
-
需求
对一张实时写入的按天分区的Starrocks表,获取最新的2000条数据,分100页,每页20条数据。(数据无主键,不能按天裁剪,如果做了时间过滤,过滤时间段内正好没数据,就影响产品功能) -
实现SQL
以ssb的lineorder表(6亿数据)为例(真实业务场景下,随着天数的增加,数据量也会一至增加的,数据保存180天,流量数据,整体量会比较大。)
后端使用orm框架生成的sql(会返回2000条数据):
select * from ssb.lineorder order by lo_orderkey desc limit 1880 offset 2000;
标准sql:
select * from ssb.lineorder order by lo_orderkey desc limit 1880, 20; -
两个sql的响应都比较慢
-
对比
ES分页使用search_after(使用默认生成的_id+时间),深分页秒级响应
CK第一次查询也比较慢,第二次很快。
-
一些想法
针对这个需求,sr在执行类似sql时,因为数据是按时间分区的,能否先取到有数据的最新分区,然后取出limit条数据(不够再取前面的分区),避免全量排序,降低响应时延。




请问下这几个表的总数据量是同等量级的吗?
您好,刚确认了下,ck这边的数据量是千万级别的(dbgen -v -s 10 -T l),当我使用同样6亿+的数据时,ck执行分页的语句很慢,甚至跑不出结果(dbgen -v -s 100 -T l)。这种分页查询慢的需求在SR这边有优化方案不?
有优化方案,可以Sort排序列后再延迟物化来解决
您能给个例子吗? 感谢
当前可以先通过改写SQL解决。后序,我们会被这个延迟物化机制做到StarRocks里,不用改写,也可以加速了
如何改写SQL?可以给个demo吗?
select * from tablex order by k1 limit 10;
这个改成 select * from tablex where k1 in (select k1 from tablex order by k1 limit 10);
谢谢,试了下查询速率提升很多,这个k1感觉需要是唯一键,但当前数据没有主键…
你直接写第一列就行,不用主键
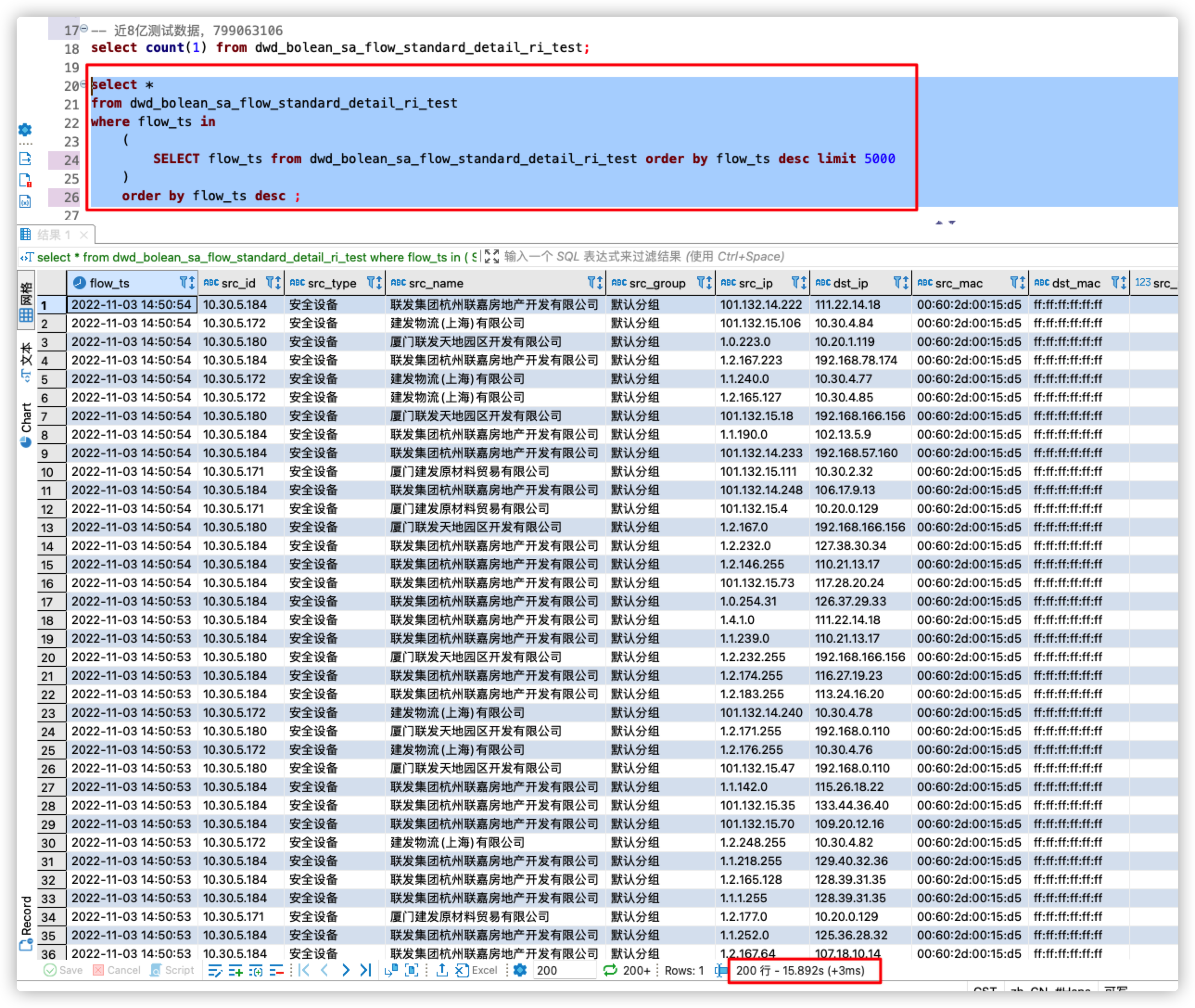
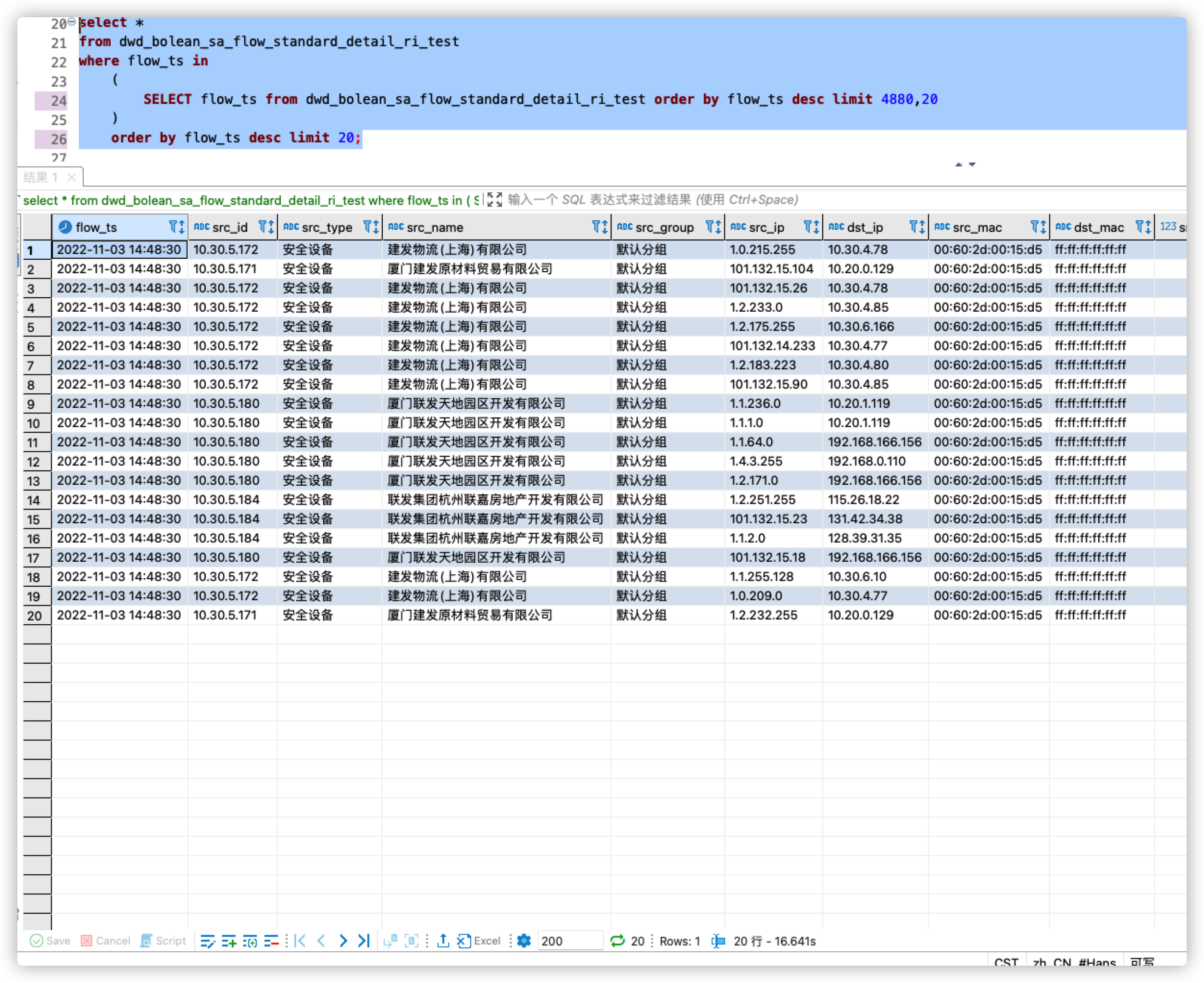
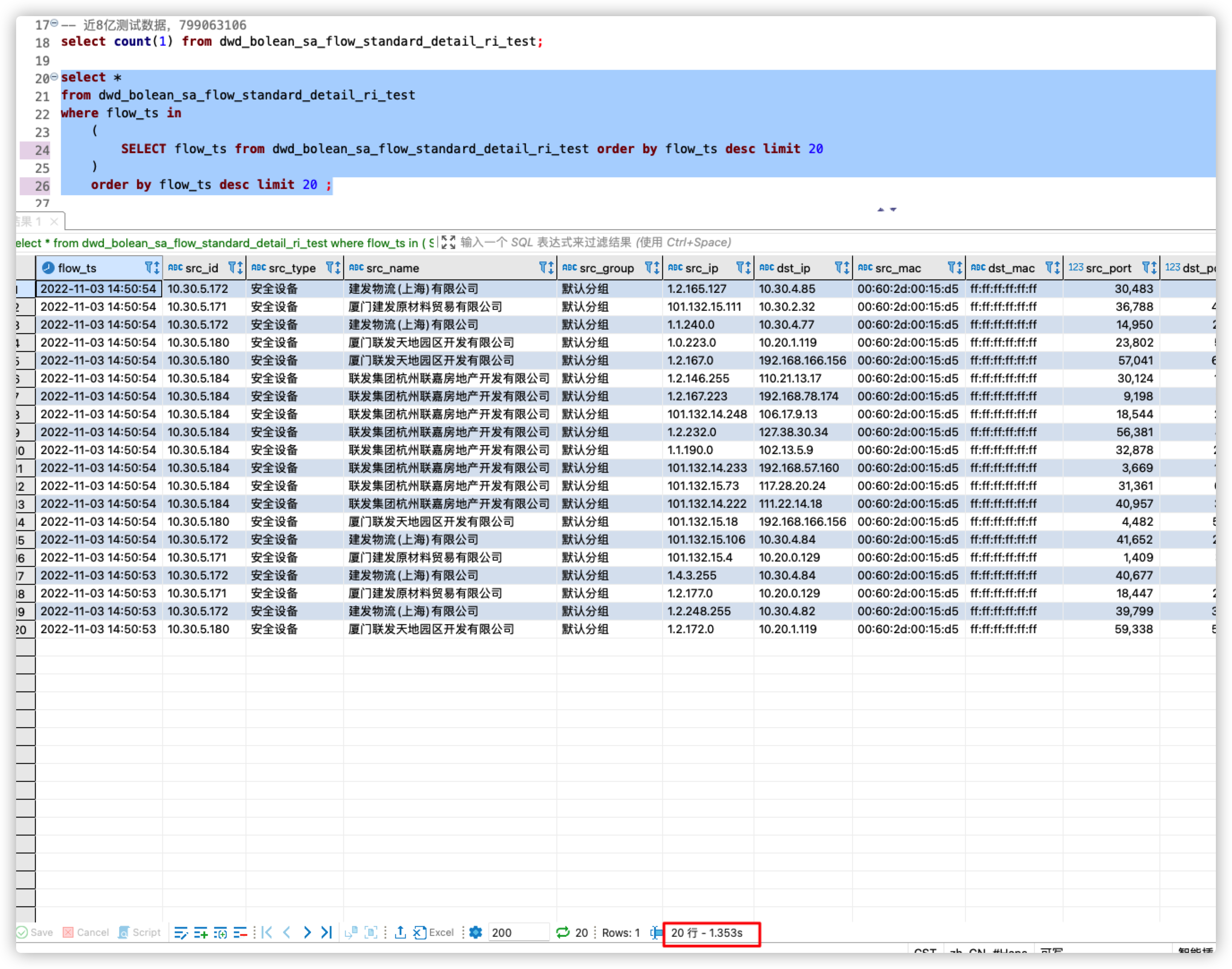
order by limit都是全排序,limit/offset越大是会越慢的,我看你的需求是有时间分区的,可以在能保证数据的前提下加一些时间过滤?比如取最近1个月2个月的数据,应该也会比直接全排快
需求是希望查出 最新的5000的数据,然后分页展示;加上时间过滤条件,如果极端情况下这段时间没有数据,页面上就都是空的了,让人哭笑不得的需求,产品不希望页面空空的。。。
这种按时间分区的数据,在做order by 取limit时是不是可以避免全排序啊。。