为了更快的定位您的问题,请提供以下信息,谢谢
【详述】问题详细描述
【背景】做过哪些操作?
【业务影响】
【是否存算分离】否
【StarRocks版本】例如:3.1.17
【集群规模】例如:3fe(1leader +2follower)+6be(fe与be混部)
【机器信息】CPU虚拟核/内存/网卡,例如:64C/378G/万兆
【联系方式】邮箱lile21@xdf.cn
【附件】
- fe.log/beINFO/相应截图
【问题描述】:
1、2026-02-23 18:04:00 be节点异常crash、be.out日志如下
query_id:00000000-0000-0000-0000-000000000000, fragment_instance:00000000-0000-0000-0000-000000000000
tracker:process consumption: 142331028816
tracker:query_pool consumption: 13146297
tracker:load consumption: 0
tracker:metadata consumption: 1700685548
tracker:tablet_metadata consumption: 127937606
tracker:rowset_metadata consumption: 244722796
tracker:segment_metadata consumption: 149318379
tracker:column_metadata consumption: 1178706767
tracker:tablet_schema consumption: 5335590
tracker:segment_zonemap consumption: 66086833
tracker:short_key_index consumption: 73143241
tracker:column_zonemap_index consumption: 290748207
tracker:ordinal_index consumption: 617964752
tracker:bitmap_index consumption: 3200
tracker:bloom_filter_index consumption: 0
tracker:compaction consumption: 873767096
tracker:schema_change consumption: 0
tracker:column_pool consumption: 5624872535
tracker:page_cache consumption: 43153753232
tracker:update consumption: 75652500215
tracker:chunk_allocator consumption: 2148531232
tracker:clone consumption: 0
tracker:consistency consumption: 0
tracker:datacache consumption: 0
tracker:replication consumption: 0
*** Aborted at 1771841184 (unix time) try “date -d @1771841184” if you are using GNU date ***
PC: @ 0x337ba04 starrocks::ZoneMapPB::~ZoneMapPB()
*** SIGSEGV (@0x55717) received by PID 195497 (TID 0x7fdc7e9fe700) from PID 349975; stack trace: ***
@ 0x688b642 google::(anonymous namespace)::FailureSignalHandler()
@ 0x7fdfff2125f0 (unknown)
@ 0x337ba04 starrocks::ZoneMapPB::~ZoneMapPB()
@ 0x572b713 starrocks::ColumnReader::~ColumnReader()
@ 0x526d299 starrocks::Segment::~Segment()
@ 0x598790a starrocks::Rowset::do_close()
@ 0x517fcb1 starrocks::Rowset::close()
@ 0x5228f6f starrocks::TabletUpdates::_do_compaction()
@ 0x522ad2c starrocks::TabletUpdates::compaction_for_size_tiered()
@ 0x522b7ea starrocks::TabletUpdates::compaction()
@ 0x516c70b starrocks::StorageEngine::_perform_update_compaction()
@ 0x50fe7e4 starrocks::StorageEngine::_update_compaction_thread_callback()
@ 0x8cca900 execute_native_thread_routine
@ 0x7fdfff20ae65 start_thread
@ 0x7fdffe60c88d __clone
@ 0x0 (unknown)
2、手动恢复节点后,有4个flink实时写入表报错
fe日志报错:
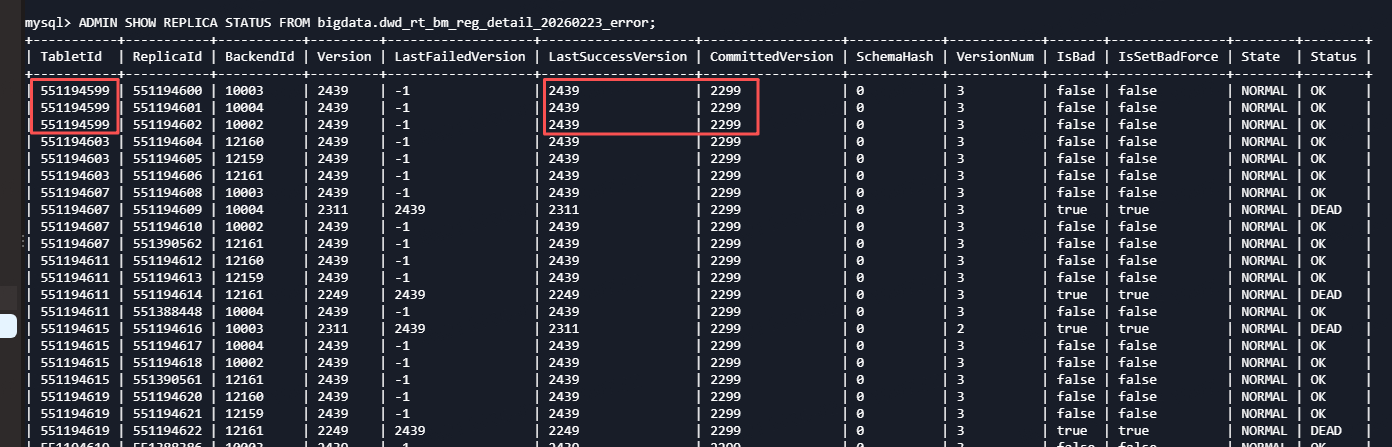
Caused by: com.starrocks.common.UserException: Failed to get scan range, no queryable replica found in tablet=551194599 replica=10003:2439/-1/2439/2424:NORMAL:ALIVE,10004:2439/-1/2439/2424:NORMAL:ALIVE,10002:2439/-1/2439/2424:NORMAL:ALIVE, schema_hash=261007876 version=2299
查询返回报错:
Build Exec OlapScanNode fail, scan info is invalid
3、ADMIN SHOW REPLICA STATUS FROM table;发现version_error的tablet,使用如下命令set bad
ADMIN SET REPLICA STATUS PROPERTIES(“tablet_id” = “”, “backend_id” = “”, “status” = “bad”);
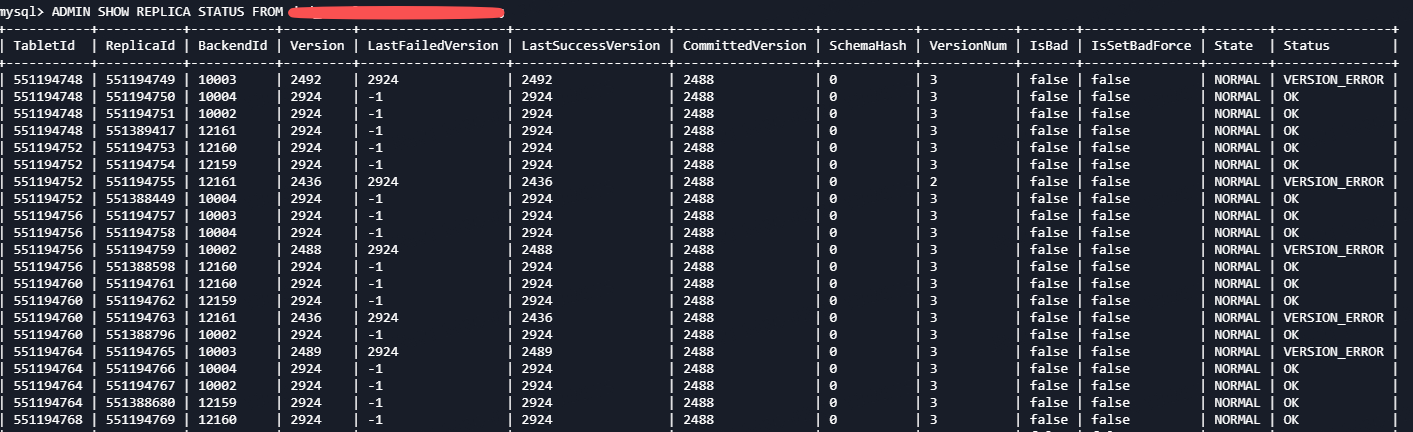
4、操作后,表仍然无法访问,查询日志报错
Caused by: com.starrocks.common.UserException: Failed to get scan range, no queryable replica found in tablet=551194599 replica=10003:2439/-1/2439/2424:NORMAL:ALIVE,10004:2439/-1/2439/2424:NORMAL:ALIVE,10002:2439/-1/2439/2424:NORMAL:ALIVE, schema_hash=261007876 version=2299
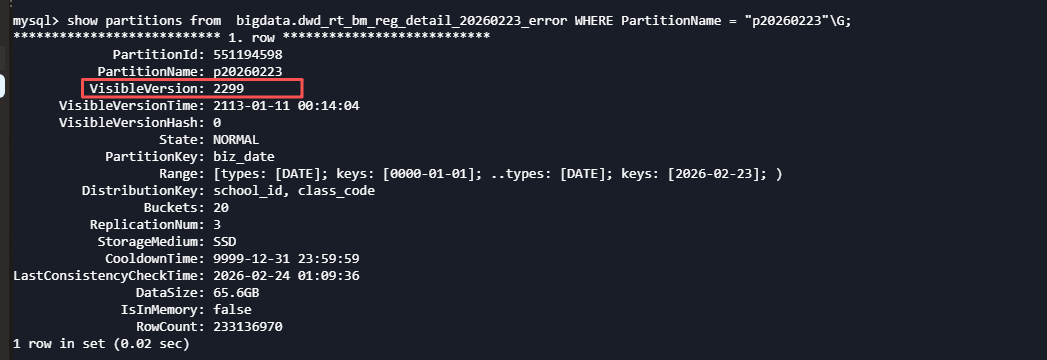
显示报错的tablet 状态是ok的,但version、LastSuccessVersion比CommittedVersion大很多;想了解下产生问题的原因,以及如何解决?
show partitions from table where partitionname=’’;
ADMIN SHOW REPLICA STATUS FROM table;