【详述】问题详细描述
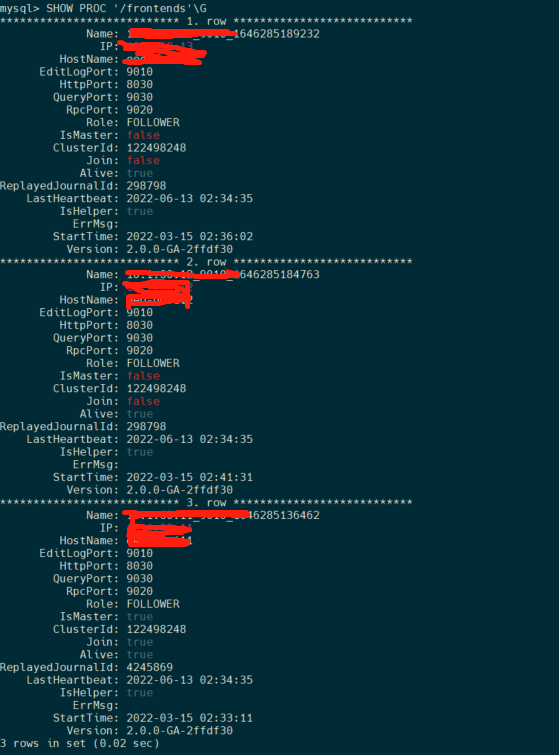
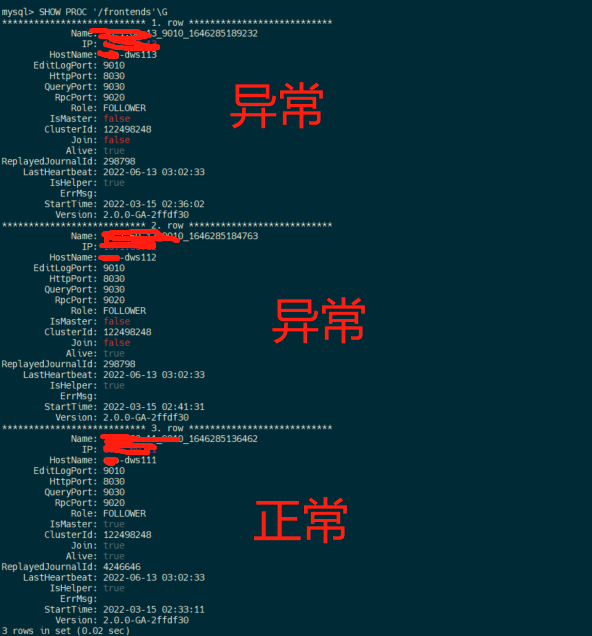
三个fe节点,一直在用主节点,一段时间后发现,其他两个节点的数据库信息和主节点fe的数据库信息不一样,三个fe的信息没有同步
【背景】创建hive外表,刷新外表分区时报其他两个节点没有该表信息
【业务影响】
【StarRocks版本】2.0.0-GA
【集群规模】例如:3fe(3 follower)+3be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
【附件】
从节点的日志截图
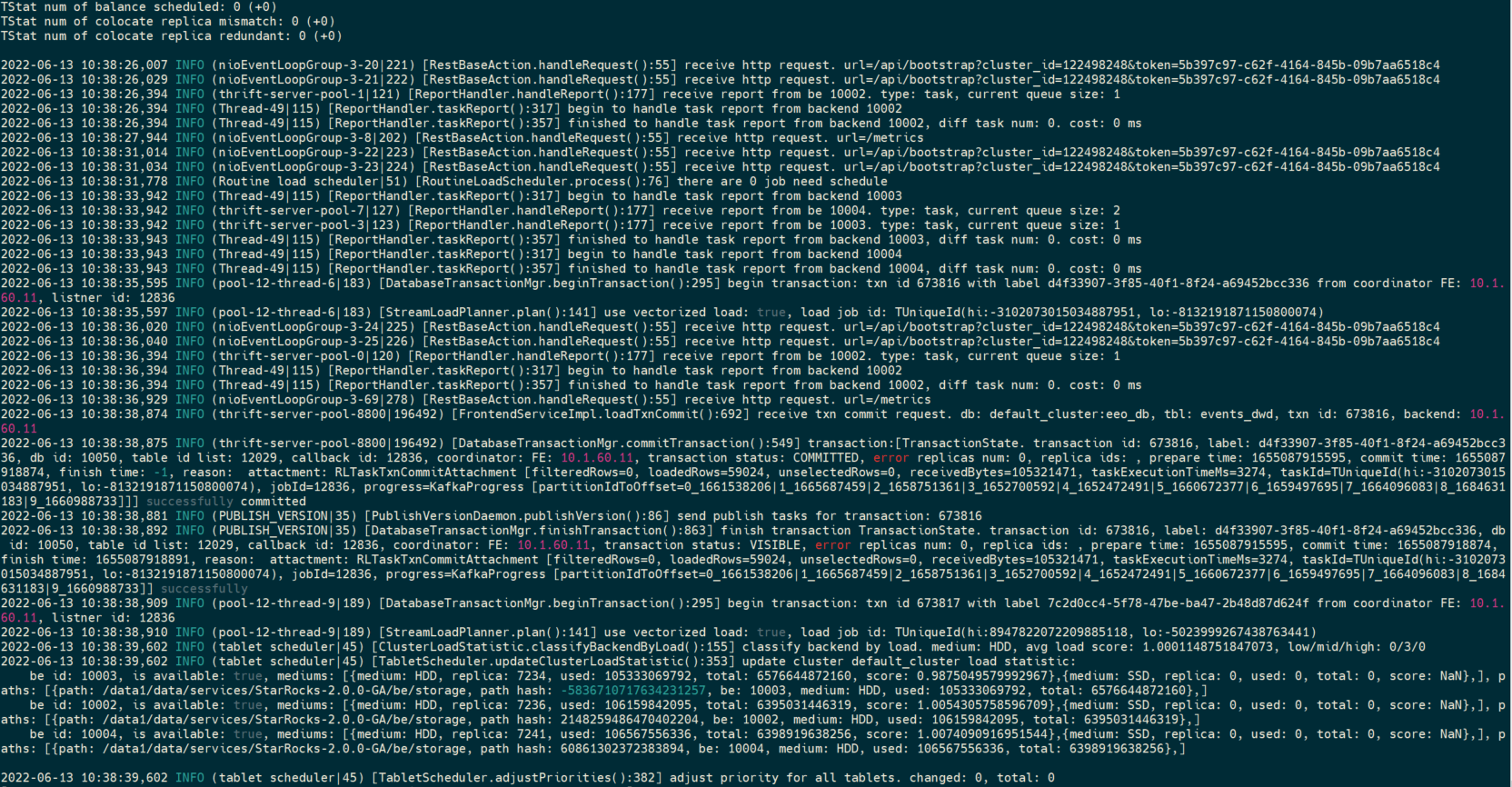
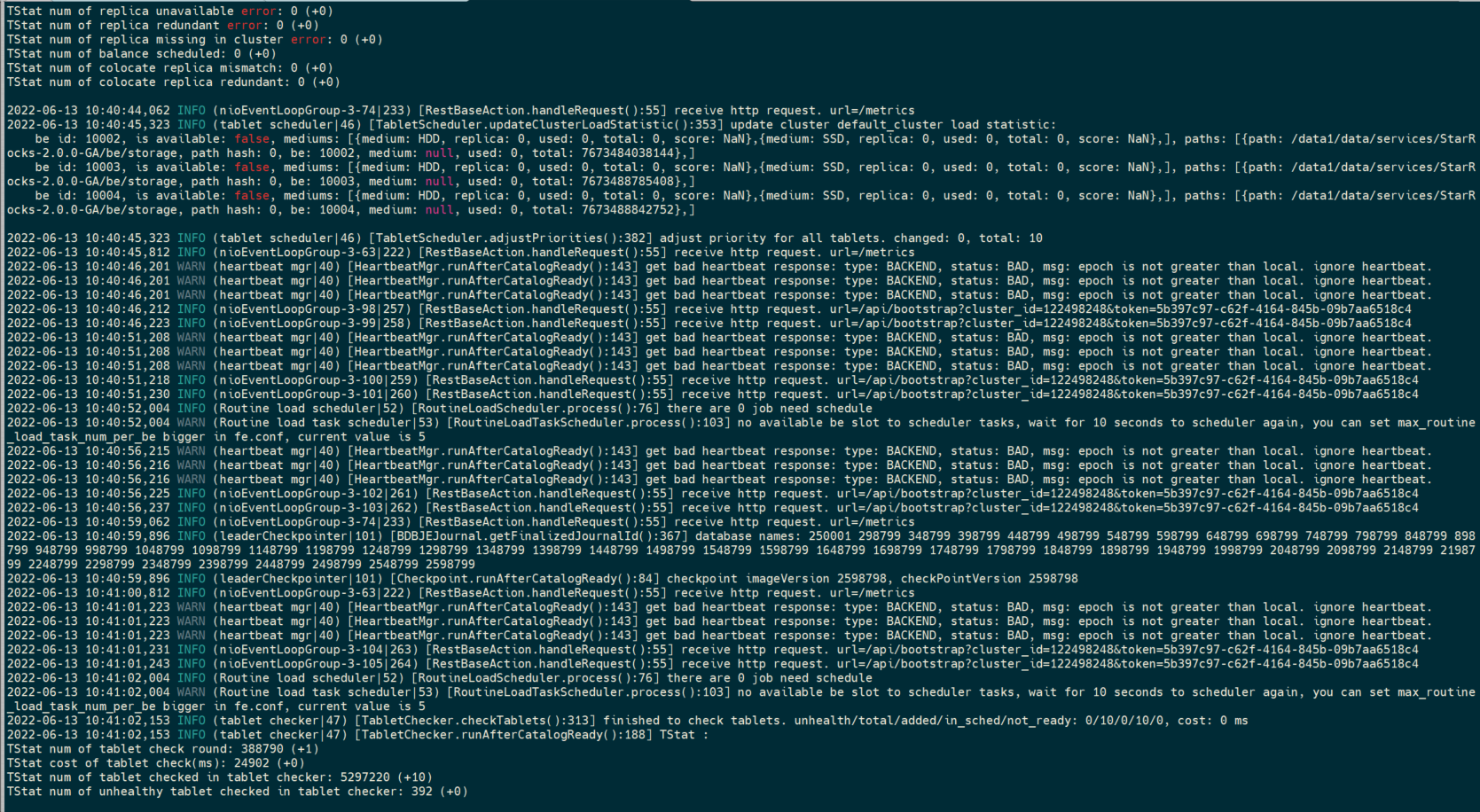
- fe.warn.log/be.warn.log日志信息
2022-06-10 15:09:48,648 WARN (heartbeat mgr|40) [HeartbeatMgr.runAfterCatalogReady():143] get bad heartbeat response: type: BACKEND, status: BAD, msg: epoch is not greater than local. ignore heartbeat.
2022-06-10 15:09:48,649 WARN (heartbeat mgr|40) [HeartbeatMgr.runAfterCatalogReady():143] get bad heartbeat response: type: BACKEND, status: BAD, msg: epoch is not greater than local. ignore heartbeat.
2022-06-10 15:09:48,649 WARN (heartbeat mgr|40) [HeartbeatMgr.runAfterCatalogReady():143] get bad heartbeat response: type: BACKEND, status: BAD, msg: epoch is not greater than local. ignore heartbeat.
2022-06-10 15:09:53,652 WARN (heartbeat mgr|40) [HeartbeatMgr.runAfterCatalogReady():143] get bad heartbeat response: type: BACKEND, status: BAD, msg: epoch is not greater than local. ignore heartbeat.
2022-06-10 15:09:53,653 WARN (heartbeat mgr|40) [HeartbeatMgr.runAfterCatalogReady():143] get bad heartbeat response: type: BACKEND, status: BAD, msg: epoch is not greater than local. ignore heartbeat.
2022-06-10 15:09:53,653 WARN (heartbeat mgr|40) [HeartbeatMgr.runAfterCatalogReady():143] get bad heartbeat response: type: BACKEND, status: BAD, msg: epoch is not greater than local. ignore heartbeat.
2022-06-10 15:09:54,671 WARN (Routine load task scheduler|53) [RoutineLoadTaskScheduler.process():103] no available be slot to scheduler tasks, wait for 10 seconds to scheduler again, you can set max_routine_load_task_num_per_be bigger in fe.conf, current value is 5
刷新hive外表分区信息时报错