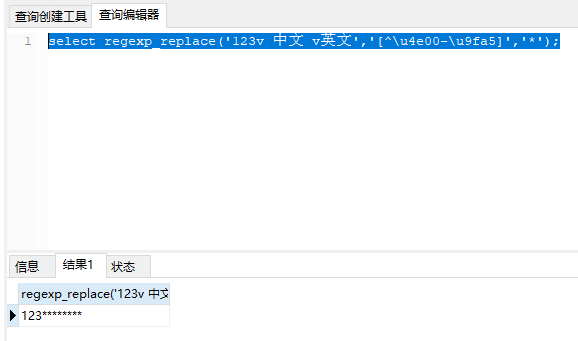
- 这样写 where not
regexp(mid,"^[\u4e00-\u9fa5]+$");
会报这个错:Invalid regex expression: ^[\u4e00-\u9fa5]+$2a96-11ed-8d06-02422cd2fb0a: ‘\u’ at index 2 not supported in a character class.
2.这样写 regexp(mid,"^[\u4e00-\u9fa5]+$");
没办法只匹配中文
所以请教下sr的正则有什么办法只匹配中文呢?