【详述】测试spark load导入时报错start spark app failed
先创建resource:
CREATE EXTERNAL RESOURCE “spark0”
PROPERTIES
(
“type” = “spark”,
“spark.master” = “yarn”,
“spark.submit.deployMode” = “cluster”,
“spark.hadoop.yarn.resourcemanager.address” = “rm1:8032”,
“spark.hadoop.fs.defaultFS” = “hdfs://grampus”,
“spark.hadoop.dfs.nameservices” = “grampus”,
“spark.hadoop.dfs.ha.namenodes.grampus” = “nn1,nn3”,
“spark.hadoop.dfs.namenode.rpc-address.grampus.nn1” = “nn1:8020”,
“spark.hadoop.dfs.namenode.rpc-address.grampus.nn3” = “nn3:8020”,
“spark.hadoop.dfs.client.failover.proxy.provider” = “org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider”,
“working_dir” = “hdfs://grampus/tmp/starrocks”,
“broker” = “sparkbroker0”,
“broker.dfs.nameservices” = “grampus”,
“broker.dfs.ha.namenodes.grampus” = “nn1,nn3”,
“broker.dfs.namenode.rpc-address.grampus.nn1” = “nn1:8020”,
“broker.dfs.namenode.rpc-address.grampus.nn3” = “nn3:8020”,
“broker.dfs.client.failover.proxy.provider” = “org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider”,
“hadoop.security.authentication” = “kerberos”,
“kerberos_principal” = “starrocks/starrocks@HADOOP.COM”,
“kerberos_keytab” = “/root/.starrocks.keytab”
);
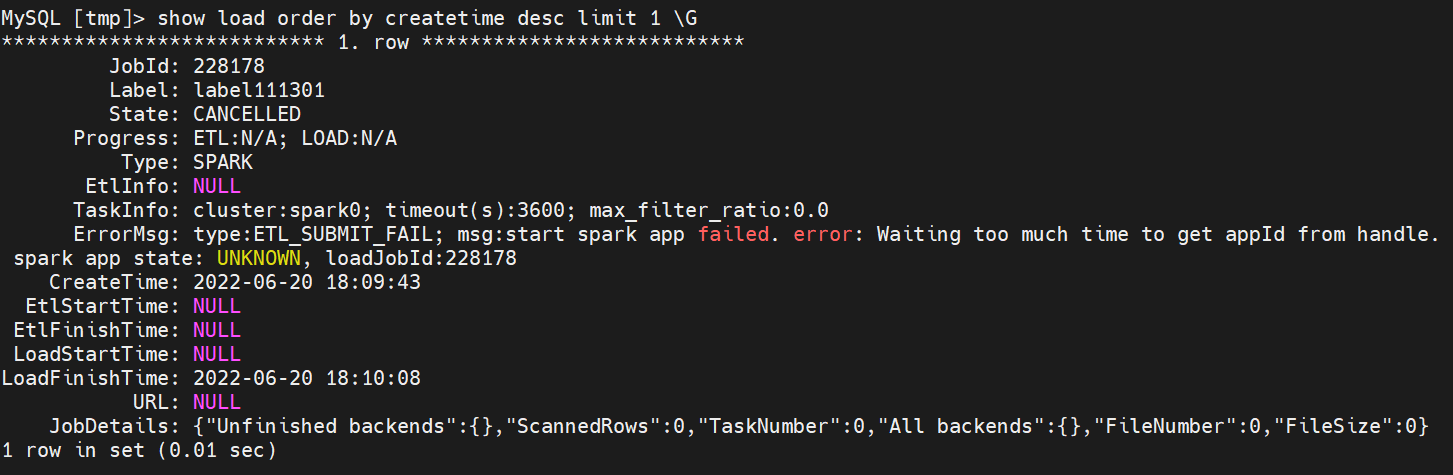
导入:LOAD LABEL label111301 ( DATA INFILE(“hdfs://grampus/tmp/customer.csv”) INTO TABLE customer COLUMNS TERMINATED BY “|” (c_custkey,c_name,c_address,c_city,c_nation,c_region,c_phone,c_mktsegment) ) WITH RESOURCE ‘spark0’ ( “spark.executor.memory” = “2g”, “spark.shuffle.compress” = “true” ) PROPERTIES ( “timeout” = “3600” );
报错信息: ErrorMsg: type:ETL_SUBMIT_FAIL; msg:start spark app failed. error: Waiting too much time to get appId from handle. spark app state: UNKNOWN, loadJobId:228178
【导入/导出方式】spark load
【背景】测试spark load
【业务影响】无
【StarRocks版本】2.1.3
spark:spark-2.4.0
hadoop:hadoop-3.1.1
【集群规模】3fe(3 follower)+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【附件】
- fe.warn.log/be.warn.log/相应截图
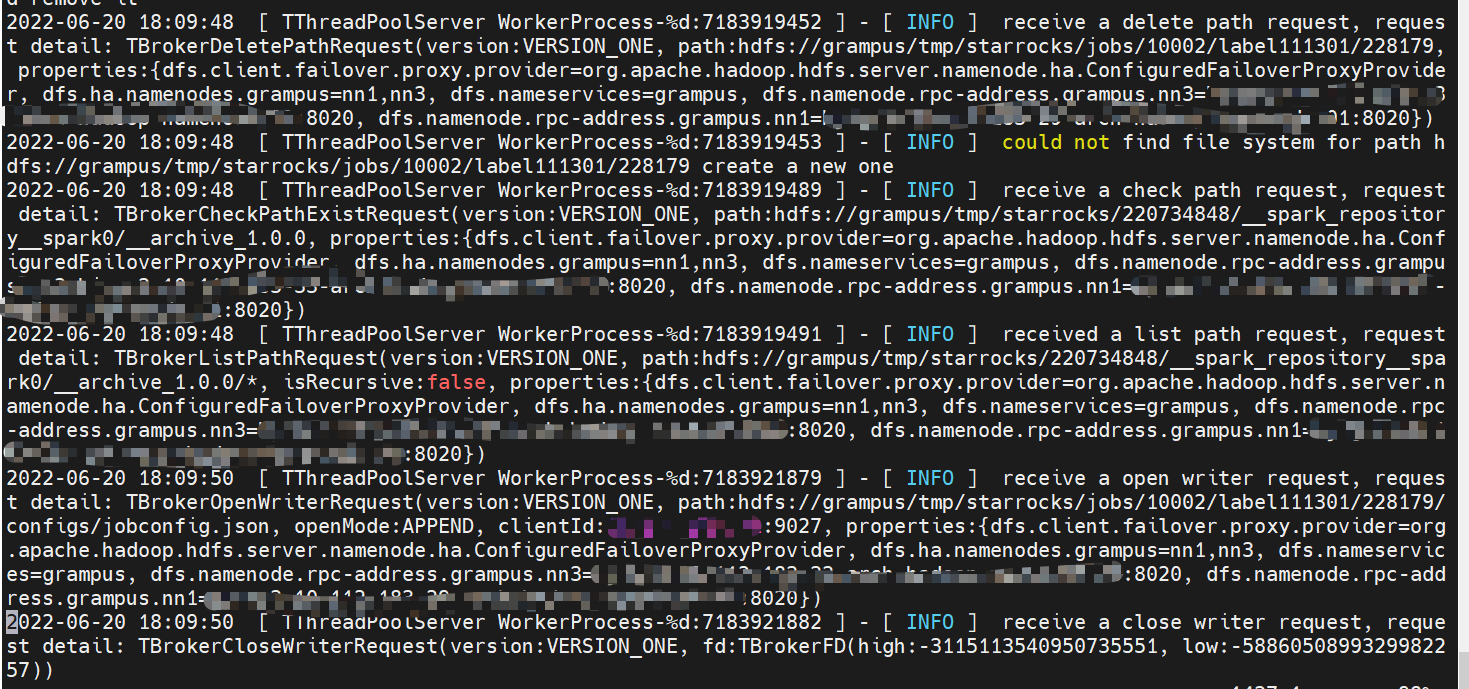
apache_hdfs_broker.log