为了更快的定位您的问题,请提供以下信息,谢谢
【详述】SELECT t0.exp_id AS exp_id, t0.grp_id AS grp_id, COVAR_SAMP(COALESCE(t0.zi, 0), COALESCE(t0.zi, 0)) AS abt_100011576_var_zi, COVAR_SAMP(COALESCE(t0.mu, 0), COALESCE(t0.mu, 0)) AS abt_100011576_var_mu, COVAR_SAMP(COALESCE(t0.zi, 0), COALESCE(t0.mu, 0)) AS abt_100011576_cov_zi_mu, COVAR_SAMP(COALESCE(t0.zi, 0), COALESCE(t1.uv, 0)) AS abt_100011576_cov_zi_uv, COVAR_SAMP(COALESCE(t0.mu, 0), COALESCE(t1.uv, 0)) AS abt_100011576_cov_mu_uv, COVAR_SAMP(COALESCE(t1.uv, 0), COALESCE(t1.uv, 0)) AS abt_100011576_var_uv, SUM(t0.zi) AS abt_100011576_sum_zi, SUM(t0.mu) AS abt_100011576_sum_mu, SUM(t1.uv) AS abt_100011576_sum_uv, SUM(t0.zi) / SUM(t0.mu) AS abt_100011576, COUNT(1) AS abt_100011576_bucket_num FROM(SELECT exp_id, grp_id, bucket_id, SUM(search_ymal_gmv) AS zi, SUM(search_eps_goods_num) AS mu FROM dm.dm_abt_exp_grp_bucket_search_top_source_trigger_1d WHERE exp_id = 100791211 AND grp_id IN (102059666, 102059661) AND dt BETWEEN ‘20260122’ AND ‘20260127’ GROUP BY exp_id, grp_id, bucket_id) AS t0 INNER JOIN (SELECT exp_id, grp_id, bucket_id, COUNT(DISTINCT user_sl_id) AS uv FROM dm.dm_abt_user_siteid_lang_detail_1d WHERE exp_id = 100791211 AND grp_id IN (102059666, 102059661) AND dt BETWEEN ‘20260122’ AND ‘20260127’ GROUP BY exp_id, grp_id, bucket_id) AS t1 ON t1.exp_id = t0.exp_id AND t1.grp_id = t0.grp_id AND t1.bucket_id = t0.bucket_id GROUP BY t0.exp_id, t0.grp_id;
上面的sql执行时间为6~7s,预计毫秒级
【背景】做过哪些操作?
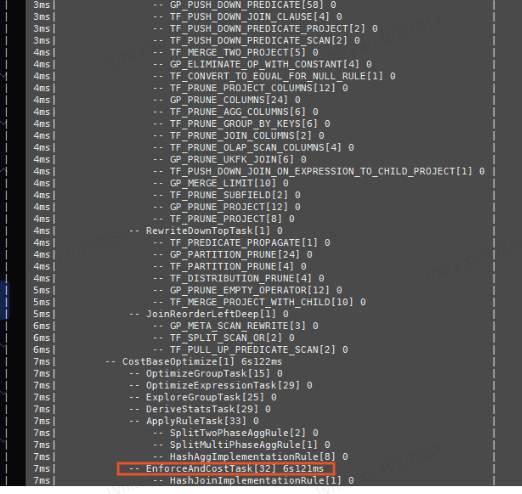
TRACE TIMES OPTIMIZER后发现,主要耗时在CBO期间
【业务影响】
【是否存算分离】是
【StarRocks版本】3.5.10
【集群规模】例如:3fe(1 follower+2observer)+30be(fe与be混部)
【机器信息】fe 64C512G,be 32C256G
【联系方式】为了在解决问题过程中能及时联系到您获取一些日志信息,请补充下您的联系方式,例如:社区群4-小李或者邮箱,谢谢
【附件】
fe.log/beINFO/相应截图
慢查询:
Profile信息
并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
SHOW ANALYZE STATUS;
-- 或
SHOW STATS HEALTH ON dm.dm_abt_exp_grp_bucket_search_top_source_trigger_1d;
SHOW STATS HEALTH ON dm.dm_abt_user_siteid_lang_detail_1d;
ANALYZE TABLE dm.dm_abt_exp_grp_bucket_search_top_source_trigger_1d WITH SYNC;
ANALYZE TABLE dm.dm_abt_user_siteid_lang_detail_1d WITH SYNC;
收集完成后,再次执行 SQL 观察 CBO 耗时是否有改善。
2. 简化查询结构(如果可能)
复杂的子查询和多重聚合是 CBO 耗时的主要原因。
尝试优化 SQL 结构:
您的查询本质上是将两个子查询的结果连接起来,然后进行最终聚合。如果两个子查询的 Group By 键完全相同,可以考虑使用 CTE (Common Table Expressions) 或视图来提高可读性,虽然对 CBO 性能的直接影响不一定大,但有时能帮助 CBO 更好地识别公共表达式。
WITH t0 AS (
SELECT exp_id, grp_id, bucket_id, SUM(search_ymal_gmv) AS zi, SUM(search_eps_goods_num) AS mu
FROM dm.dm_abt_exp_grp_bucket_search_top_source_trigger_1d
WHERE exp_id = 100791211 AND grp_id IN (102059666, 102059661) AND dt BETWEEN '20260122' AND '20260127'
GROUP BY exp_id, grp_id, bucket_id
),
t1 AS (
SELECT exp_id, grp_id, bucket_id, COUNT(DISTINCT user_sl_id) AS uv
FROM dm.dm_abt_user_siteid_lang_detail_1d
WHERE exp_id = 100791211 AND grp_id IN (102059666, 102059661) AND dt BETWEEN '20260122' AND '20260127'
GROUP BY exp_id, grp_id, bucket_id
)
SELECT
t0.exp_id AS exp_id,
t0.grp_id AS grp_id,
-- ... 聚合函数
COVAR_SAMP(COALESCE(t0.zi, 0), COALESCE(t0.zi, 0)) AS abt_100011576_var_zi,
-- ... 其他 COVAR_SAMP, SUM, COUNT
SUM(t0.zi) / SUM(t0.mu) AS abt_100011576,
COUNT(1) AS abt_100011576_bucket_num
FROM t0
INNER JOIN t1 ON t1.exp_id = t0.exp_id AND t1.grp_id = t0.grp_id AND t1.bucket_id = t0.bucket_id
GROUP BY t0.exp_id, t0.grp_id;