

作者:作业帮大数据团队(覃争、孙建业、刘泽强)
作业帮的 Presto 主要承载即席查询场景,天级查询规模在 2000~5000 次 ,但均值耗时在分钟级,整体性能偏慢;同时由于与 Yarn、HDFS 混部,高峰期宿主机 CPU 经常打满,资源争抢严重,查询体验波动明显。
此外,老版本 Presto 对 Iceberg 支持有限。基于团队在 toB OLAP 场景中长期使用 StarRocks 的经验,以及其在复杂查询性能、Iceberg 原生支持和存算分离方面的优势,团队通过平台适配、语法兼容和双跑校验,完成了 Presto 到 StarRocks 的平滑迁移。
迁移完成后,整体收益显著:资源占用从约 4300 核降至 1000 核 , P90 查询耗时缩短 2~3 倍 ,同时实现多集群向统一架构的收敛,为后续弹性扩缩和资源统一调度打下基础。
技术方案
StarRocks 采用全面向量化引擎和基于 CBO 的智能查询规划,在复杂的多表关联查询场景下性能表现很好,同时原生支持具备 Iceberg 查询能力,社区成熟技术迭代快。同时在存算一体场景采用 StarRocks 已有很多经验,所以采用 StarRocks 替换 Presto。为避免业务扰动且收益正向,核心是平台层面架构适配、解决语法兼容性和性能优化、任务迁移。
整体架构
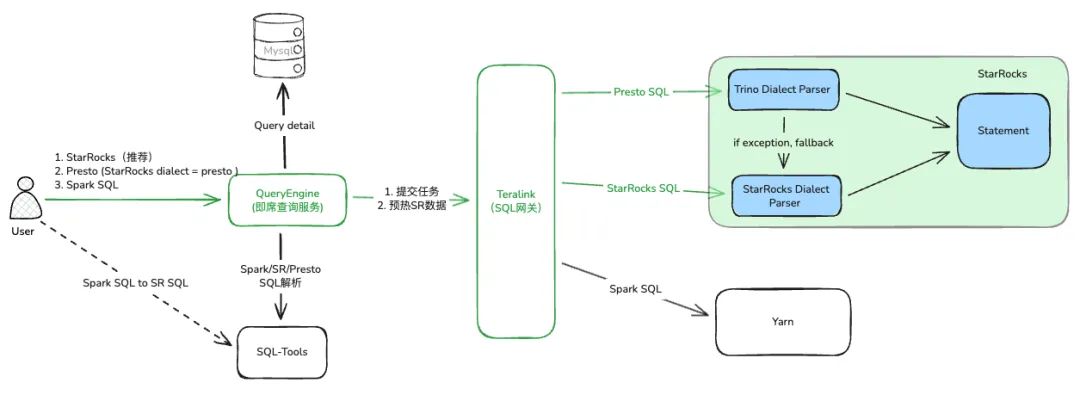
即席查询整体架构如下图。用户通过数据平台编辑 SQL 任务,提交给 QueryEngine 即席查询服务(任务管理、语法校验、结果脱敏、日志可读性转换等等),再由 QueryEngine 提交给计算网关 Teralink(权限认证、审计、分发、引擎入口收敛等),Teralink 根据具体执行引擎提交给集群。StarRocks 采用存算分离模式部署,利用 Catalog 查询 Hive、Iceberg 数据。考虑到长期 StarRocks 和 Spark 基于 k8s 弹性,做了容器部署。为避免业务扰动最大化兼容 Presto sql 语法,详细内容见下文。在 StarRocks 内部解析异常时也可以回退到 StarRocks Dialect Parser 起到一定补充作用。
在迁移方案时,为了保障稳定和数据准确,在 QueryEngine 这层做了防御措施。当使用 StarRocks 集群查询失败后回退到 Presto。在准确性方面,根据已有双跑结果建立 StarRcoks SQL 指纹库,指纹库以外的查询 diff 数据结果,数据准确完善指纹库信息,预期之外情况人工介入解决。
双跑方案
资源节省的角度考虑,我们没有将 Presto 和 StarRocks 的资源打平,而是 Presto 利用现有集群,StarRocks 利用测试小集群,资源情况如下:
- Presto 混布以单节点可用最大内存、cpu 内存比为 1:3.5 计算,其中一个集群大概 2500 多核(白天 cpu 有空闲)
- StarRocks 资源情况 6 CN * 32 核 = 192 核
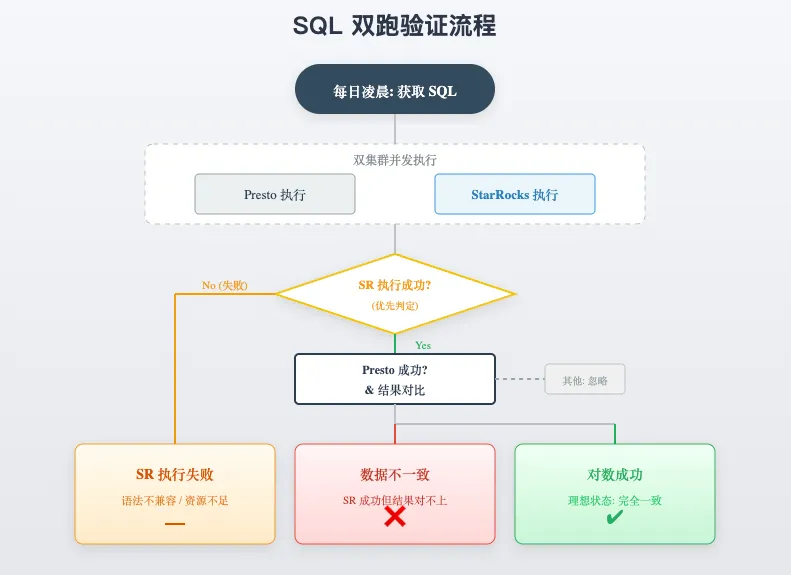
- 在业务低峰期针对近 N 天的查询进行双跑。大概步骤如下
- 过滤出 Presto 执行成功的 SQL,先 explain,explain 不通过的跳过,并记录;
- 双跑串行查询(StarRocks 多次),记录数据、耗时等信息;
- 分析耗时、利用 sum(hash(column)) 对比结果数据;
结果分析
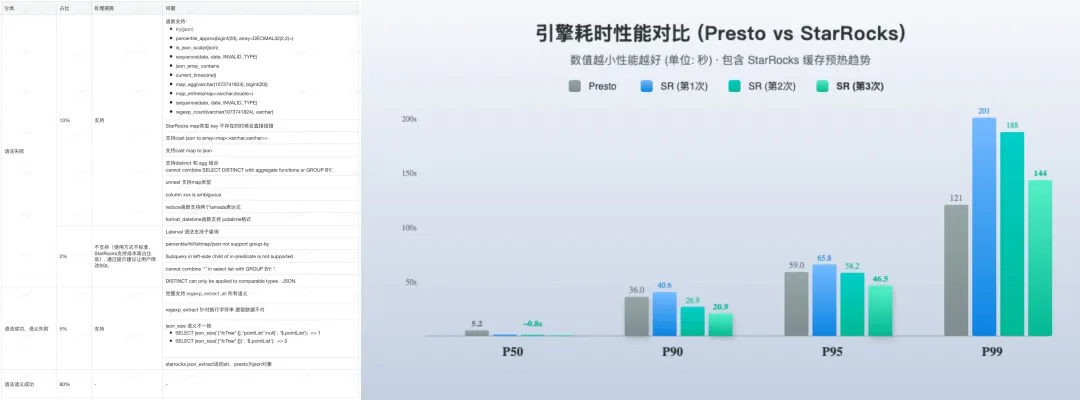
兼容结果:通过 3 个多月的数据验证 diff,遇到主要问题如下,大多数通过改造解决,少数开发成本高且使用率低的通过报错后给替代方案解决。
性能结果:StarRocks 的整体性能符合预期,缓存以后查询性能也有明显的提升。
缓存加速
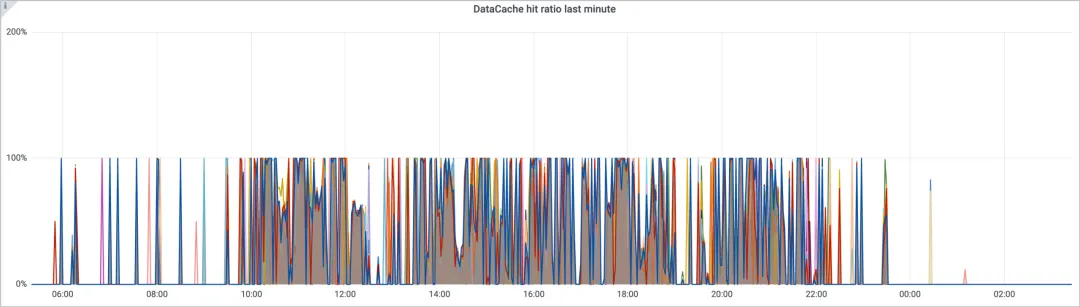
历史因 Hive 数据存储和计算 cpu 增长不成线性比例,用 Cos 替换了 HDFS,做了离线场景的存算分离。查询远端 cos 数据与 StarRocks data cache 数据时,性能上还是有很大差距的,Cos 内部并没有数据格式的概念,查询引擎很难利用 parquet 格式特殊性实现 data pruning,加上网络请求的耗时,查询速度会有衰减。为了尽可能提高查询效果,我们会利用 SQL 解析获取最近 N 天查询过的表,监听这些表新增分区,自动触发查询进行数据缓存,命中率情况如下图。
分析 data cache 的原理,缓存文件由 CN 节点个数、Host Ip 和 Port 决定的。在 K8S 上 StarRocks CN 节点采用的是 StatefulSet 方式进行部署,虽然我们目前还没有走弹性扩缩的逻辑,但是 StarRocks CN Pod 的重启 / 重建也会影响 data cache 的分布。因此我们目前的部署采用的是:固定资源池 + Pod 滚动重启 / 重建 + Pod 规格基本用满一个节点 组合的方式,来控制 pod 不会发生漂移。后面待云上能力支持完善后, 我们会采用 Local PVC 的方式来防止 Pod 漂移,同时考虑引入 StarRocks 4.0 新增的缓存共享能力。
核心问题
平台语法解析慢问题
- 问题背景:平台侧是 explain 来实现语法检测的,Presto 基本秒级返回,StarRocks 耗时比较久,有的甚至超过 30s ~ 1min
- 原因分析:explain 过程包含多个阶段 Parse、Analyze、Logical Plan、SQL Optimize、 生成 Plan Fragment。分析 Profile 发现耗时主要在 SQL Optimize 阶段,RBO/CBO 获取查询源信息阶段。StarRocks 现有的 explain 能力不支持跳过 SQL 优化阶段
- 解决方案:调整 SQL 为 explain select * from( {user_original_sql} ) where 1!=1
Cancel 查询无效
- 问题背景:除了 StarRocks、Presto 外还有长时运行的 Spark 任务,平台侧提供了运行中任务取消能力;
- 原因分析:实际上是 2 个问题在 Teralink(基于 Kyuubi 二开)中,JdbcSQLEngine 通过调用 MySQL Statement.close() 来处理 cancel 请求。但由于 Statement.close() 需要获取一把 Statement 内部操作锁,而该锁只有在 SQL 执行结束后才会释放,导致 cancel 请求被阻塞,直到 SQL 执行完成,从而无法真正中断正在运行的 SQL。MySQL Statement cancel 会新创建一个 connection,而 StarRocks 对外暴露的是 LB, 默认没有开启会话保持,新建 connection,会路由到不同的后端 FE 上
- 解决方案:对 JdbcSQLEngine 进行了调整,在 JdbcDialect 中引入 cancel 方法,并在 cancel 流程中先 cancel Statement 的执行,再进行 close,以确保 SQL 能够被 kill因 LB 开启会话保持会导致 FE 请求不均、某些查询时间比较长,超过保持时间同样有问题。在 Teralink 这层针对 cancel 设置重试策略,检测到相关错误,继续重试 cancel,并设置重试上限;
Iceberg 表缓存导致 FE OOM
- 问题背景:查询 Iceberg 表时,FE 内存变化较大,偶发 OOM 导致 pod 重启
- 原因分析:查询 Iceberg 表时大概逻辑为 1. 先检测 metadata.json 文件更新时间判断缓存是否过期。2. 如果过期则拉取对应 snap 文件并获取到 m0 文件列表。3. 解析 m0 文件列表定位数据文件。 当 Iceberg 表比较大或者频繁更新时产生很多 m0 文件,第 2 步内存 fe 内存会缓慢增加,第 3 步 fe 内存会剧烈增加,引起 FE OOM 问题
- 解决方案:关闭 iceberg 表元数据缓存、利用 starrocks 自身 skip manifest 文件的能力在查询时快速进行分区过滤并定位 m0 文件;
iceberg 表 plan_mode = distributed 报错
- 问题背景:starrocks 在使用分布式模式解析 iceberg 表元数据时会把虚拟的 metadataTable 当成 hive 表再去 metastore 获取元数据而报错
- 原因分析:iceberg 表生成执行计划有两种方式。本地模式,使用 fe 进行 metadata.json + snap.avro + m0.avro 文件解析。分布式模式,预设一个 metadata 表及其表结构并把 iceberg 表的元数据 avro 文件当成 hive 普通表的 avro 文件利用 cn 分布式处理。StarRocks 采用的是自动选择模式,根据所需扫描的 m0 文件的总大小及数量进行选择。当选择 distributed 模式时会稳定报错,因为在权限验证阶段会强制从 metastore 获取 metadata 表元数据
- 解决方案:修改代码,如果检测到表类型是 iceberg 表的虚拟元数据表,即 metadataTable,则不进行元数据获取
multi_distinct_count 执行慢问题
问题背景:当 sql 含有多个 count_distinct 表达式,单 CN 节点内存使用极高、cpu 空闲、执行速度慢,无法多并发执行;
原因分析:当查询包含 count_distinct 时,StarRocks 会有些内部判断逻辑
- 如果数据量很大的情况下,分出多个数据流分别进行 streaming aggregate 最后 nestloop join 成单条
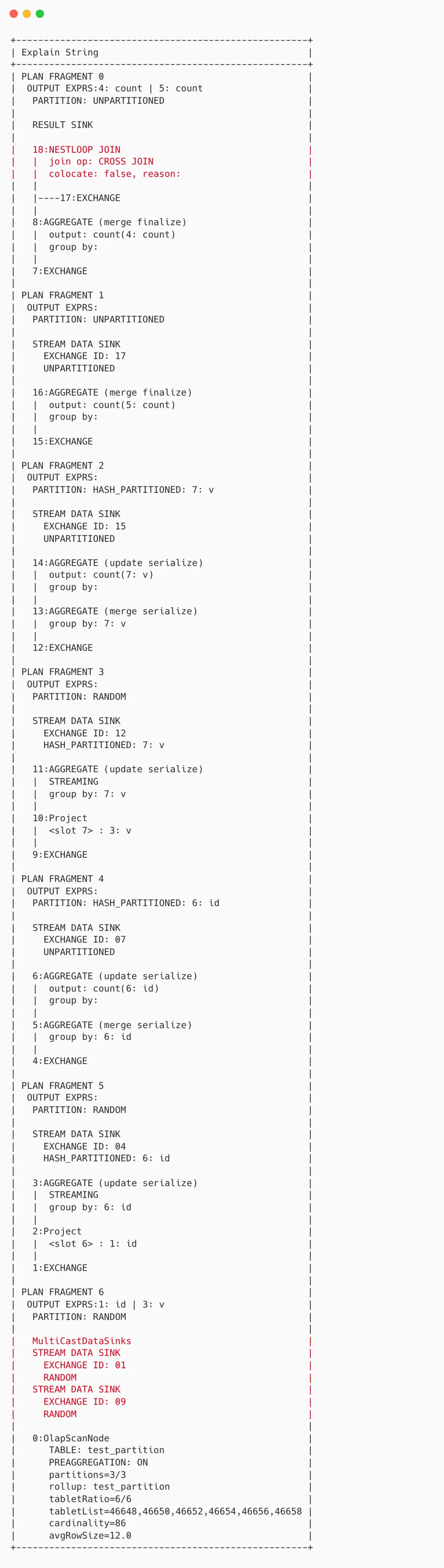
- 如果数据量小且列基数都低,重写成 multi_disticnt_count 函数单点执行
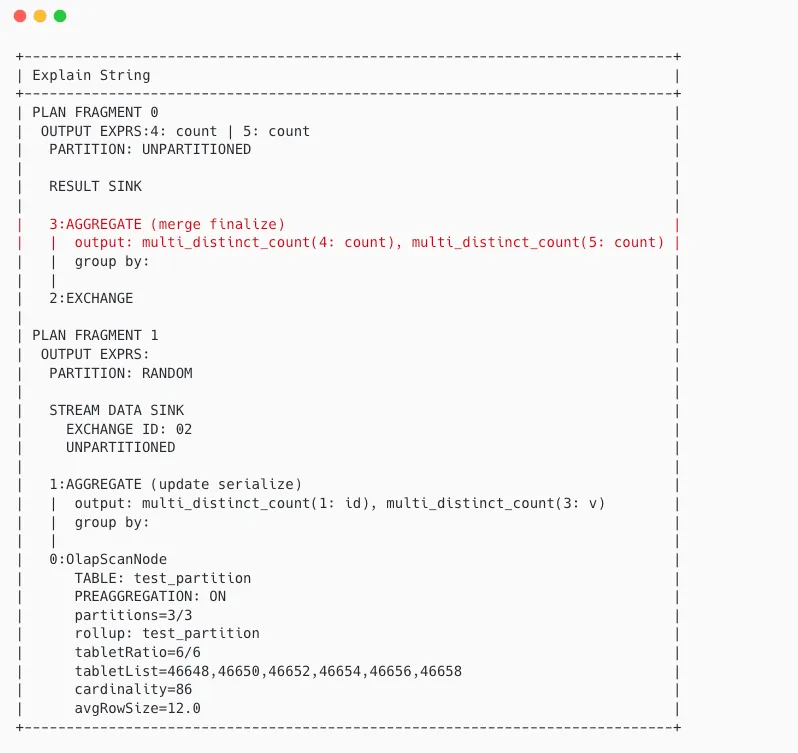
- 当统计信息缺失则可能误判,也就是在数据量很大时误用 2,导致问题。
解决方案:由于不是所有表都具有完整统计信息,所以禁止 multi_disticnt_count 优化 set global prefer_cte_rewrite=true,放弃小查询性能收益,保障整体查询速度稳定
执行计划生成耗时长
问题背景:StarRocks 为生成更优的执行计划而在 plan 阶段会做更加详细的统计信息收集,导致 plan 阶段时间长,而且为保证数据准确性我们关闭了 fe 文件元数据缓存
原因分析:抽取具体 SQL 分析 trace times(见下图)。在 hive 表统计信息缺失时,优化器会获取全量文件列表推导统计信息,hive 表文件过多会导致在 rbo 阶段速度很慢。
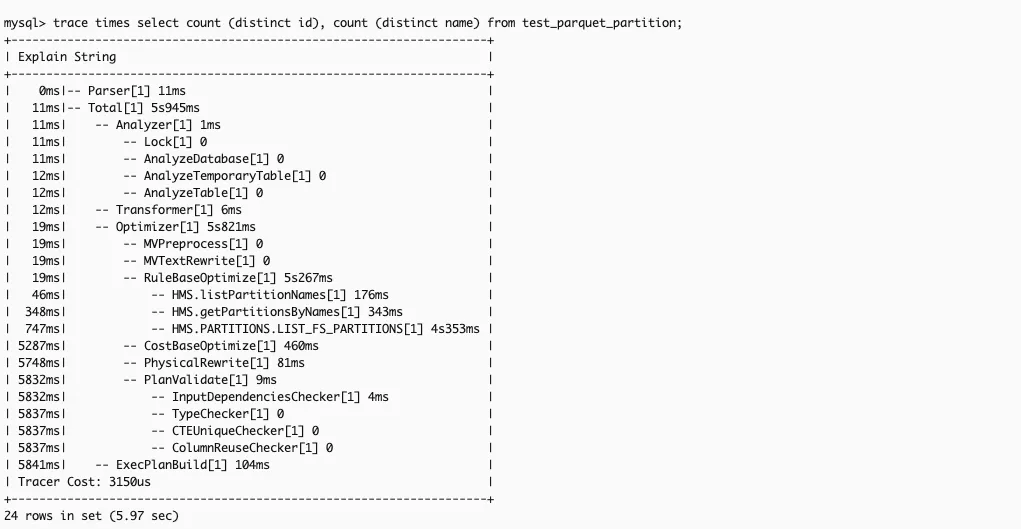
解决方案:增大 async_refresh_max_thread_num 到 128,以 128 线程并发获取分区的文件列表。默认超时时间在存算分离查询数据湖场景偏低,加大 set global new_planner_optimize_timeout=60000 缓解
limit 方式限制返回条数导致结果乱序
问题背景:为限制 sql 返回数据条数,代理层会默认在原始 sql 外层嵌套一层 limit 表达式
原因分析:增加 limit 后分析 explain,因为外层没有排序条件而被判定内层的排序条件误用,所以内层的 order by 被删除导致查询结果不符合预期。
解决方案:设置 global sql_select_limit = n,在原有执行计划树添加一个 TOP-N Node 解决。

中间结果落盘导致 CN core dump
问题背景:为缓解查询内存不足问题开启中间结果落盘,但 spill 过程中偶发 core dump
原因分析:中间结果落盘时如果数据过大会触发限制导致 cn 进程 core dump

解决方案:修改代码,当批数据过大则不走 lz4 压缩,直接落盘‘
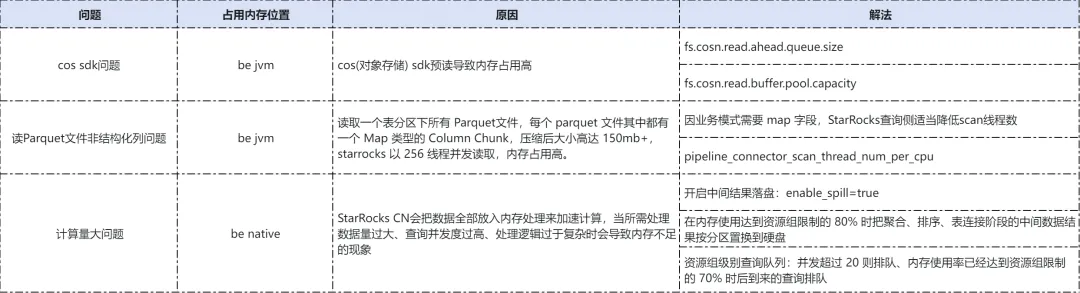
CN 内存不足
线上整体采用 32c * 128G 规格的机器,大概 30 多台,数据量 PB 级,最大并发 30。偶尔会出现 StarRocks CN 节点内存过高,导致 Full GC 和 pod 被 kill 问题。内存问题总体比较复杂,从实际运行情况看并非单一原因。CN 节点整体内存占用情况如图。 详细原因和解决方案如下
项目收益
项目上线后,整体已运行平稳,主要有三方面的收益。
- 资源收益:原来 Presto 集群总共占有 4300c 左右的资源,迁移到 StarRocks 上,我们只用了 1000c 的资源。
- 架构收益:多个 presto 集群统一为一个 StarRocks 集群,容器部署同时为后续与 Spark 弹性扩缩提供基础。
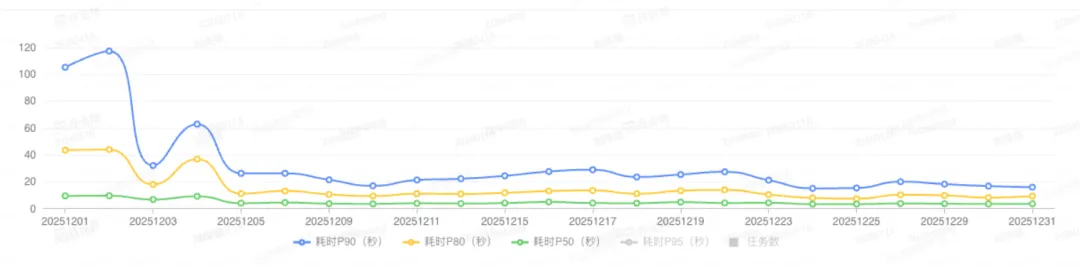
- 性能收益:P90 耗时查询相对 Presto 缩短 2 ~ 3 倍
未来计划
- 自动将即席查询 Spark SQL 转化为 StarRocks SQL,加快查询速度;
- 白天即席查询 StarRocks 和晚上例行 Spark 任务资源弹性;