

在生产环境中,FE 内存问题较为常见,尤其是 JVM Heap 相关问题,往往会影响集群稳定性与问题定位效率。本文基于实际案例,梳理 FE 内存问题的分析思路、排查方法与经验总结。
本文重点聚焦 FE JVM Heap 内存问题,覆盖监控配置、日志分析、工具使用与典型案例。文中案例均已脱敏处理,讨论版本以 3.5 及之前版本为主。堆外内存(Direct Memory / Native Memory)、工具崩溃、操作系统层面问题不作为重点展开,但会补充 2 个堆外内存相关实战案例。
全文分为三个部分:FE 内存组成与观测方式、生产环境典型案例解析、总结与规范说明。
一、FE 内存与观测
FE 进程内存组成与配置指南
由于 FE 是 Java 进程,其内存问题本质上主要体现为 JVM 内存问题。JVM 内存通常可分为 Heap 内存与 Non-Heap 内存两类。
-
Heap 内存主要用于存储 Java 对象,承载 FE 核心业务逻辑中的各类对象,通常包括新生代与老年代两个区域。其中,新生代用于存放新创建、生命周期较短的对象;老年代用于存放存活时间较长的对象。
-
Non-Heap 内存 则主要支撑 JVM 底层运行,包括 Metaspace、Direct Memory、线程栈以及本地方法接口相关内存。
Heap 内存是 FE 内存中最核心的部分,配置时需要重点关注 -Xmx。
-
-Xmx表示 Maximum Heap Size,用于控制 Heap 内存上限,通常在fe.conf的JAVA_OPTS参数中配置,决定 FE 最多可以使用多少堆内存。 -
-Xms表示 Initial Heap Size,用于控制 JVM 启动时初始申请的堆内存。一般情况下不建议手动设置,FE 会根据机器内存自动计算。若用户显式设置了-Xms,需要在运行过程中重点关注 GC 情况:当-Xms设置过大时,JVM 启动后会直接申请较大的堆空间,G1 GC 可能不会过早、过于积极地回收对象;随着对象持续累积,后续可能出现连续 GC,甚至 Full GC。
堆外内存可通过 MaxDirectMemorySize、MaxMetaspaceSize、-Xss 等参数进行配置。通常情况下,这类参数仅在特殊业务场景下按需添加。
配置 FE 内存时,还需要为操作系统和其他进程预留足够空间;如果 FE 与其他组件混合部署,则应适当提高内存预留比例。对于独立部署的 FE 节点,可根据机器规格与业务负载,合理设置 Heap 上限,避免因配置过大影响系统稳定性。
独立部署 FE 节点时,可按机器内存比例设置 -Xmx 上限。由于 FE 进程运行时存在额外开销,实际物理内存占用(RSS)通常会高于 -Xmx 配置值,一般控制在 -Xmx 的 120% 以内属于正常范围。

Tablet 数量会直接影响 FE 内存配置。可通过以下命令查看集群整体 Tablet 总量,并结合集群规模匹配对应的内存配置:
SHOW PROC '/statistics';
Tablet 数量越多,对 FE Heap 内存的要求越高,可参考以下区间进行配置。
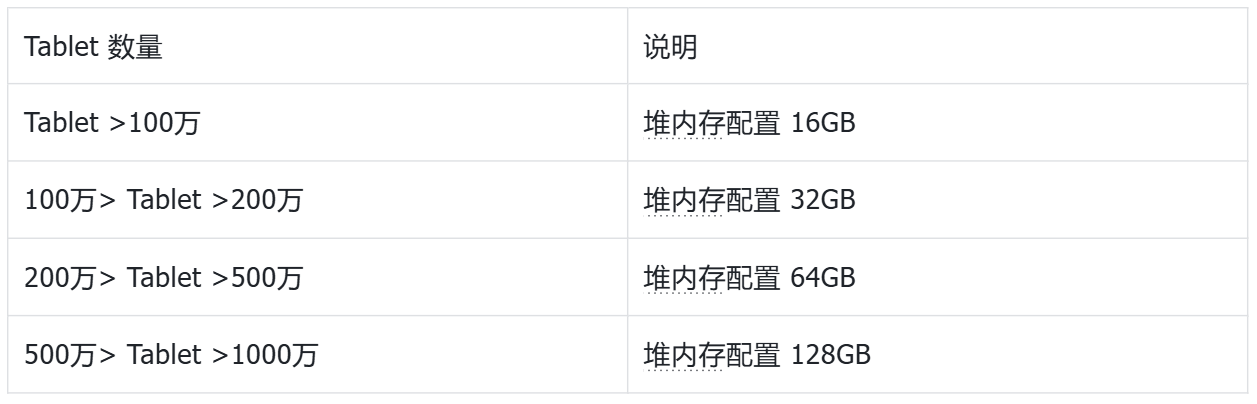
- FE Heap 内部占用与节点差异
FE Heap 主要承载业务运行所需的各类对象。按照生命周期,可分为运行时内存与常驻内存两类。
-
运行时内存是指 FE 在工作过程中临时产生、动态变化的对象,例如导入任务管理、事务状态管理、Query 执行上下文、统计信息及字典缓存等。这部分内存会随导入、查询、事务活跃度变化而波动。
-
常驻内存是指 FE 长期维护的元数据对象,例如
TabletInvertedIndex、LocalMetastore等,主要用于管理库、表、分区、Tablet、Replica 等核心元数据。
运行时内存主要覆盖导入、事务、查询、统计信息与字典缓存等动态业务场景。
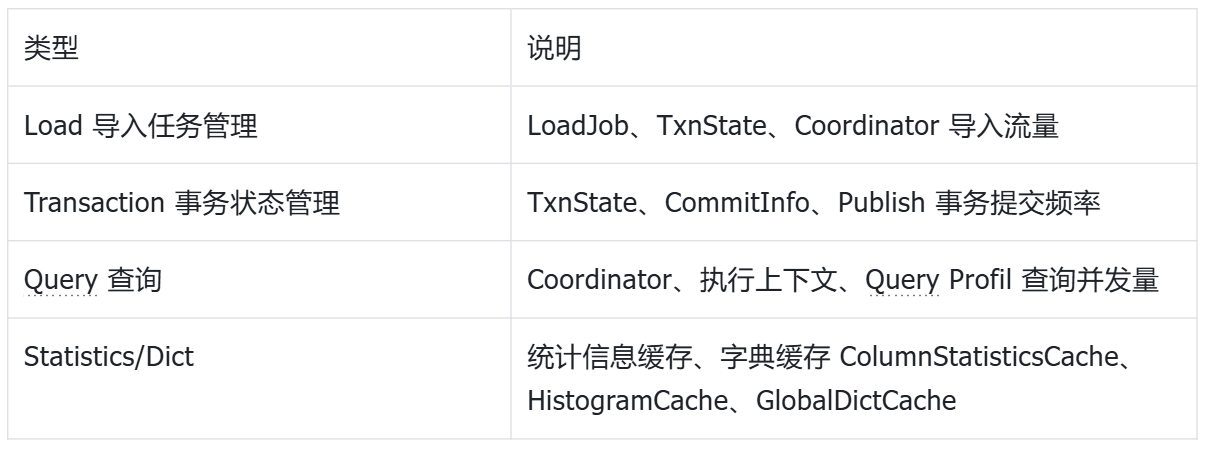
常驻内存主要用于维护 FE 长期持有的核心对象,保障集群元数据稳定管理。

- Leader 与 Follower 的内存差异
FE 集群包含多种角色,其中 Leader 与 Follower 的内存压力存在明显差异。

整体来看,Leader 不仅提供查询服务,还需要承担元数据写入、事务协调、任务调度及 Checkpoint 等工作,因此内存压力通常显著高于 Follower。
-
Follower 主要承担元数据同步和查询服务,整体内存压力相对较小。Leader 与 Follower 的内存差异,核心原因之一在于 Checkpoint 任务。
-
Checkpoint 可以理解为 FE 定期生成元数据快照。日常元数据变更会先写入操作日志(Journal);执行 Checkpoint 时,会先加载已有 Image 文件,再回放后续 Journal 到指定版本,并将当前完整的元数据状态写入新的 Image 文件。
通过这种机制,FE 重启或 Follower 同步时,无需从头回放全部日志。
由于 Checkpoint 过程中需要额外构造一份元数据对象用于日志回放和快照落盘,因此会产生额外的 Heap 内存开销。
在 3.4 版本之前,Checkpoint 任务由 Leader 节点独立承担,因此 Leader 内存占用通常明显高于 Follower。自 3.4 版本起,Checkpoint 调度机制完成优化,可将任务分配至 Follower 执行,Leader 与 Follower 的内存占用差距较 3.3 及更早版本已明显缩小。
核心监控指标配置
FE 内存监控主要包括 Heap 监控与 GC 监控两类。其中,Heap 监控可用于观察 FE 运行状态,也是事后定位内存问题的重要线索。
- Heap 监控指标
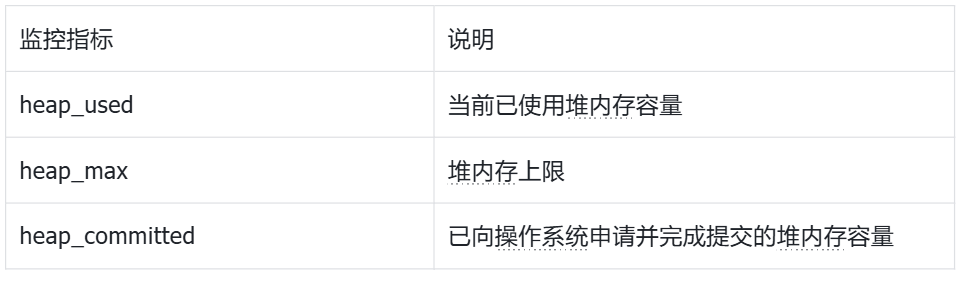
通过 heap_used、heap_max、heap_committed 三项指标,可以清晰观察 FE Heap 的实际使用状态。
- GC 监控指标

GC 监控可直观反映内存回收的触发频率与执行耗时,辅助运维人员判断 FE 内存回收是否正常。
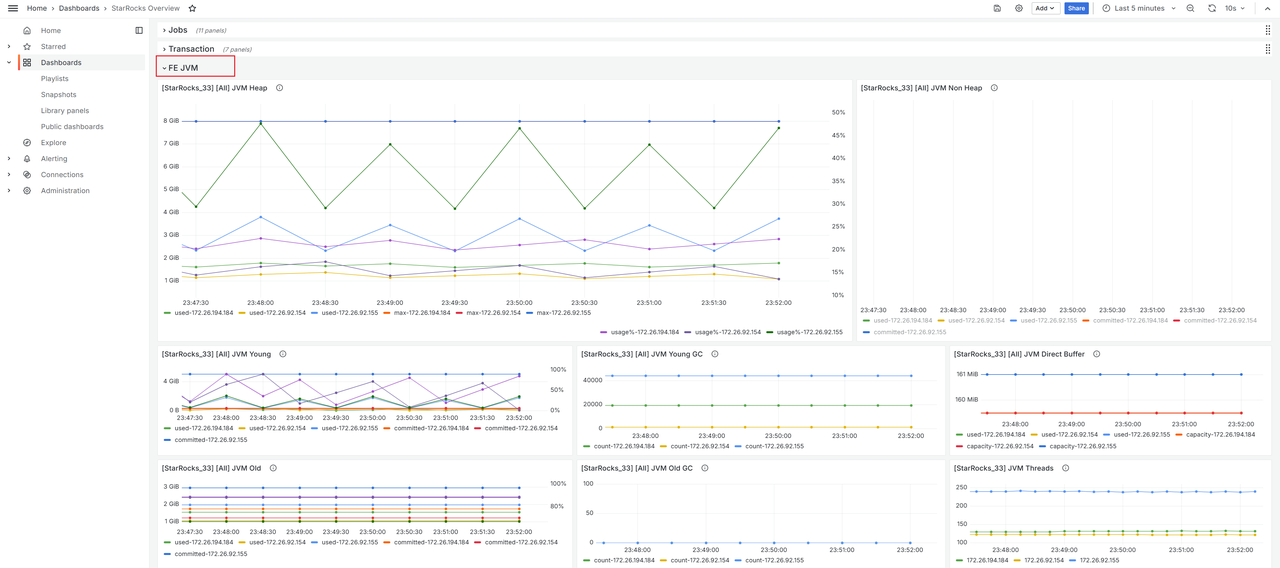
官方提供了标准化监控模板。导入模板后,可在 FE JVM 分类下查看全部内置指标,快速完成监控配置与数据观测。详情可参考:https://docs.starrocks.io/zh/docs/3.5/administration/management/monitoring/Monitor_and_Alert/
下图展示的是官方监控模板中的 JVM 监控面板,其中已包含前文提到的 Heap 与 GC 相关核心指标。
Mem Profile 内存分析工具
Mem Profile 基于开源工具 async-profiler,用于定时采集 FE 内存火焰图。
自 3.3.6+ 版本起,StarRocks 已支持自动输出 FE 内存火焰图,采集生成的压缩文件默认存储在 FE 日志目录:
fe/log/proc_profile/mem-profile-$date.html.tar.gz
该能力默认可用,无需额外配置。
在 3.3.6 之前版本,需通过脚本方式自行采样,并手动部署 mem_profiler.sh。
mem_profile 配置参数详解
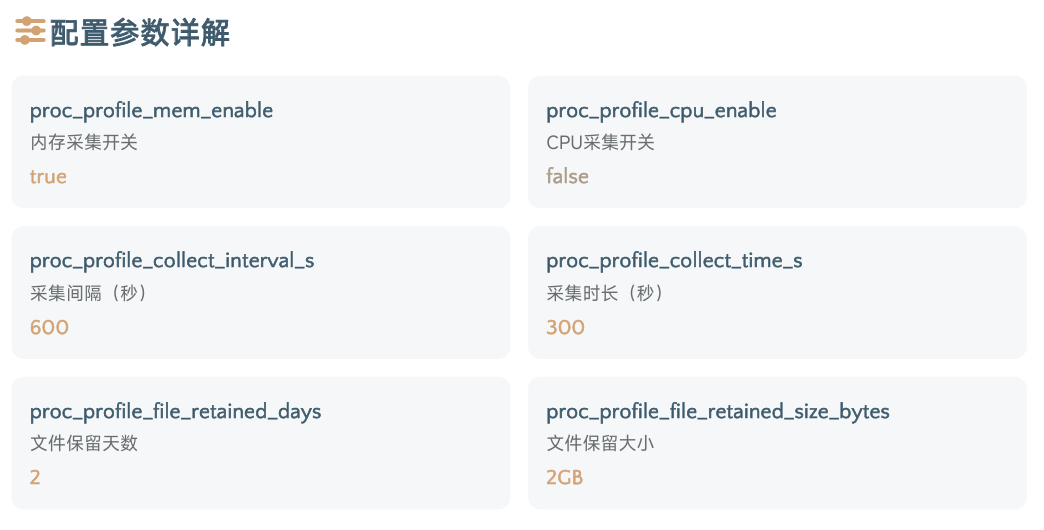
默认情况下,Mem Profile 执行单次 5 分钟采样,采集间隔为 5 分钟,采集文件默认保留 2 天,文件总容量控制在 2GB 左右。
在 v3.4.5+ / v3.5+ 版本中,Mem Profile 采集机制完成优化:
-
移除
collect_time_s参数; -
proc_profile_collect_interval_s默认值由 300 调整为 120,即单次采样持续 2 分钟; -
默认每 2 分钟采集一次,文件保留 1 天,总大小不超过 2GB。
需要注意的是,mem_profile 文件名中的时间表示采集开始时间,而不是压缩完成时间;文件生成时间则对应采样与压缩完成后的时间。排障时,应按照“采集窗口”对齐故障时间,即:
[文件名时间,文件名时间 + collect_time_s]
,再定位对应的目标数据文件。
3.3.6 之前版本,可通过专用脚本完成 Mem Profile 工具的部署与配置。
注: 该脚本对fe 进程无影响,不影响服务正常使用,会对过期48小时的文件自动清理
目的:
在每台fe 的安装目录下新建脚本文件mem_profiler.sh
将如下内容拷贝进文件
#!/bin/bash
mkdir -p mem_alloc_log
cleanup_old_files() {
find mem_alloc_log -name "alloc-profile-*.html" -mmin +2880 -exec rm -f {} \;
}
while true
do
cleanup_old_files
current_time=$(date +'%Y-%m-%d-%H-%M-%S')
file_name="mem_alloc_log/alloc-profile-${current_time}.html"
./bin/profiler.sh -e alloc --alloc 2m -d 300 -f "$file_name" `cat bin/fe.pid`
done
#后台启动脚本
chmod +x mem_profiler.sh
nohup ./mem_profiler.sh > mem_profiler.out 2>&1 &
## 检查进程是否存在
ps aux | grep mem_profiler.sh
## 停止进程
pkill -f mem_profiler.sh
Jmap 排查流程与 Memory Tracker
FE 内存问题排查通常可借助 Jmap 与 Memory Tracker 两类工具完成。
Jmap
Jmap 是 JDK 自带的内存分析工具,可用于查看 Java 进程中的对象分布、实例数量及内存占用情况。
Jmap 排查内存问题的常见流程如下:
第一步:确认 FE 进程的 PID
ps -ef | grep StarRocksFE | grep -v grep
或
jps -l
第二步:通过 jmap 命令完成数据采样
jmap -histo > histo_1.log
sleep 60
jmap -histo > histo_2.log
通常可通过 jmap -histo 生成采样日志,间隔 60 秒连续采集两次。随后对比两份日志中的实例数量与字节数变化,判断对象占用是否持续增长。
第三步:必要时执行 Heap Dump,获取完整证据链
当 jmap -histo 无法准确定位问题时,可进一步执行 Heap Dump,并结合专业分析工具进行深度排查。
jmap -dump:format=b,file=/path/fe_.hprof
注意:谨慎使用 live 参数。
jmap -histo:live
jmap -dump:live,format=b,file=...
带 live 参数的命令会触发 Full GC,并可能导致 FE 进程短暂停顿。生产环境中应谨慎使用,建议在业务低峰期执行。
- FE Memory Tracker 观测
MemoryUsageTracker
是 FE 日志中的内存采样功能,v3.3.7 及之后版本支持。该功能会定期扫描已注册模块,估算各模块的内存占用与对象数量。
默认情况下,MemoryUsageTracker 每分钟采集一次,并将统计结果输出至 FE 日志。排查时,可通过 MemoryUsageTracker 关键字检索 FE 日志,查看相关采样信息与模块占用情况。

2025-06-06 16:37:50.667 INFO (MemoryUsageTracker|74) [...] Module TabletInvertedIndex - TabletInvertedIndex estimated 37.7MB of memory. Contains TabletMeta with 353459 object(s)... 2025-06-06 16:37:50.741 INFO (MemoryUsageTracker|74) [...] total tracked memory: 46.8MB, jvm: Process used: 18.6GB, heap used: 4.4GB, non heap used: 289.1MB, direct buffer used: 395.5MB
二、典型案例分析
案例一: Heap 配置不足导致 FE 集群不可用
- 环境背景
-
集群架构:3FE(3.3.14)
-
-Xmx 配置:8GB
-
机器内存:16GB
-
数据规模:Tablet 数量约 10W
- 问题现象
集群触发 FE 状态异常告警(Critical)。
该告警每 10 秒巡检一次 FE 状态,主要检查两项内容:
-
FE 查询端口是否可正常执行
SHOW FRONTENDS; -
FE HTTP 端口
/variable是否可访问,且返回内容非空
任一检查失败,该 FE 的失败计数加 1;当失败计数大于 3 时,触发 FE 状态异常告警。
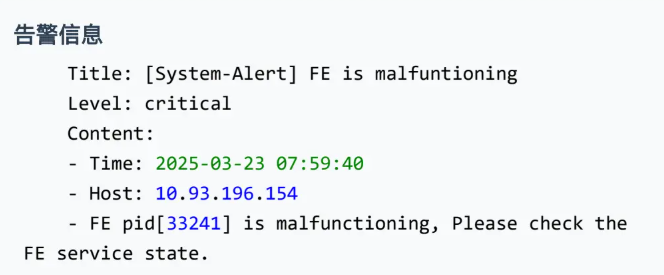
- Leader 节点
heap_used长期超过 90%;
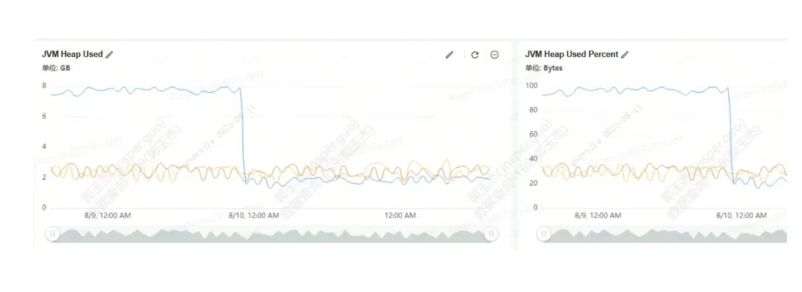
-
FE 日志中出现
Java heap spaceOOM 报错。 -
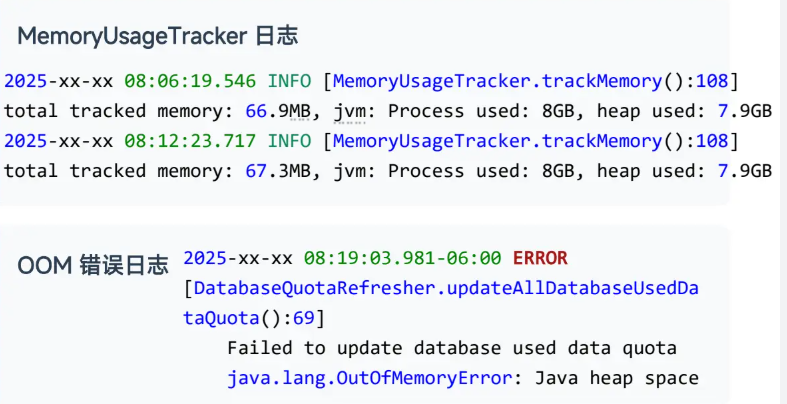
进一步检索 FE 日志中的
MemoryUsageTracker信息后,确认日志中存在 OOM 记录。
- 现场还原与问题分析
-
T+0: Heap 长期处于高运行状态, Leader 节点的 Heap 内存余量持续偏低。
-
T+1: SQL 查询执行过程中,内存占用继续上升,FE 内存压力进一步增大,并开始出现 Journal 提交失败。
-
T+2: FE 核心线程抛出
Java heap spaceOOM 异常。由于 FE 元数据依赖 BDBJE 维护,节点之间存在复制组与心跳机制。当 FE 发生 Full GC 或长时间进程停顿时,节点会暂时停止对外响应;若响应超时超过 BDBJE 心跳容忍时间,节点会被判定为不可用并标记为UNKNOWN,原 Leader 随后退出集群。 -
**T+3:**新 Leader 接管,集群恢复
- 处理方式
对 FE 节点进行内存扩容。建议 FE 节点机器内存至少配置为 16GB;本案例中,机器内存扩容至 36GB,并将 Heap 内存上限调整为 21GB。
- **排查思路:**围绕高峰期 Heap 内存余量展开
-
确认 FE 状态异常的具体表现:进程处于运行状态但服务无法正常提供。生产环境建议配置 supervisor 组件管理心跳服务,保障服务异常后可自动拉起。
-
排查节点日志,优先检查 Leader 节点的日志文件,通过检索关键字判断 FE 是否发生重启或切主行为。
grep -E "shutdown hook|FE ShutDown|will exit|StarRocks FE starting|Got role:|notify new FE type transfer" fe.log
- 根据关键字判断切主失败原因,快速锁定问题源头
grep -E "transferToLeader|failed to init journal after transfer to leader|InsufficientReplicasException" fe.log
- 查看 Heap 用量历史
grep -E "OutOfMemoryError|Java heap space|MemoryUsageTracker.trackMemory\(\):108" fe.log
案例二 :复杂 SQL 并发引发 Follower FE OOM
- 环境背景
-
集群架构:3 FE
-
机器内存:128GB
-
-Xmx配置:90GB -
集群版本:2.5.22
- 问题现象
-
Follower FE Hape 持续升高
-
FE 处理能力变慢
-
同步作业大面积延迟
-
重启后 Heap 再次升高
通过脚本获取 mem_profile 信息后,可以看到内存主要集中分配在表达式树、类型树与 Planner Thrift 结构中。这些对象通常在 FE 端执行 SQL 解析、分析与规划过程中生成,是本次内存占用升高的主要来源。
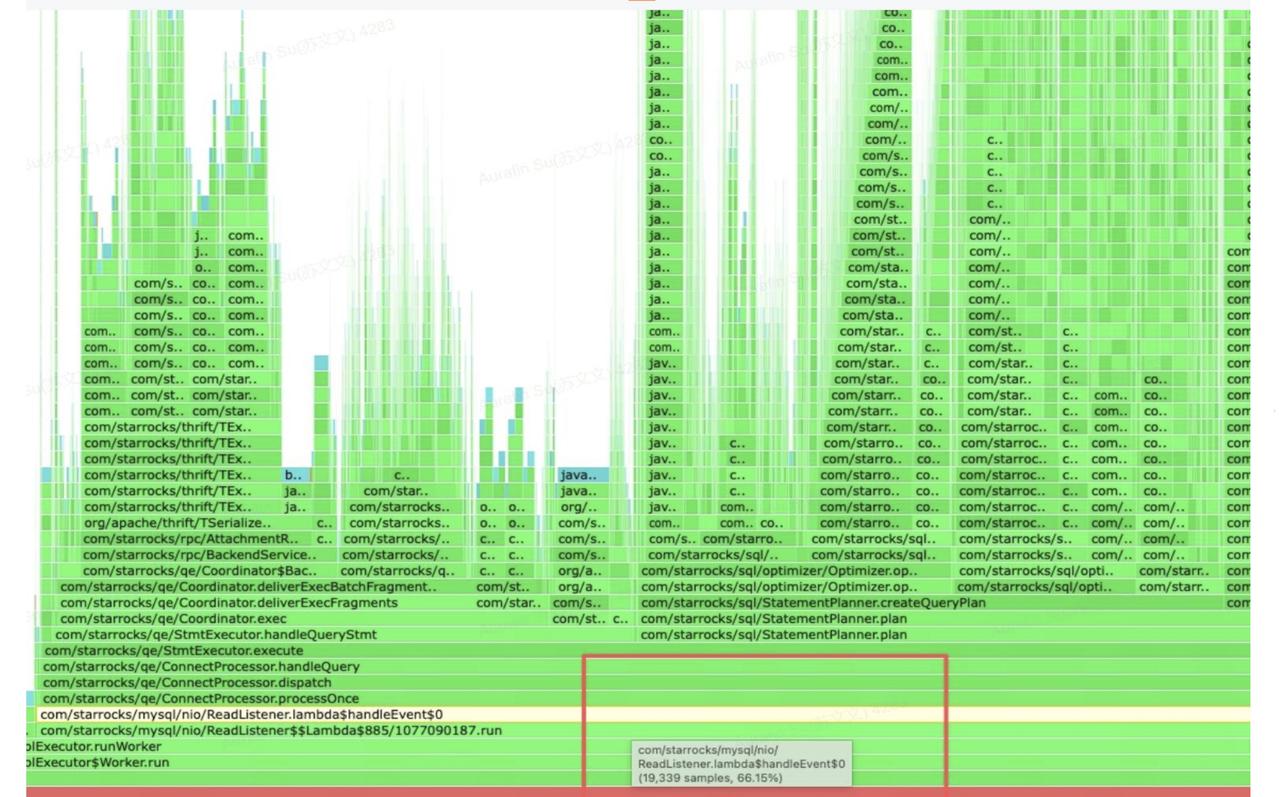
审计日志分析:由于当前版本尚不支持 queryFeMemory 字段,无法精确定位高内存 SQL。
结合审计日志与请求分布来看,问题节点承接了大量业务请求,其中高频执行语句主要集中在两类:复杂 INSERT ... SELECT 导入语句,以及复杂 LIMIT 0 探测查询语句。
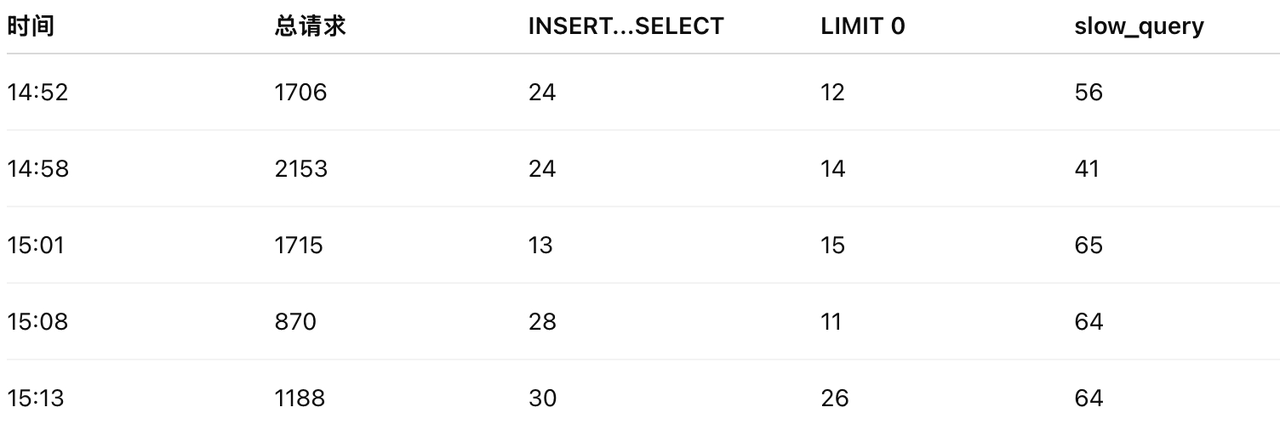
编写审计表查询语句,以分钟为单位聚合故障时段数据,确认两类语句在该窗口内集中执行。高请求量与大量复杂查询叠加,会持续抬高 FE 侧解析和规划阶段的内存占用。

- 解决方案:扩容内存

扩容后的集群恢复稳定运行,Heap 内存可在高峰时段实现正常回落。
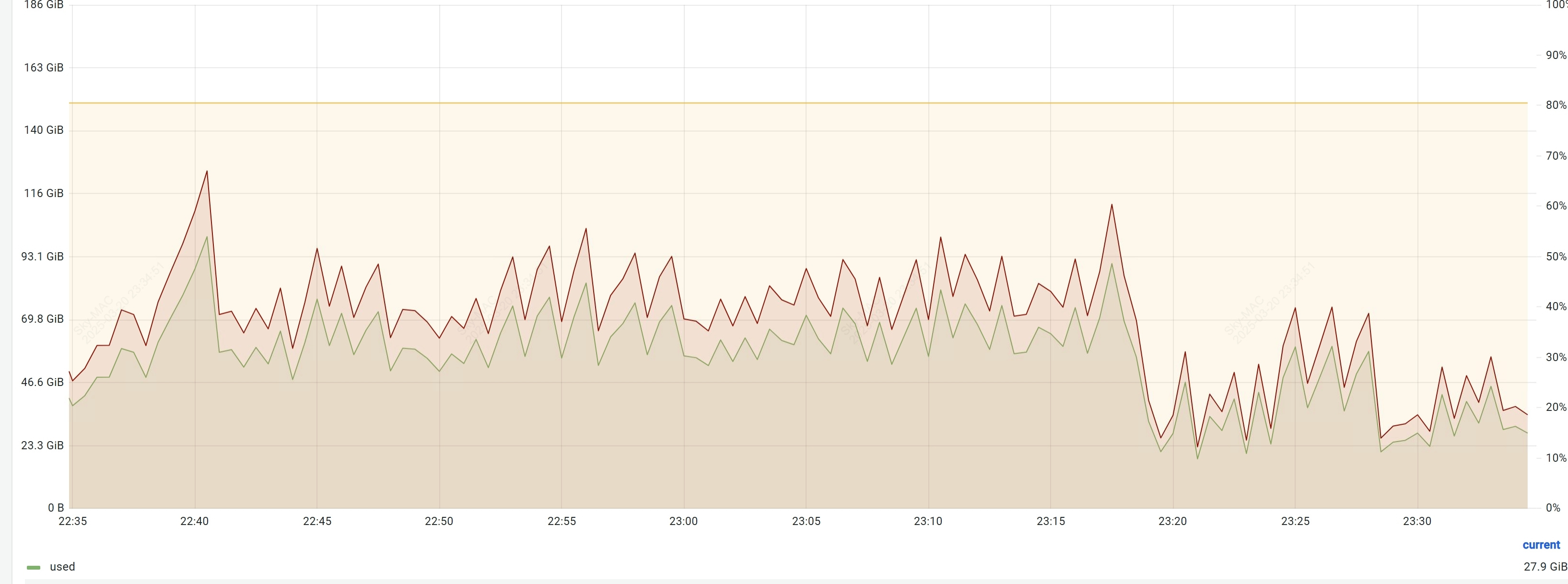
- 排查思路
-
查看 Heap 监控,锁定异常节点与故障时间窗口。
-
分析
mem_profile文件,明确内存具体分配方向。 -
结合审计日志,定位引发高内存消耗的 SQL 语句。高版本集群支持
queryFeMemory字段,可直接通过该字段筛选目标语句,提升定位效率与准确性。
案例三 :查询 Iceberg Catalog 外表导致 FE Full GC
- 环境背景
-
集群架构:3 FE
-
集群版本:3.3.13
-
机器内存:32GB
-
-Xmx配置:21GB
- 问题现象
-
Follower CPU 被打满
-
内存被打满
-
FE 进程 Hang 住;
-
GC 线程占满 CPU
在 CPU 高负载时段采集 jstack 信息后,确认资源占用主要来自 GC 线程,说明节点面临较大的内存回收压力。同时,jstack 中出现大量 sr-iceberg-worker-pool 热点线程,该类线程主要负责 Catalog 相关查询操作。
at com.starrocks.connector.iceberg.IcebergMetadata.collectTableStatisticsAndCacheIcebergSplit
at com.starrocks.connector.iceberg.IcebergMetadata.triggerIcebergPlanFilesIfNeeded
at com.starrocks.connector.iceberg.IcebergMetadata.getPrunedPartitions
at com.starrocks.sql.optimizer.rule.transformation.ExternalScanPartitionPruneRule.transform
at com.starrocks.sql.StatementPlanner.plan
at com.starrocks.qe.StmtExecutor.execute
排查发现,这几个线程栈均为访问 Iceberg Catalog 的线程,说明问题可能与 Iceberg Catalog 相关。
默认情况下,Iceberg Catalog Plan 线程数与 FE CPU 核心数一致。此前已建议用户将 iceberg_job_planning_thread_num 降低至 4,但问题仍然存在,需要进一步分析线程栈。
Catalog 创建语句:
catalog 配置如下:
CREATE EXTERNAL CATALOG prod_iceberg_catalog
PROPERTIES (
"aws.s3.access_key" = "xxx",
"aws.s3.secret_key" = "xxx",
"enable_iceberg_metadata_cache" = "false",
"aws.glue.use_instance_profile" = "false",
"iceberg.catalog.type" = "glue",
"type" = "iceberg",
"aws.glue.access_key" = "xx",
"iceberg_job_planning_thread_num" = "4" (默认fe cpu 核心数)
)
查看 fe.log 日志,锁定故障发生的时间窗口,发现对应时段内 memory tracker 记录的内存数据呈现持续升高趋势。

在审计日志中定位到 Iceberg 外表查询语句
select count(*) from prod_iceberg_catalog.dwd.dwd_test_iceberg ...
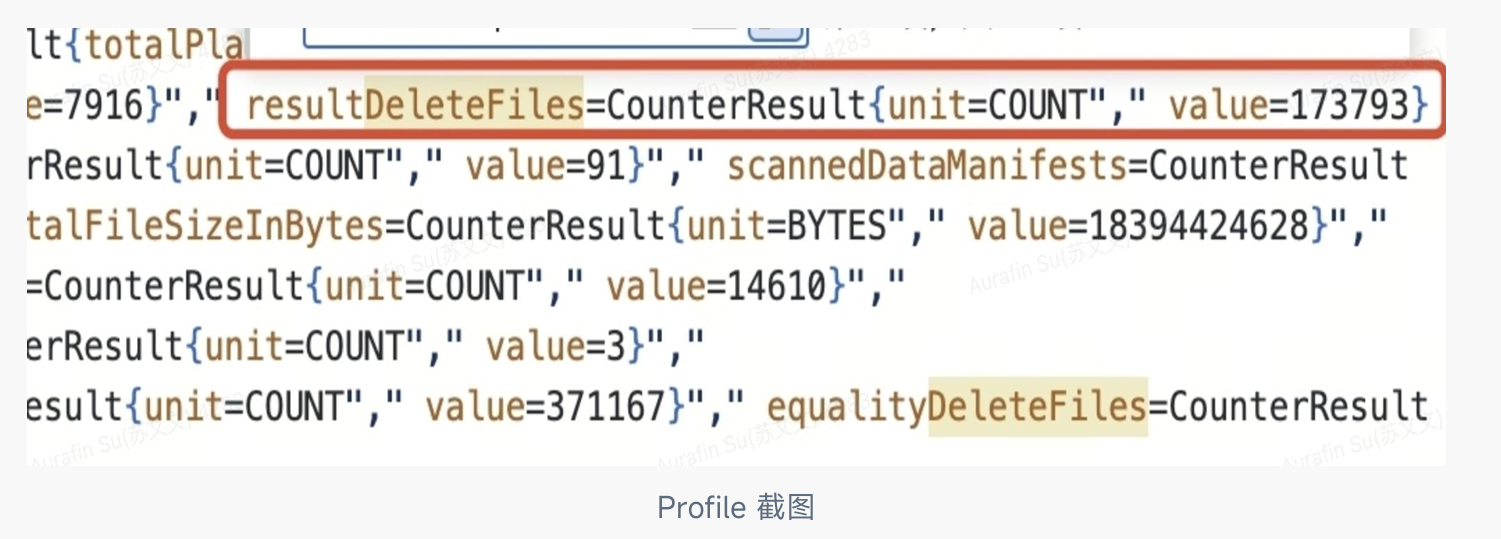
通过 Profile 发现,本次查询命中了 173,793 个 delete files。
delete files
是 Iceberg 在更新、删除数据时生成的一类增量删除文件。这些删除信息不会立即合并回原有 data file,而是先独立存储;通常需要在后续 Compaction 等整理过程中,才会与 data file 完成合并。
在查询阶段,FE 需要对这些 delete files 进行匹配与索引构建,从而显著放大 Planning 阶段的内存开销。
- 临时处理方案
-
重启异常 Follower 节点;
-
同时禁用问题 SQL
- 长期治理方案
-
定期执行 Compaction,降低 Planning 阶段负担;
-
可将
plan_mode调整为distributed,降低 FE 单节点 Planning 压力; -
如果版本较新(如 3.5.6+),可通过相关参数限制 Iceberg Cache 的内存使用。需要注意的是,这类缓存参数主要控制元数据缓存占用,并非 Planning 阶段的临时内存。
iceberg_data_file_cache_memory_usage_ratio=0.1
iceberg_delete_file_cache_memory_usage_ratio=0.1
- 排查思路
-
首先查看 Heap 监控与系统资源使用情况,确认是否存在明显 GC 压力。
-
结合 CPU 打满、服务 Hang 住等现象,及时抓取
jstack信息。 -
通过
jstack分析热点线程,结合日志定位具体 SQL,再通过 Profile 进一步确认问题来源。
案例四 :频繁建表、删表导致 FE 内存升高
- 环境背景
-
集群架构:3 FE
-
集群版本:3.1.13
- 问题现象
-
Leader CPU 持续增高;
-
Heap 持续增高;
-
重启后新 Leader 内存仍继续上涨。
使用 Arthas 工具观测堆内存后,确认当前内存占用处于较高水平。
进一步检索 FE 日志发现,在内存上涨阶段前,存在大量建表与删表操作,且删表操作均采用非 FORCE 模式执行。
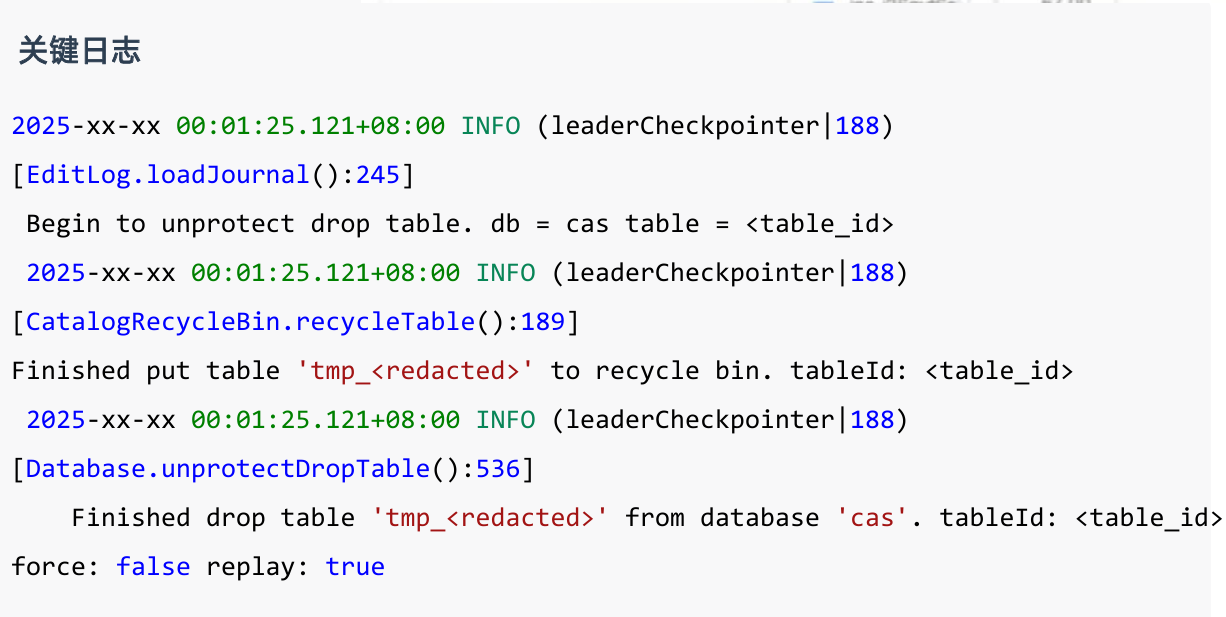
大量 DROP TABLE 操作的 force 均为 false。这意味着表被删除后,元数据会先进入回收站,不会立即彻底清理。随着元数据持续进入回收站并不断积压,FE Heap 占用被逐步推高。
- 恢复方法
-
停止相关 DDL 作业;
-
重启 FE 节点,恢复集群服务;
-
长期来看,应降低 DDL 操作并发量,减少临时表元数据堆积;
-
如果存在高并发 DDL 验证场景,建议使用
DROP TABLE FORCE或DROP PARTITION FORCE及时清理元数据。
案例五:MV 频繁刷新导致 Leader GC 退出切主
GC 分析与任务排查
- 环境背景
-
集群架构:3 FE
-
集群版本:3.3.14
- 问题现象
-
Leader 重启;
-
Heap 持续走高。
通过查看 MemoryUsageTracker 日志,可以清晰观察到 Heap 内存连续上涨的趋势。

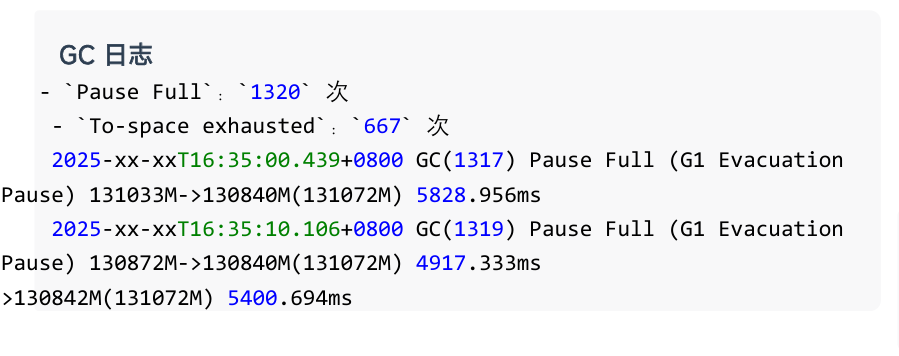
分析 GC 日志可见,节点触发了大量 Full GC。Full GC 执行过程中会显著影响进程响应效率,进而引发 BDB JE 复制心跳异常,最终导致 Leader 节点退出。
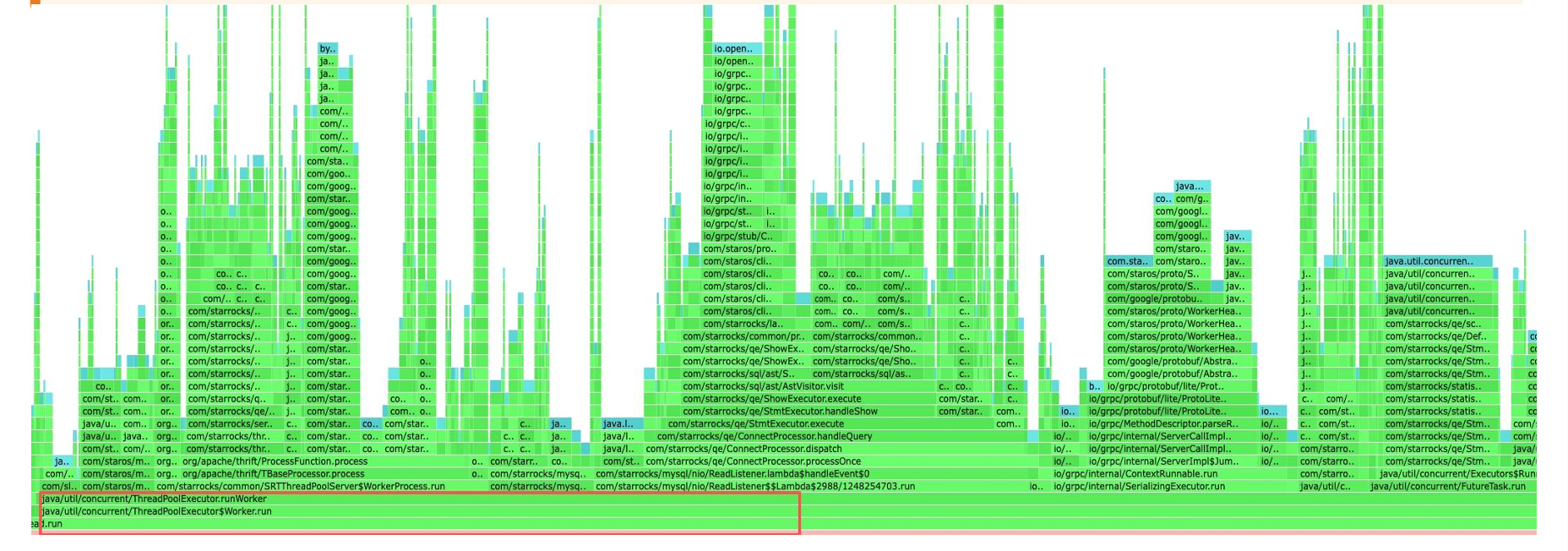
根据 mem_profile 数据发现,java.util.concurrent.ThreadPoolExecutor.runWorker 相关内存持续上涨,说明后台任务长时间运行并持续占用内存。这类后台任务通常包括用户提交任务以及 MV 刷新任务。
沿着这一方向继续排查 FE 日志,发现部分慢锁的 Owner 落在 starrocks-taskrun-pool 线程池。同时检查到 task_runs_concurrency 已被调整至 16,而默认值为 4,说明后台任务并发被明显放大。
结合任务类型判断,高并发后台任务大概率来自 MV 刷新。进一步统计 MV 刷新频率后发现,日志中存在大量 5 秒级高频刷新的 MV,且数量较多。
grep -c 'interval step to 5, timeunit to SECOND' fe.log
grep -c 'interval step to 1, timeunit to MINUTE' fe.log
grep -c 'interval step to 2, timeunit to MINUTE' fe.log
grep -c 'interval step to 1, timeunit to HOUR' fe.log
5 SECOND: 1873
1 MINUTE: 1033
2 MINUTE: 407
1 HOUR: 2437
也就是说,MV 刷新任务本身触发频率就很高,导致 task pool 长时间处于较大压力之下。
同时,从 MV 刷新任务日志可以看到,refresh 实际会走 INSERT OVERWRITE 链路;而这些 MV 又涉及 Catalog 外部查询,因此在刷新过程中,还会叠加查询规划阶段访问外部元数据的开销。
高频 MV Refresh 与外表元数据开销叠加,最终导致 FE 内存占用持续升高。
- 处理方案
-
降低 MV 刷新频率。
-
其他优化措施
下调
task_runs_concurrency参数,降低后台任务并发度;将秒级刷新调整为分钟级刷新,缓解任务线程池压力;
采用分区刷新模式;
降低单次刷新的资源消耗;
涉及 JDBC 外表等 Catalog 场景时,开启 Catalog cache 功能,减少元数据查询带来的内存开销。
- 排查思路
-
查看监控数据,确认 Leader 节点 Heap 内存持续处于高位;
-
查看 GC 日志,确认频繁 Full GC 且回收效率偏低的情况;
-
检索日志,重点关注
TaskRun、MV Refresh、慢锁等关键词; -
检查 MV 的刷新频率,定位后台任务的异常状态。
案例六:InsertLoadJob 内存泄漏
-
**触发场景:**客户集群主要以导入任务为主。
-
**问题现象:**FE 内存异常升高,进程重启,且未正常完成 Leader 切换。
对 Leader 节点进程导出 jmap 进行排查:
jmap -histo <FEpid> > jmap.txt # 该操作不会触发 Full GC
在导出文件中发现:
14: 521358 154321968 com.starrocks.load.loadv2.InsertLoadJob
从导出结果可以看到,InsertLoadJob 实例数量较多。进一步分析发现,导入任务事务在 callback 引用环节未完成清理,导致 InsertLoadJob 对象出现内存泄漏。
可通过以下命令查看对象实例数量:
jmap -histo <FEpid> > jmap.txt
一般情况下,InsertLoadJob 实例数量超过万级即可判定存在泄漏风险;若超过 50 万,可能引发严重内存问题。
- 问题版本:
-
3.1.0 ~ 3.1.16
-
3.2.0 ~ 3.2.12
-
3.3.0 ~ 3.3.7
-
修复版本:
3.1.17+
3.2.13+
3.3.8+
-
处理方式:
升级至对应修复版本后,可彻底解决该对象泄漏导致的内存异常问题。
相关链接:
Issue: github.com/StarRocks/starrocks/issues/53810
PR: github.com/StarRocks/starrocks/pull/53809
案例七:Replica 内存泄漏
- 版本范围:
该问题主要影响 3.3.13 ~ 3.3.18 版本。如果发现 FE Heap 内存持续缓慢增长,可能与该问题有关。
- 触发场景 :
-
大量
DROP操作; -
大量
SWAP操作; -
大量
INSERT OVERWRITE操作。
- 问题现象:
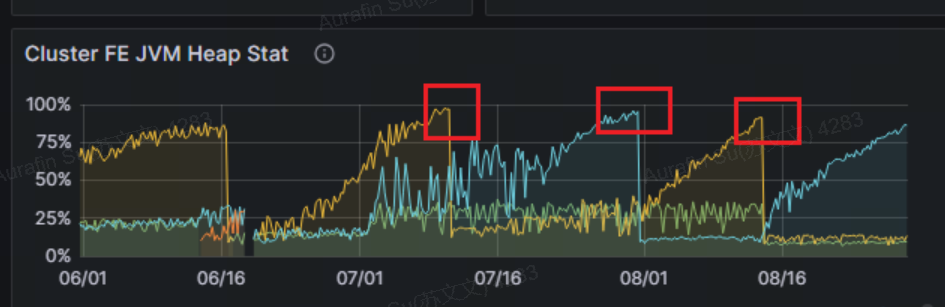
通过导出 jmap 分析发现,com.starrocks.catalog.Replica 对象占用内存过多。
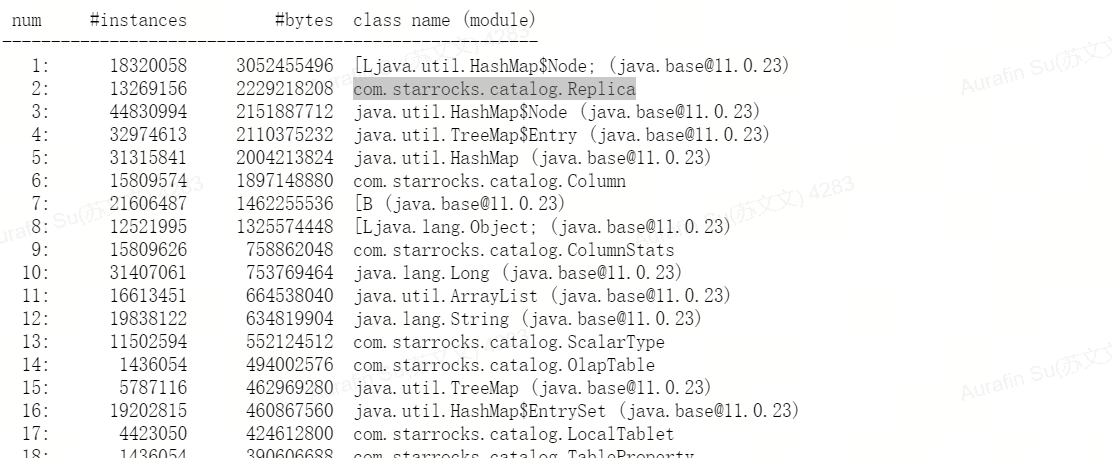
进一步排查确认,大量 DROP、SWAP、INSERT OVERWRITE 操作均可能触发该问题。
根因是 3.3.13 版本对 Tablet 删除路径进行优化后,引入了内存泄漏问题,并已在 3.3.18 版本修复。
-
3.3.13 相关优化 PR: [BugFix] Fix recycle bin missing to delete lake mv’s expired partitions after mv refreshed (backport
-
3.3.18 修复 PR:https://github.com/StarRocks/starrocks/pull/61582
- 处理方式:
临时规避:重启 FE 节点
- 根本解决:
- 升级至修复版本(3.3.18、3.4.7、3.5.4)。
Heap 问题排查思路
- 排查路径
-
先看监控,明确异常节点与时间窗口:例如哪台 FE 出现异常、问题从什么时候开始。
-
判断内存上涨类型
如果是突然上涨,优先查看 QPS、连接数、SQL 请求等监控指标,判断是否存在流量增长,并结合审计日志定位相关 SQL。如果是缓慢上涨,优先排查内存泄漏或缓存累积,可借助
mem_profile、jmap、jstack等工具,并结合日志分析对应操作。 -
根据问题类型做针对性处理
常用排查命令包括:通过 jmap -histo 查看对象分布,通过 jstack -l 抓取线程栈,通过 mem_profile 分析内存分配火焰图,并结合 grep 检索 OOM、Heap 等相关日志。
查看jmap
jmap -histo <pid> | head -n 30
获取线程栈
jstack -l > jstack.log
获取 mem_profile
fe/log/proc_profile/x
检索 OOM 日志等
grep -E "OutOfMemoryError|Java heap space" fe.log
需要注意的是,工具本身不是目的。它们的价值在于帮助排查过程逐步收敛,最终定位到具体节点、时间窗口、对象类型、线程行为或业务操作。
4.0 新特性: FE 内存实时估算 API
在 4.0 版本中,StarRocks 新增 FE 内存统计接口,可对当前内存使用情况进行采样估算,统计范围覆盖 FE 内部具体模块。发生内存异常时,可通过该接口获取实时内存占用信息,辅助定位问题。
核心能力
-
API 端点:
http://fe_ip:8030/api/memory_usage,仅允许127.0.0.1访问; -
基于 JOL(Java Object Layout)的对象图遍历与采样估算,对当前内存使用情况进行分析;
-
以 JSON 格式输出各模块的内存占用数据。

接口设置了安全访问限制,仅支持本机与本地 FE 调用。由于接口执行过程中会遍历 FE 内部对象,存在一定性能损耗,适合在内存异常时单次调用,不建议频繁使用。
特别提示与总结
async-profiler 可能引发 JVM Crash
触发问题前文提到的 mem_profile 基于开源工具 async-profiler 实现,用于采集内存火焰图。需要注意的是,async-profiler 同时也支持 CPU 采集;在少数场景下,CPU 采集可能引发 JVM Crash,导致 FE 进程直接退出。
- 典型现象
-
FE 进程崩溃或自动重启;
-
常规 FE 日志中没有明显异常信息;
-
FE 日志目录下生成
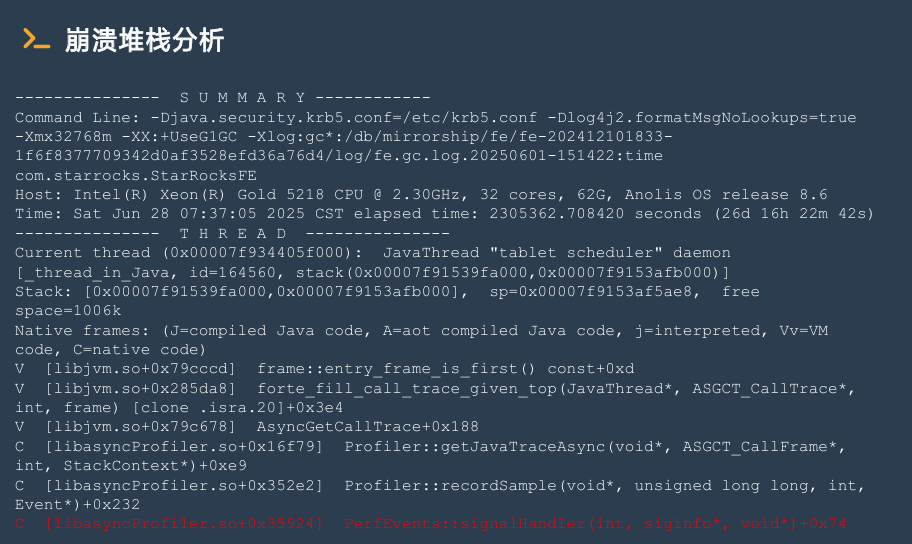
hs_err_pid*.log文件。
如果 FE 进程直接退出,而常规日志中没有明显报错,同时在日志目录下生成 hs_err_pid* 文件,通常可判定为 JVM Crash。该文件会记录完整的崩溃堆栈信息。若堆栈中出现指向 async-profiler 相关模块的异常调用链,则大概率说明本次 Crash 与采集工具运行异常有关。
- 处理方式
-
临时关闭 CPU 采集功能:
ADMIN SET FRONTEND CONFIG ("proc_profile_cpu_enable" = "false"); -
在
fe.conf中关闭配置(永久生效):proc_profile_cpu_enable=false
自 3.3.17 版本起,CPU 采集功能默认关闭;更早版本默认开启。
FE 堆外内存异常
- 问题现象
-
FE 所在机器整体内存持续增长,使用率超过 95%;
-
FE Heap 未明显上涨;
-
正常情况下,FE 进程总内存占用通常在
-Xmx的约 120% 范围内趋于稳定,但当前场景持续超出该范围。
- 典型表现:
机器整体内存持续攀升,而 FE Heap 指标变化并不明显,说明额外内存占用并非来自 JVM Heap,而是来自堆外内存或底层内存分配机制。
JVM 在运行过程中,会通过底层 glibc(GNU C Library)申请部分内存。自 glibc 2.10 起,引入了 Arena 多线程内存分配机制:系统会为不同线程维护独立内存区域。线程释放资源后,这些内存区域未必立即归还操作系统,进而形成内存持续占用的现象。
 参考文档 https://www.easyice.cn/archives/341
参考文档 https://www.easyice.cn/archives/341
- 处理方式
-
配置 MALLOC_ARENA_MAX
MALLOC_ARENA_MAX = 1,限制 glibc Arena 创建数量 -
配置步骤
在 fe.conf 中以大写格式添加对应配置项
对 FE 节点执行滚动重启
- 注意事项
该调整可能对部分业务性能产生影响,建议重点观察 P99 延迟 指标。若出现 P99 升高,可结合 Leader 切换后继续观察整体性能变化。
事前 chekclist
集群运维需要在日常阶段完成前置部署与配置。
-
完整配置监控体系与日志服务,确保 Heap 监控与 GC 日志持续采集,为事后定位与现场还原提供依据。
-
提前搭建日志与证据链体系。建议前置部署审计日志插件,便于后续问题追溯;出现 OOM 异常时,可通过专用配置在进程宕机时自动生成 Dump 文件,留存关键分析数据。
-
确保
jmap、jstack、mem_profile等分析工具可用,满足突发问题排查需求。 -
结合集群规模开展容量规划,持续关注 Tablet 数量与元数据增长趋势,并根据业务规模及时推进 FE 节点扩容。
应急响应流程
故障发生时,首要任务是保护现场,为后续排查留存关键证据。
如果 FE 进程出现 Hang 住、无响应等情况,应第一时间采集 jstack 信息,用于捕捉异常堆栈、分析问题根源。一旦直接重启 FE 节点,堆栈与线程相关信息会丢失,影响故障现场还原。
如果怀疑 Heap 过高或 OOM,可通过 jmap -histo 获取内存对象快照,留存对象分布与占用数据。需要注意的是,添加 live 参数会触发 Full GC,可能加重节点压力,生产环境需谨慎使用,建议在业务低峰期执行。
完成 jstack、jmap 等证据采集后,再进行节点重启、扩容等处置操作,并基于留存证据判断问题类型,开展针对性处理。
若判定为对象泄漏类问题,需通过版本升级完成修复;若发现 QPS、连接数异常,则需排查业务请求合理性,必要时执行限流或调整业务并发,缓解节点资源压力。