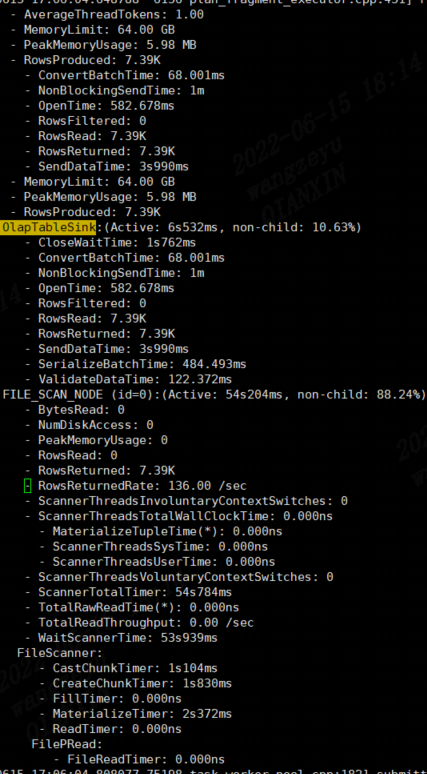
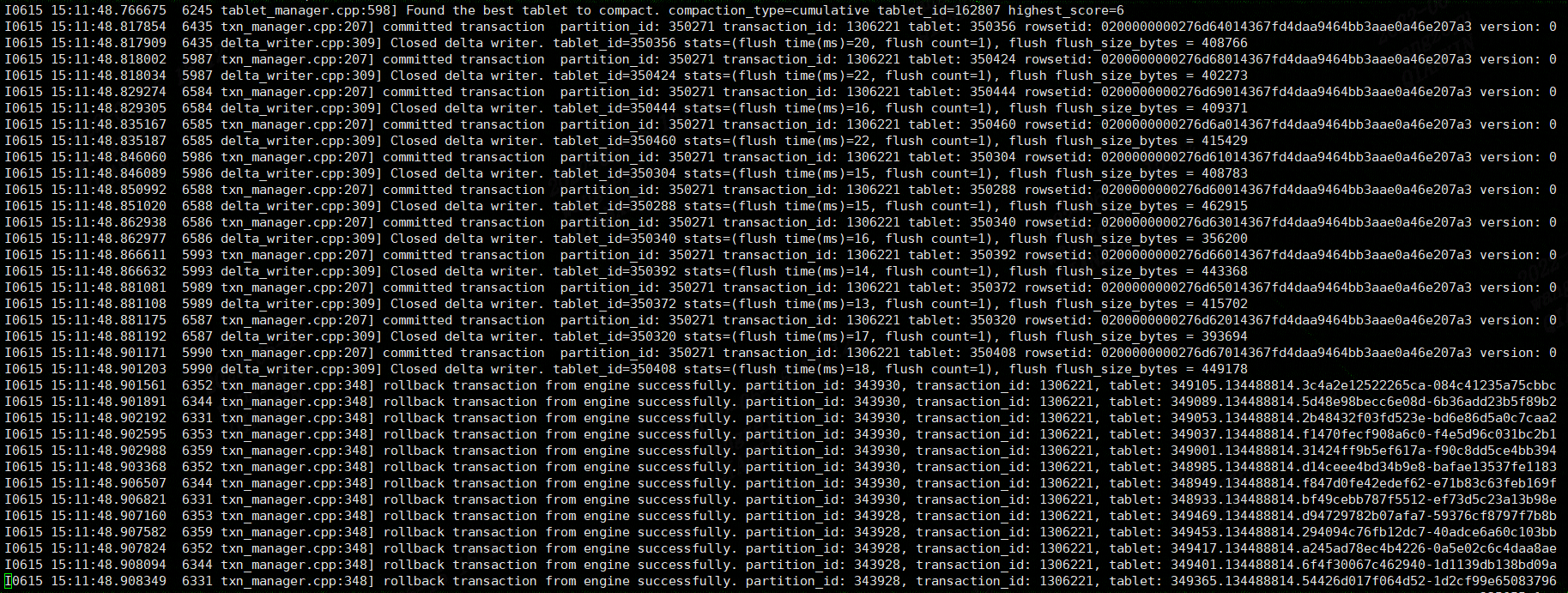
建表语句:
表一共有100列。
下面是建表的具体配置:
INDEX xx1( 1),
INDEX xx2( 2),
INDEX xx3( 3),
INDEX xx4( 4),
INDEX xx5( 5),
INDEX xx6( 6),
INDEX xx7( 7)
) ENGINE=OLAP
DUPLICATE KEY(mid)
PARTITION BY RANGE (event_date) (
START (“2022-05-13”) END (“2022-06-13”) EVERY (INTERVAL 1 day)
)
DISTRIBUTED BY HASH(mid) BUCKETS 48
PROPERTIES(
“bloom_filter_columns”=“1,2,3,4,5”,
“replication_num” = “3”,
“dynamic_partition.enable” = “true”,
“dynamic_partition.time_unit” = “DAY”,
“dynamic_partition.start” = “-30”,
“dynamic_partition.end” = “3”,
“dynamic_partition.prefix” = “p”,
“dynamic_partition.buckets” = “48”
);
导入的配置:
这样的导入任务我起了4个的时候消费数据达到最大化。
后来加到8个也不会提升了。
CREATE ROUTINE LOAD load_00008 ON v6
COLUMNS (100列),
WHERE rule_group_id !=""
PROPERTIES
(
“format”=“json”,
“desired_concurrent_number”=“13”,
“max_error_number”=“200000”
)
FROM KAFKA
(
“kafka_broker_list”=“xxx”,
“kafka_topic”=“xx”,
“property.security.protocol”=“SASL_PLAINTEXT”,
“property.sasl.mechanism”=“GSSAPI”,
“property.sasl.kerberos.service.name”=“kafka”,
“property.sasl.kerberos.keytab”=“xxx”,
“property.sasl.kerberos.principal”=“xxxxx”,
“property.group.id” = “starrocks_v6_load”,
“kafka_partitions” = “105,106,107,108,109,110,111,112,113,114,115,116,117,118,119”,
“kafka_offsets” = “1162834805,1181955137,1111741807,1124902750,1255682692,1135177260,1217492156,1173053817,1323193605,1119963261,1142216733,1167423810,1248097662,1158699173,1273511598”
);