为了更快的定位您的问题,请提供以下信息,谢谢
【详述】
大佬,
- 帮忙排查下 21日还没有平衡完,主要原因是什么?
- 帮忙排查下 21日 大表 ods_fact_event_user rename 成 ods_fact_event_user_bak_20260417 之后,balance 一直不成功的原因?
存算一体集群,原本有5台be,tablet 原先在 410w左右,3月31日新增了3台be,到4月21日,老的be 350w左右,新的 150w左右。一直都27日也没啥变化,tablet一直没有平衡,而且21日之后发现be会有一些 clone failed 报错,tablet 指向的是一个没有分区的大表(4.5TB), 但是21日的时候平衡基本属于停滞状态。
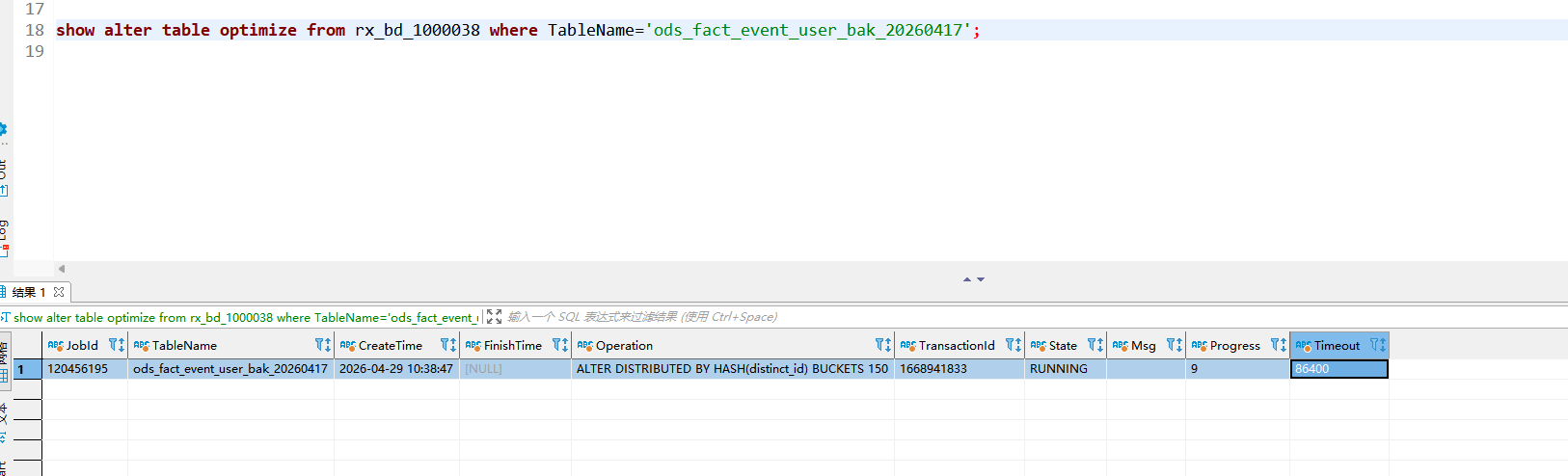
大表:ods_fact_event_user_bak_20260417 的 tablet 查询结果

参数目前的设置情况:
tablet_sched_disable_balance = false
tablet_sched_balance_load_disk_safe_threshold = 0.1
tablet_sched_balance_load_score_threshold = 0.01
schedule_slot_num_per_path = 16
tablet_sched_max_scheduling_tablets = 15000
tablet_sched_repair_delay_factor_second = 30
parallel_clone_task_per_path = 16
麻烦排查下是什么问题?
【背景】无
【业务影响】
【是否存算分离】
【StarRocks版本】存算一体 3.2.12-3faf7d4
【集群规模】3fe + 8be
【机器信息】fe 96c/374g be 32c/247g
【附件】
fe日志:
felog.7z (20.3 MB)
be日志:
felog.7z (20.3 MB)
be warring 日志:
felog.7z (20.3 MB)
be.INFO 我们保留的太短,日志还挺多,看下是否可以看出问题?