

摘要:从 Iceberg Catalog 接入到冷热数据分层,了解 StarRocks 如何构建统一的联邦查询架构。
导读:
本文结合 Fresha 的实际案例,介绍了其如何利用 StarRocks 构建基于 Iceberg 的联邦查询架构,并分析了 Metadata Cache、自适应元数据读取、冷热数据分层等关键能力在实际场景中的应用。
数据湖是 Query Federation 最重要的应用场景之一。随着存算分离架构的普及,越来越多的数据被存储在对象存储中,并以 Apache Iceberg 等开放表格式进行管理,由不同计算引擎按需访问。
对于 Iceberg 而言,查询性能很大程度上取决于两个因素:
- 查询引擎能否高效利用 Metadata 快速定位所需数据文件;
- 能否有效利用谓词下推和分区裁剪,进一步减少需要读取的数据文件数量。
随着数据规模增长,Iceberg 底层文件数量会快速增加。如果大量小文件长期存在,查询时就需要打开和扫描更多对象,从而带来额外的延迟和存储访问开销。因此,Compaction 等维护操作对于保障数据湖性能至关重要。
这一问题会影响所有 Iceberg 查询引擎,但不同系统的处理方式并不相同。
Trino 通常直接从对象存储读取 Iceberg 数据,因此在查询时需要承担大量小文件打开和读取带来的开销,查询性能也会更加依赖表维护的效果。而 StarRocks 则通过 Metadata Cache、本地执行、物化视图以及 Compaction 等机制降低远程访问开销,从而减少碎片化对查询性能的影响。
此外,StarRocks 还支持冷热数据分层策略:最新数据实时写入 StarRocks 内表,而历史数据存储在 Iceberg 中,仅在需要时进行访问。这不仅能够降低对象存储访问成本,还能够同时兼顾实时分析。
在 Fresha 的实践中,通过将外部 Iceberg Catalog 接入 StarRocks,团队获得了两项关键收益:
- 直接复用 Snowflake 中导出的 Iceberg 数据模型,为业务提供统一 SQL 查询入口;
- 基于冷热数据分层架构,进一步降低实时分析场景下的查询延迟。
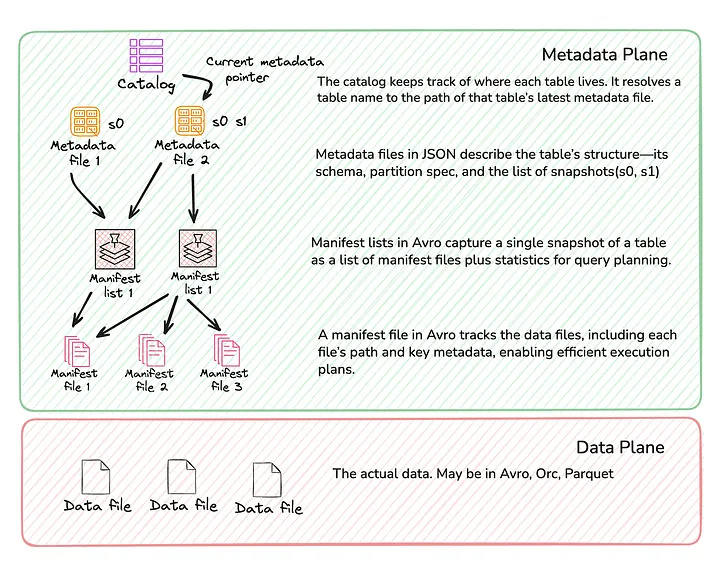
StarRocks 与 Iceberg 集成
StarRocks 可以直接访问数据湖中的 Iceberg 表,并将其视为原生表进行查询。
从执行流程来看,StarRocks 查询 Iceberg 数据主要分为两个阶段:
Metadata Planning
- 读取当前 Snapshot ID,定位对应的 Table Metadata。
- 读取 Manifest List,并进一步获取 Manifest Files。
- 基于 Metadata 信息进行裁剪(Pruning),过滤与查询无关的数据文件。
- 将剩余数据文件生成执行计划,并分发至计算节点(CN)执行。
Distributed Execution
- 各计算节点从远程存储读取分配到的数据文件。
- StarRocks 基于向量化执行引擎,以列式方式读取数据。
- 对于 Metadata Planning 阶段无法处理的过滤条件(例如非分区列过滤),StarRocks 会进一步下推到存储层执行,以减少数据读取量。
- 最后处理 Position Delete 和 Equality Delete 文件,确保查询结果满足 Iceberg 的事务一致性要求。
为了进一步提升查询效率并减少网络 I/O,我们 在 Iceberg 查询过程中引入了多项优化机制。
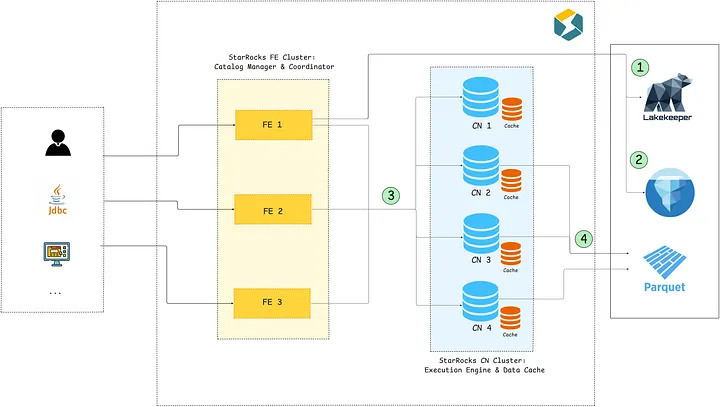
首先,Iceberg 元数据会同时缓存于内存和本地磁盘中,避免频繁访问远程存储。两级缓存均采用 LRU(Least Recently Used)淘汰策略,以优先保留热点元数据。
其次,StarRocks 引入了自适应元数据读取(Adaptive Metadata Retrieval)机制,能够根据查询规模和复杂度选择最合适的元数据访问方式。
对于大规模查询,StarRocks 会将 Manifest 文件的读取、解压和过滤任务分发至多个 CN 节点并行执行,以提升处理效率;对于元数据量较小的场景,则会缓存反序列化后的内存对象,避免重复解压和解析带来的额外开销。
此外,StarRocks 还支持异步元数据刷新机制。系统会通过轮询方式检查 Metastore 中 Iceberg 表的变化,并自动更新经常访问表的元数据缓存。当表不再被访问时,相关后台任务也会自动停止,从而避免不必要的轮询开销。
统计信息缺失导致的查询问题
前文提到,查询引擎的优化和执行高度依赖表统计信息,StarRocks 也不例外。
在 Fresha 早期实践中,我们曾遇到部分 Iceberg 表查询性能异常的问题,甚至一度触发 CN 节点 Segmentation Fault,影响整体查询延迟。
排查后发现,这些问题均出现在通过 Snowflake 导出至 Iceberg 的表上。具体来说:
- 这些表通过外部管理的 Catalog-Linked Database 导出生成;
- 导出的 Parquet 文件缺少 Page Index 和 Null Value Count(NVC)等统计信息;
- StarRocks 默认会利用这些统计信息进行优化(可通过 enable_parquet_reader_page_index 配置控制);
- 当相关统计信息缺失时,系统在读取过程中会触发空指针访问,从而导致异常。
为了解决这一问题,我们最终选择使用 Spark 作为 Iceberg Writer。由于 Spark 3.x 默认生成 Parquet Page Index,因此无需关闭 StarRocks 的 Page Index 优化能力,也避免了由此带来的性能损失。
与此同时,Fresha 与 StarRocks 社区共同修复了这一问题,相关改进将在未来版本中正式发布。
Iceberg Catalog 配置
在 StarRocks 中接入外部 Iceberg Catalog 非常简单,只需执行几条 SQL 即可完成配置。
Fresha 使用的是 Iceberg REST Catalog(Lakekeeper),而 StarRocks 也支持多种 Iceberg Catalog 类型,具体配置方式可参考官方文档。
CREATE EXTERNAL CATALOG lakekeeper
PROPERTIES (
"type": "iceberg"
"aws.s3.region": "us-east-1"
"aws.s3.endpoint": "https://s3.us-east-1.amazonaws.com"
"aws.s3.path_style_access": "false"
"aws.s3.use_aws_sdk_default_behavior": "true"
-- Iceberg catalog configuration
-- REST Catalog with vended credentials
"iceberg.catalog.type": "rest"
"iceberg.catalog.uri": "{{ ssm_param.lakekeeper_endpoint }}"
"iceberg.catalog.security": "oauth2"
"iceberg.catalog.oauth2.scope": "lakekeeper"
"iceberg.catalog.oauth2.server-uri": "{{ ssm_param.keycloak_token_endpoint }}"
"iceberg.catalog.oauth2.credential": "{{ ssm_param.client_id }}:{{ ssm_param.client_secret }}"
"iceberg.catalog.rest.nested-namespace-enabled": "true"
"iceberg.catalog.warehouse": "{{ environment }}"
-- Metadata cache settings
"enable_iceberg_metadata_cache": "true"
"enable_iceberg_metadata_disk_cache": "true"
"iceberg_metadata_cache_expiration_seconds": "1800"
"iceberg_metadata_memory_cache_expiration_seconds": "1800"
);
完成配置后,即可访问远端 Catalog 中的数据库和表。需要注意的是,外部 Catalog 同样需要进行权限管理。相关授权方式和 RBAC 配置可参考 StarRocks 官方文档。
mysql > show databases in lakekeeper;
+ ---------------------+
| Database |
+ ---------------------+
| information_schema |
| remote_iceberg_data |
+ ---------------------+
2 rows in set ( 0.120 sec)
mysql> show tables in lakekeeper.remote_iceberg_data;
+----------------------------------------------------------+
| Tables_in_remote_iceberg_data |
+----------------------------------------------------------+
| snowflake__partners_reporting__location_all_time_metrics |
| snowflake__partners_reporting__location_daily_metrics |
| snowflake__partners_reporting__occupancy_employee_recent |
| ... |
完成配置后,即可直接查询远端 Iceberg 数据,且查询性能表现良好。
SELECT count(*)
FROM snowflake__partners_reporting__location_all_time_metrics
WHERE provider_id = 604262;
+----------+
| count(*) |
+----------+
| 55 |
+----------+
1 row in set (0.317 sec)
执行计划分析
通过接入外部 Iceberg Catalog,Fresha 得以直接复用部分来自 Snowflake 的数据模型。
这种方式非常适合对实时性要求相对宽松的场景,例如日报、月报等分析任务。相比直接访问 Snowflake,StarRocks 提供了统一的 SQL 查询入口,同时能够更好地支撑面向用户的高并发查询场景。
在 Fresha 的实践中,这些来自 Snowflake 的模型被用于丰富 StarRocks 内部实时数据,提供全周期统计指标和资源利用率(Occupancy)等分析能力。
为了分析和可视化查询执行计划,Fresha 使用了自研工具 NorthStar。
简单来说,客户端只需运行:
mysql> SELECT *
-> FROM perf_drawer_occupancy_employee_tab_month
-> WHERE provider_id = 604262;
300 rows in set (0.858 sec)
其底层实际上是一个视图,用于关联从 Snowflake 导出的指标数据与 StarRocks 内部表中的维度数据。

(统一 SQL 访问:Iceberg 表与内部 OLAP 表联合查询,执行计划通过 Fresha 自研的 NorthStar 查询可视化工具展示。)
通过 EXPLAIN VERBOSE 查看执行计划,并重点关注 Iceberg 相关执行节点,可以看到如下执行过程:
| 0:IcebergScanNode
| TABLE: remote_iceberg_data.snowflake__partners_reporting__occupancy_employee_recent
| PREDICATES: 145: provider_id = 604262
| MIN/MAX PREDICATES: 145: provider_id <= 604262, 145: provider_id >= 604262
| cardinality=81
| avgRowSize=89.0
| dataCacheOptions={populate: true}
| partitions=1/1
| Iceberg Scan Metrics:
| {
| "table-name":"lakekeeper.remote_iceberg_data.snowflake__partners_reporting__occupancy_employee_recent",
| "snapshot-id":2418576845940344305,
| "filter":{"type":"eq","term":"provider_id","value":"(hash-0f307c8d)"},
| "schema-id":0,
| "projected-field-ids":[1,2,3,4,5,6,7,8],
| "projected-field-names":["occupancy_employee_pk","calendar_date","provider_id","location_id",...],
| "metrics":{
| "total-planning-duration":{
| "count":1,
| "time-unit":"nanoseconds",
| "total-duration":163733626},
| "result-data-files":{"unit":"count","value":17},
| "result-delete-files":{"unit":"count","value":0},
| "total-data-manifests":{"unit":"count","value":2},
| "total-delete-manifests":{"unit":"count","value":0},
| "scanned-data-manifests":{"unit":"count","value":2},
| "skipped-data-manifests":{"unit":"count","value":0},
| "total-file-size-in-bytes":{"unit":"bytes","value":1207339764},
| "total-delete-file-size-in-bytes":{"unit":"bytes","value":0},
| "skipped-data-files":{"unit":"count","value":15},
| "skipped-delete-files":{"unit":"count","value":0},
| "scanned-delete-manifests":{"unit":"count","value":0},
| "skipped-delete-manifests":{"unit":"count","value":0},
| "indexed-delete-files":{"unit":"count","value":0},
| "equality-delete-files":{"unit":"count","value":0},
| "positional-delete-files":{"unit":"count","value":0},
| "dvs":{"unit":"count","value":0}},
| "metadata":{"iceberg-version":"Apache Iceberg 1.10.0 (commit 2114bf631e49af532d66e2ce148ee49dd1dd1f1f)"}}
| cardinality: 81
| probe runtime filters:
| - filter_id = 0, probe_expr = (145: provider_id)
从执行计划中可以看到:
-
StarRocks 会充分利用 Iceberg 表的统计信息进行查询优化;
-
自动跳过与查询无关的 Manifest 文件;
-
将过滤条件(Predicate)下推至 Iceberg,减少数据传输量;
-
尽早执行列裁剪(Projection;
-
在查询过程中自动填充 Data Cache。
这些优化共同提升了 StarRocks 查询 Iceberg 表的性能表现(当然,前提是 Parquet 文件包含必要的 Page Index )。
其他外部 Catalog
除了 Iceberg 之外,StarRocks 还支持多种外部数据源和开放表格式,并能够以统一方式进行查询和管理。
Fresha 此前已经探索过 StarRocks 与 Elasticsearch 的集成,未来也计划进一步开展 Apache Paimon 相关实践。
从实际使用来看,StarRocks 提供了 Lakehouse 架构所需的核心能力:
-
存算分离架构,支持弹性扩缩容;
-
统一访问不同数据源和开放表格式的数据;
-
热数据实时写入 StarRocks,冷数据存储于低成本对象存储;
-
通过灵活的缓存机制减少远程文件重复扫描,降低查询成本。
这些能力使团队能够在统一平台上构建兼顾性能与成本的数据分析架构。
本文主要摘取了原文中的实践部分进行整理与翻译。对于 Query Federation、Trino 与 StarRocks 架构设计差异等背景内容,感兴趣的读者可阅读原文了解更多细节:
