【详述】
查询逻辑是将三张表,
- item_basic(约2000万条)
- record_basic(约130万条)
- report_summary(约1000条)
联结,并通过过滤条件筛选出一定量数据后,进行聚合。

由于业务逻辑的需求,对数据按时间进行分区,遇到如下现象,
- 在相同数据量、相同条件参数的情况下,向多个分区(按照时间分区)的表查询的耗时,大于向单分区(未按照时间分区)的表查询(e.g. 137ms VS 88ms);
- 对按时间分区的表进行的查询,SQL加上了分区键的查询条件,但是耗时上依旧比单分区的多(e.g. 125ms VS 88ms);
- 添加了分区键查询条件的查询,其执行计划中未找到分区键过滤对应的部分。
有如下问题想咨询,
- 单分区查询反而快是否是符合预期的?
- Profile的文件中内容过多
- 如何理解
Active对应的耗时数据,什么时候可以串行累加?什么时候是并行的? - 怎么快速找到瓶颈,并且和查询计划对应上?
- 如何理解
【StarRocks版本】例如:2.2.1
【集群规模】例如:1 FE + 3 BEs(fe与be混部)
【附件】
- 单分区表 - EXPLAIN (6.6 KB)
- 单分区表 - Profile (156.7 KB)
- 按时间分区表 - EXPLAIN (6.7 KB)
- 按时间分区表 - Profile (433.8 KB)
- 按时间分区且带有分区键条件子查询 - EXPLAIN (8.9 KB)
- 按时间分区且带有分区键条件子查询 -Profile (538.4 KB)
- 并行度:8
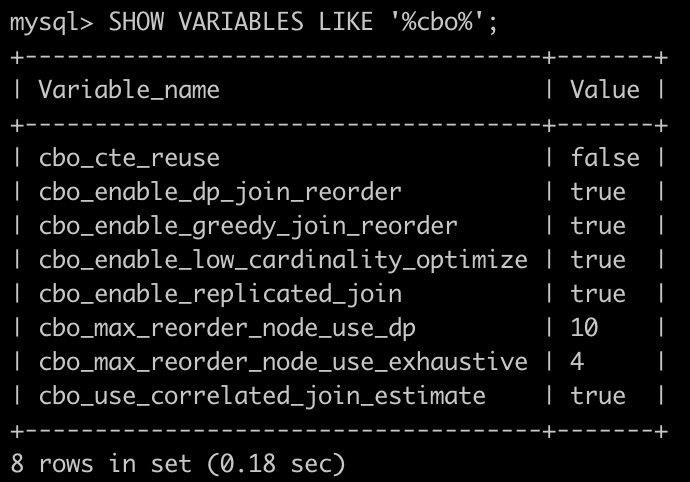
- cbo是否开启