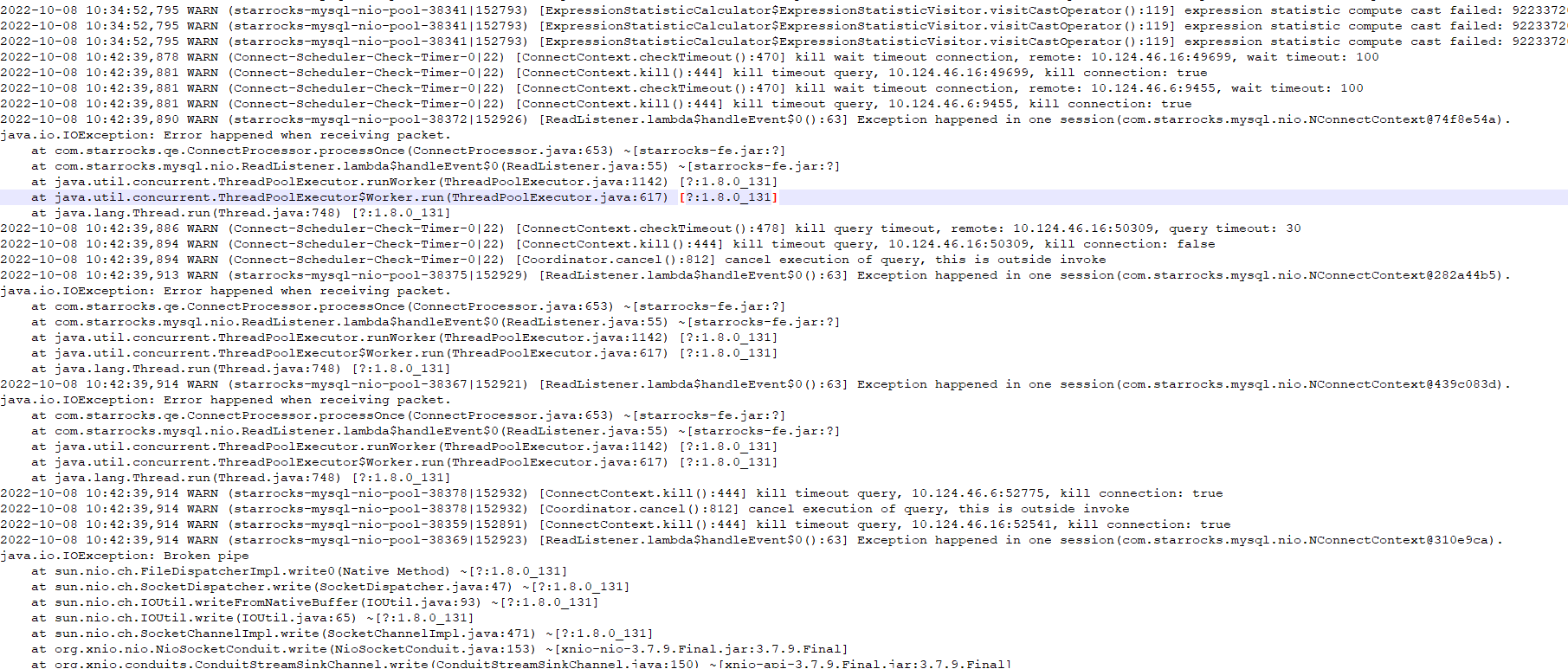
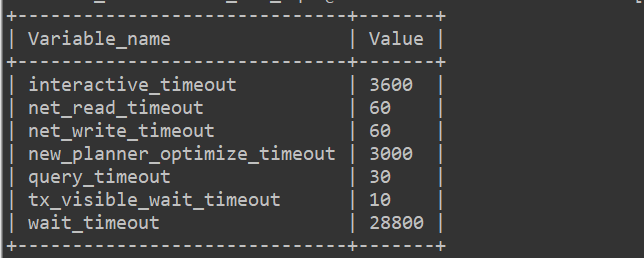
【详述】
fe节点2022-10-08 10点35分到42分 异常重启,想知道重启原因
【背景】做过哪些操作?:未知
【业务影响】:暂无
【StarRocks版本】:2.0.9
【集群规模】例如:6fe(3 follower+3observer)+5be(fe与be混部)
【机器信息】:16C/64G/万兆
【附件】
- fe.warn.log/be.warn.log/相应截图
fe.warn.log (8.2 MB)
- 慢查询:
- Profile信息
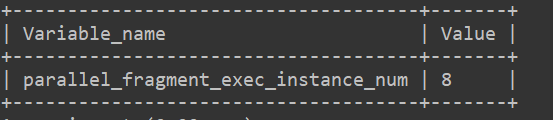
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
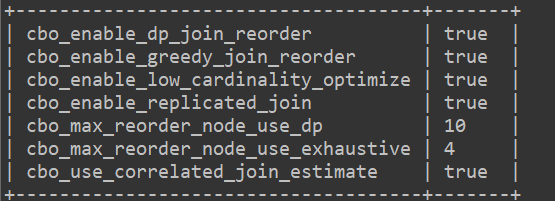
- cbo是否开启:show variables like ‘%cbo%’;
- be节点cpu和内存使用率截图