
提到 Apache Hudi,关注数据湖的同学想必都不陌生,Apache Hudi 与 Apache Iceberg、Delta Lake 一起被并称为“数据湖三剑客”。
其中 Apache Hudi 引入了事务、行级别的更新/删除、流式更新到数据湖等优势,近年来越来越多地被阿里、字节跳动、腾讯等头部互联网公司关注,用作构建企业数据湖的基础架构。
与此同时,随着数据湖架构的日益成熟,如何对数据湖中的数据进行高效极速的分析,也成为企业数据湖平台成败的关键。
作为 StarRocks 社区的战略合作伙伴,阿里云一直致力于将 StarRocks 打造为全新的数据湖分析引擎。继在 2.1 版本主导并贡献了 Apache Iceberg 外表的特性后,经过近两个月的设计与开发, 阿里云开源大数据团队在 StarRocks 2.2 版本中又贡献了面向 Apache Hudi 的外表特性,进一步扩展了 StarRocks 在数据湖上的分析能力:
- 支持读取 Copy on Write 表
- 支持 Apache Hudi 最新版本的 Snapshot 查询
- 支持底层 ORC/Parquet 存储
- 支持 HDFS 和对象存储
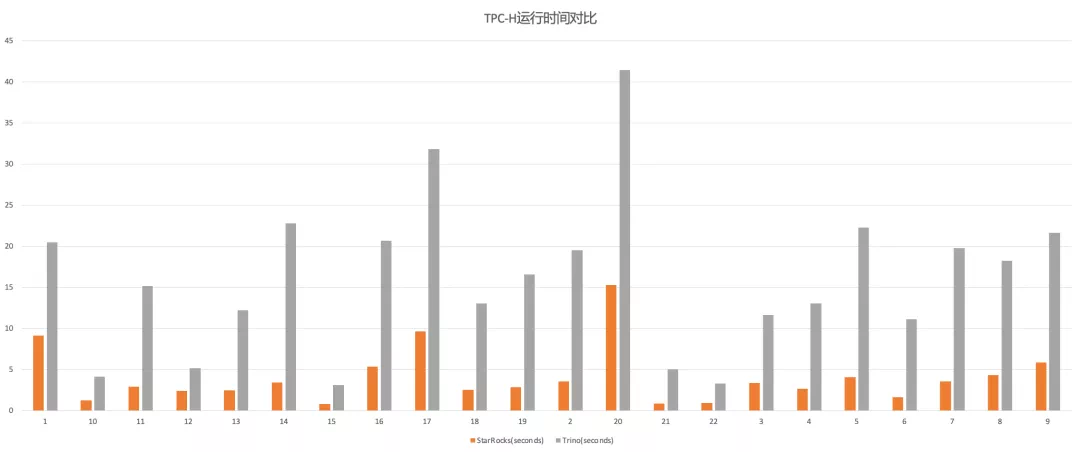
在 TPC-H 100G 测试集上,通过 CBO 优化器、向量化执行和 C++ Native 执行等优化, StarRocks 的查询性能是 Trino (PrestoSQL) 的 2.1-6.8 倍:
欲求功法详解? 5 月 18 日 19:00-20:00 ,来自阿里云开源大数据团队的技术大牛 陈玉兆 、 王日宇 现身 Meetup,展开讲讲面向 Apache Hudi 的 StarRocks 外表特性。
、
错过直播的朋友,可以在评论区获得回放链接与下载 PPT! 