
【详述】问题详细描述
不知道为啥 java写了个分词的功能,注册为starrocks udf函数,跑3千条
跑了小三分钟,但是在idea上跑100万条,大概八十秒就跑完了,完全一样的代码
【背景】做过哪些操作?
【业务影响】
【StarRocks版本】2.3.0
【集群规模】例如:3fe(1 follower+2observer)+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【附件】
- fe.warn.log/be.warn.log/相应截图
代码
HotWordUDF.java (2.5 KB)
测试mian
Test.java (1.4 KB)
查询截图
idea上跑的java 100w条
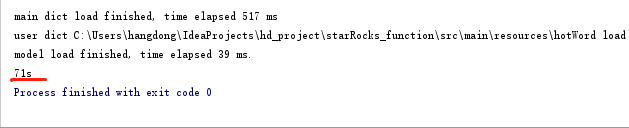
starrocks udf 3000条
- 慢查询:
- Profile信息
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
- cbo是否开启:show variables like ‘%cbo%’;
- be节点cpu和内存使用率截图