

作者:朱奥 /淘天集团高级数据工程师
导读:双 11 等大促场景会在短时间内集中爆发:运营与业务 BI 在开卖后的窗口期密集访问数据产品,瞬时请求量陡增,对查询引擎的稳定性、成本与治理体系提出极高要求。与此同时,业务对近实时数据产品的诉求持续增强,传统“多存储、多链路、依赖回刷”的模式在研发效率、回刷成本与响应速度上逐步暴露瓶颈。
本文围绕 Paimon 与 StarRocks 的组合实践,梳理淘天在大规模 OLAP 查询场景下的架构演进与双 11 保障体系:通过实时与离线统一入湖,消除数据同步链路与多份存储成本;基于稳定中间层叠加在线现算与维表实时关联,将高消耗回刷转化为秒级查询,核心场景回刷效率提升约 80%,年化节省成本接近 1000 万;同时结合 StarRocks + RoaringBitmap 低成本解决跨天交叉实时 UV 计算难题,满足大促近实时决策需求。
1 淘天集团营销活动 OLAP 查询的探索背景与核心策略
1.1 当前数据架构

首先,简要介绍当前的数据架构与数据流转方式。
从 DWD 层开始,我们的数据分为实时与离线两条主链路:
-
实时数据主要存储在 TT中,在业界可类比为 Kafka 一类的消息队列;
-
离线数据主要存储在 ODPS 中。
在数据加工与写入层面,我们会启动 Flink 流批一体任务:
-
实时侧持续消费 TT 中的数据;
-
离线侧消费 ODPS 中的数据;
-
在计算过程中,任务会关联多类 ODPS 维表,例如类目维表、商家分层等维度信息。
-
计算完成后,结果统一写入 ADS 层的Holo 表中,并在数据服务层对外透出。
在纯离线场景下,我们会通过 ODPS 任务读取 ODPS 数据,同时写入 ADS 层对应的 ODPS 表。这里既包含历史天级数据,也包含历史小时级数据。当存在查询加速需求时,我们还会将 ODPS 数据进一步导入到 Holo 中。
在数据服务层,我们主要通过 Holo 或 MC 对外提供数据服务。我们会根据查询时延要求选择不同的服务路径:当业务对响应速度要求更高、需要达到毫秒级时,通常通过 Holo 提供查询服务;当时延要求相对宽松,例如百毫秒级或秒级,则更多通过 MC 来承载查询请求。
1.2 业务诉求与核心痛点
随着业务发展,我们当前面临的诉求主要来自两个方向:一是业务侧希望获得更多实时数据产品;二是业务 BI 的实时分析需求持续增长。这对数据研发提出了新的挑战:进一步提升研发效率。
回到现有架构,其核心痛点主要体现在两方面:
-
流批存储不统一 :实时数据存储在 TT 中,离线数据存储在 ODPS 中;当存在查询加速需求时,部分数据还需要进一步落到 Holo 表中。
-
整体开发架构较为复杂,数据需要在多个存储介质之间流转,导致端到端链路拉长。
在查询特性上,Holo 在点查场景具备更突出的性能优势,且整体稳定性较强,在淘天历年大促期间的表现也相对稳定。
但在更常见的 Shuffle 场景下,整体查询性能相对一般。尤其当 OLAP 查询负载更重、需要进行更复杂的计算,或需要关联规模较大的维表时,Shuffle 相关的执行效率会成为瓶颈,导致查询耗时明显拉长。
数据更新与维护上也存在较高成本。以 ODPS 中的维表为例(如类目维表、商家分层维表等),当维表发生业务变更时,往往需要触发 ADS 层任务的回刷,从而带来额外的回刷开销。
业务对“近实时”的诉求在部分场景下出现了被动降级。例如在跨天实时 UV 等场景中,由于 state 规模较大、成本较高等原因,方案不得不从实时级别降级到小时级别。从业务视角看,近实时能力仍然是明确存在的需求。
1.3 核心策略
1)架构简化提效
-
架构上实现 存储介质的统一 :将实时与离线数据统一沉淀到 Paimon 的湖存储中。在此基础上, StarRocks 可以直接面向湖存储进行高性能分析查询 ,从而能够消除数据同步链路以及多份存储带来的成本。
-
降低使用门槛, 让数据更容易被上层分析与 BI 使用。以实时链路为例,原本实时数据存储在 TT 中,而 TT 的数据形态具有明显特征:每行数据是一个字符串、缺少 schema。在这种形态下,数据虽然可以被消费,但如果要面向 BI 分析使用,往往还需要额外进行反序列化与解析,这会带来不可忽视的工程与使用成本。
在统一存储之后,Paimon 将实时与离线数据沉淀在同一张表中,并提供明确的 schema。这意味着,上层使用方可以直接面向结构化数据开展分析:即使分析师的数据开发能力不强,也可以基于 Paimon 的近实时中间层,通过 StarRocks 自助完成对近实时数据的分析。
在这种模式下,过去一些相对简单的取数与分析需求,可以由 BI 或分析师通过自助方式直接完成,不再必须提交给数据研发排期处理,从而在一定程度上减少数据开发侧的需求量与交付压力。
2) 业务难点攻坚
通过稳定的中间层 Paimon,以及“OLAP 实时关联易变维度”的模式,将原本高消耗的 ADS 回刷任务转化为秒级查询来完成。在后续内容中,我会进一步展开这一改造如何将高消耗回刷去掉,并带来显著的成本收益——每年可节省近千万元级别的回刷成本。
同时,我们通过 StarRocks + RoaringBitmap 的方案,高性能解决了跨天交叉实时 UV 的计算难题,以更低成本的方式满足大促期间对近实时能力的诉求。
1.4 新数据架构
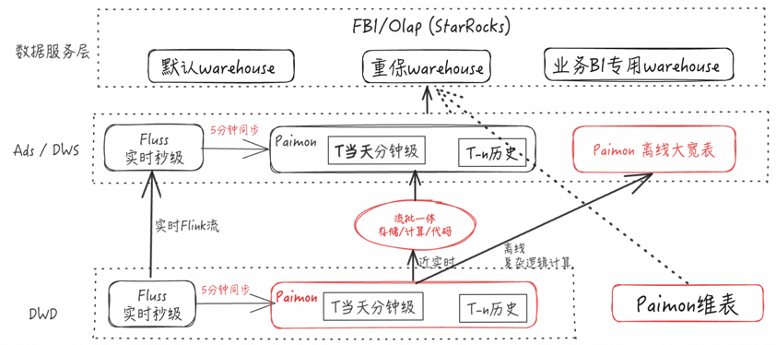
在秒级数据链路上,我们通过实时 Flink 任务消费 DWD 层的 Fluss(秒级实时数据),并将结果写入 ADS 层的 Fluss。
Fluss 提供“湖流一体”的同步开关。开启后,Fluss 中的数据会按配置周期自动同步到 Paimon 表中,默认周期可以是每 3 分钟,且该时间间隔支持用户自定义配置。同步完成后,Paimon 表中会形成当天分钟级数据(t 当天)以及 t−n 的历史数据。
在此基础上,我们会启动 Flink 流批一体任务,同时消费 DWD 层 Paimon 的 t 当天数据与 t−n 历史数据,并将加工结果写入 Paimon 表的 ADS 层与 DWD 层,分别沉淀 t 当天与历史数据。
此外,基于 Paimon 的 partial-update能力,我们也可以构建离线大宽表,用于承载同一业务对象的多状态聚合。以订单为例,订单存在支付、确收、退款等多种状态,可以构建一张以 order_id 为主键的 Paimon 大宽表,将这些状态写入同一行记录。这样在使用侧只需读取对应 order_id 的一条记录,即可获取该订单的多种状态信息,使用成本与分析便利性都会更高。
在 ADS 层,我们沉淀的计算结果主要面向“叶子粒度”的维度:例如类目侧以叶子类目为主;若涉及商家分层维表,则对应叶子商家分层。在数据服务层,我们通过 StarRocks 对外提供数据服务。具体而言,在 StarRocks 层既可以直接读取 ADS 层数据进行点查,也可以直接读取 DWD 层的中间层数据进行在线计算。后一种方式的查询负载通常更重、数据量更大,但在当前实践中,StarRocks 仍然能够将查询时延控制在秒级范围内,在查询量较大的情况下保持较快响应。在查询过程中,我们也可以进一步关联 Paimon 维表,最终将查询结果在数据产品端进行展示与交付。
在我们 的业务场景中 ,一般来说,DWD 层的中间层事实数据相对稳定;真正“易变”的往往是维度侧的数据,例如 Paimon 维表(类目维表、商家分层维表等)。当业务规则或口径发生调整时,通常只需要更新维表即可。相较于回刷大规模中间层数据,维表更新的成本更低、执行也更快。
更关键的是,我们在查询侧采用现算方式:维表更新后,查询会在读取中间层数据的基础上实时关联最新维表,因此中间层数据无需随业务变更反复回刷。由于中间层计算量较重,如果依赖回刷来响应业务调整,整体周期往往较长——快则一到两天,慢则可能需要一周。通过“更新维表 + 查询现算”的方式,业务变更后可以更快在数据产品侧看到最新结果。
在数据服务层,我们进一步利用 StarRocks 的 Warehouse 机制,对读集群进行隔离与分级保障,避免不同业务互相影响。我们按照业务重要性划分为三类:
-
默认 Warehouse:保障级别相对一般;
-
重保 Warehouse:承载最核心业务,保障级别最高;
-
业务 BI 专用 Warehouse:面向业务 BI 或其他业务的专用资源池,保障级别相对一般。
2 Paimon+StarRocks 在双11大规模 OLAP 查询场景下的实践与优化
2.1 业务背景
在日常情况下,运营和业务 BI 往往在不同时间访问数据产品,因此 StarRocks的瞬时请求量(RPS)整体较低,压力相对平稳。
但在大促期间情况会明显不同。以开卖时段为例,运营和业务 BI 通常会在接下来的一小时内集中访问数据产品,导致 StarRocks 的瞬时请求 RPS 急剧升高,对 StarRocks 集群带来显著挑战。
因此,本部分的实践与优化工作主要围绕“大促场景稳定运行”这一目标展开。
2.2 集群侧保障

1)在应用层面推广数据集缓存策略 :目前配置 180 秒的查询缓存窗口。也就是说,同一条查询在 180 秒内被多次触发时,实际下发到 StarRocks 执行的仅为首次请求;后续请求直接复用首次查询结果。通过该策略,可以有效降低大促高峰期 StarRocks 集群的瞬时压力。
2)集群层面的保护机制: 集群侧设置了 30 秒的全局超时:如果一条 SQL 在 30 秒内仍未执行完成,会被自动终止。该机制属于 StarRocks 的集群保护能力,当查询执行时间超过 30 秒,即可判定该 SQL 需要进一步优化,不适合直接上线,需要回退并完成优化后再进入生产环境。对于少量确有必要、且在 30 秒内无法完成的特殊 SQL,也支持为单条 SQL 配置更长的超时时间。但此类 SQL 数量通常极少,上线评估也会更加严格,以确保不会对整体集群稳定性产生影响。整体目标是避免单条慢 SQL 拖垮集群。
3)架构层隔离:按业务重要性划分只读实例。 基于业务重要性对只读查询资源进行分层,将不同业务的读请求隔离到不同的只读实例上,避免相互干扰。
4)集群初始化配置
在新的 StarRocks 集群初始化时,比较推荐先设置一套基础参数,如下:
- set global cbo_cte_reuse_rate=0;
当 CTE 被多处引用时,可能触发同一数据源的重复读取。例如,一个表在 select 中读取三次,那么 StarRocks会对同一张 Paimont 表执行三次读取,读 I/O 开销相当于被放大为 3 倍。将该参数设置为 0 后,可使同一张表在同一条查询中只读取一次。
•set global query_timeout=30;
设置 30 秒的集群全局查询超时 , 避免单条慢 SQL 拖垮集群。
•set global new_planner_optimize_timeout=10000;
适当调大执行图优化器的超时时间。如果该参数设置过小,SQL 在调度过程中更容易直接失败;适当增大后,可降低 SQL 失败的频率。
•set global pipeline_dop=8;
调整 pipeline 的 DOP,用于控制每台机器上拉起的 driver 数量。压测结果显示,在大促场景中 SQL 请求高度集中,若 DOP 设置过大(例如 64),单条 SQL 在每台机器上会拉起大量 driver,带来调度开销飙升,甚至可能打满 driver 阻塞队列,导致 CPU 利用率反而上不去,集群进入不可用状态。
在我们StarRocks集群的双 11 压测中,DOP 调整到 8 时整体查询表现最优,因此给出 DOP=8 作为建议值。需要强调的是,该值是经验建议,最终仍应以各自集群的压测结果为准进行配置。
•set global scan_paimon_partition_num_limit=100; --限制scan paimon外表的最大分区,杜绝扫描全表的情况
限制 scan paimon外表的最大分区,用于杜绝因条件缺失或下推失败导致的全表/超大范围扫描。
2.3 核心指标监控
通过观察 StarRocks 核心指标的水位变化,可以持续评估实例健康状况。常用的核心指标如图。

2.4 报警规则

建立 StarRocks 实例的异常报警机制非常关键,它能够帮助及时发现实例异常并快速介入处理。报警项的设置通常围绕“资源水位、节点可用性、调度拥塞、查询失败与时延”几类核心信号展开,其中有一部分阈值来自大促压测与实战探索,具有较强参考价值:
-
BE/CN 的 CPU 与内存使用率设置阈值,例如当使用率持续高于 70% 时触发告警;
-
FE 的 CPU 与内存使用率同样设置 70% 的告警阈值;
-
在可用性方面,可以监控 BE/CN 或 FE 的可用率是否低于 100%,一旦出现低于 100% 的情况,通常意味着有节点不可用或发生故障。
-
当 BE 阻塞队列数超过 2000 时,StarRocks 集群的查询时延可能出现陡增;
-
在查询侧,可以增加查询失败次数与查询时延分位数的告警,例如“查询失败次数大于 n”“查询延迟 TP99 大于 n”。其中 n 的取值需要结合业务特性与可接受的服务水平目标进行配置。
2.5 元数据监控
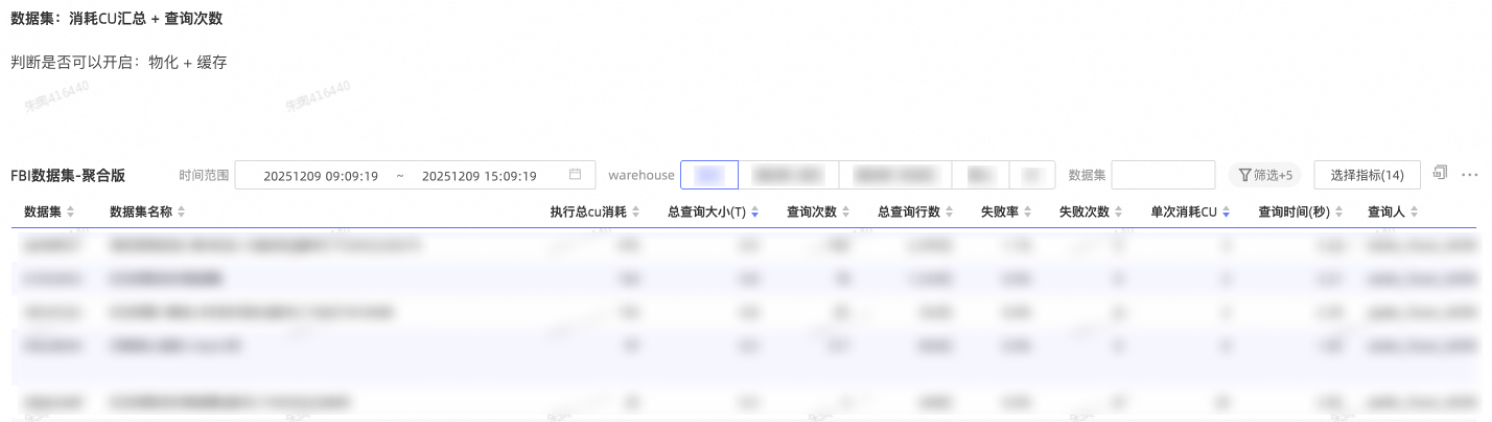
为更有效地治理 StarRocks的各类查询请求,可以实时获取审计日志,并基于审计日志构建元数据监控大盘,为后续的慢查询 SQL 治理提供数据支撑与定位依据。
select * from _starrocks_audit_db_.starrocks_audit_tbl;
审计日志相关数据落在 StarRocks 的内表中,对应信息可实时查询。也就是说,某条 SQL 执行完成后,可以立即在该内表中查到这条 SQL 的执行耗时等关键字段。基于这一基础能力,如果需要进一步做更细的源数据与查询行为监控,也可以围绕审计日志中记录的 SQL 信息进行扩展。
在监控大盘的组织方式上,支持按 Warehouse 维度拆分(例如划分为多个 Warehouse),同时也可以按数据集进行过滤。在筛选完成后,重点关注的数据字段通常包括:数据集名称、总 CPU 消耗、总查询大小、查询次数、查询行数、失败率与失败次数、单次查询的 CU 消耗、查询时间以及查询发起人等。这些指标支持排序与聚合,便于在优化过程中选取特定时间窗口,对总 CPU 消耗、总查询大小、总查询行数等维度进行 Top SQL 排查与治理。通过优先治理这些“高消耗/高影响”的 SQL,往往能够显著改善集群整体健康状况,因为在许多情况下,集群不稳定的根因来自少量高风险的“坏 SQL”。
2.6 大促保障

大促保障的目标,是把不确定性尽量前置消化,确保开卖高峰期间查询链路稳定可控。
-
在资源侧, 会结合历史数据与业务预测,在大促开始前对 StarRocks 集群进行主动扩容,并在大促结束后主动缩容。
-
在需求侧, 提前与业务负责人对齐本次大促的核心变更点,重点关注改造或新增页面,并将核心页面的 QPS 进行量化,为全链路压测与容量评估做准备。
-
针对重保页面 ,我们还会建立一套智能应急机制,分为实例级与查询级两层。实例级故障切换方面,当 StarRocks 主实例不可用时,可通过自动化预案工具(FBI)将重保页面的查询请求批量切换到备库 Warehouse,完成实例级容灾;查询级自动容错方面,当重保页面出现单次查询失败或超时,系统会将该查询自动路由到备库 Warehouse 重试,尽量做到用户无感,为关键 SQL 增加一次“二次机会”,提升整体稳定性。
2.7 大促压测

大促压测通常分为两层: 核心页面单压与全链路压测。
在核心页面单压阶段,会先梳理大促期间的核心页面及新增页面,并对这些页面进行单独压测。这样做的目的,是尽可能在活动前置暴露并解决单点问题导致的性能瓶颈,为后续上线留出精细化优化空间。
在全链路压测阶段,会模拟“所有页面同时达到流量峰值”的极限场景,用以验证 StarRocks 集群在峰值冲击下的整体资源水位与关键性能指标是否符合预期。重点关注的资源水位通常包括 CPU、内存与 I/O,同时结合查询时延等指标,评估集群在极端并发与高负载下的稳定性与承载边界。
2.8 压测发现的问题和优化方案
1)分区裁剪失效或缺少分区过滤,导致扫全表
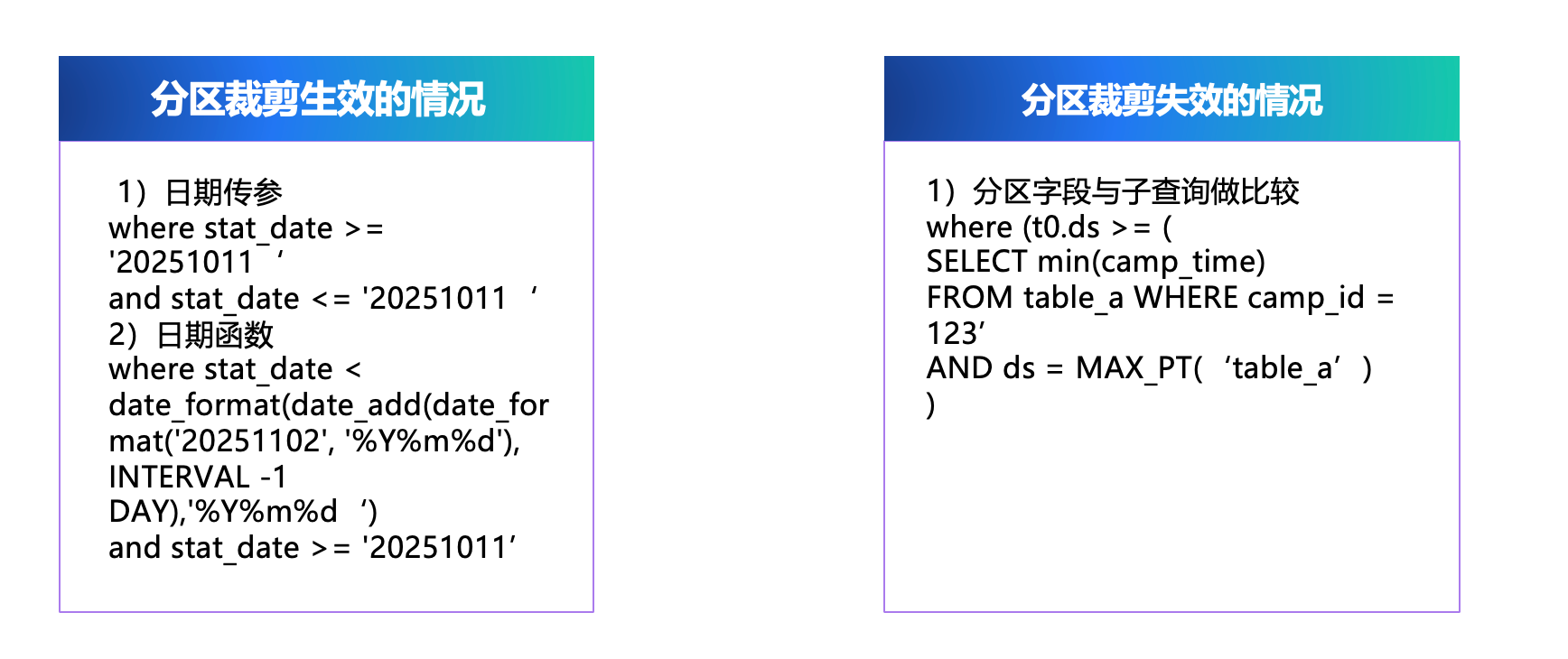
压测中发现,部分 SQL 因分区裁剪失效或未配置分区过滤条件,出现扫描范围过大甚至扫全表的风险。针对该类问题,治理原则是必须启用分区过滤并确保分区裁剪生效,不允许存在扫全表 SQL 在线运行。
分区裁剪生效的常见写法包括:对分区字段进行日期传参,直接基于分区字段触发裁剪;或使用日期函数触发裁剪,例如 date_format、date_add 等函数也可以触发分区裁剪。
分区裁剪失效的典型场景是分区字段与子查询结果进行比较,例如将分区字段与子查询返回的最小活动时间进行对比时,分区裁剪会失效。原因在于分区裁剪发生在 FE 阶段,而子查询需要到 BE 执行,FE 在规划阶段无法获得子查询结果,从而无法生成有效的分区裁剪信息。
2)读取 Paimon 生表时小文件过多,导致读取数据块数过大

压测还发现,读取 Paimon 表时存在小文件过多的问题。
定位方法 :在 StarRocks 执行 SQL 时可开启 profile(通过 hint:/*+ SET_VAR(enable_profile = true) */)生成 profile 文件;在 profile 中搜索 “metadata”,其中 nativeReaderReadNum 表示读取的数据块数,nativeReaderReadBytes 表示读取的字节数。实践中,当单个分区的 nativeReaderReadNum 大于 200 时,通常建议考虑对表进行排序治理。
优化方案 :在构建流批排序Paimon表时,建议采用分支表模式:离线分支将 bucket 设为 -1,实时分支按需设置 bucket。离线分支表通过 clustering columns 指定排序字段,可支持指定多个字段(如 f1、f2),一般选择 OLAP 查询中最常用的过滤字段,以提升过滤命中与读取效率。该能力仅支持 Flink 批写入,不支持 ODPS 写入;写入表时需要使用 hint: */*+ OPTIONS(‘sink.parallelism’ = ‘64’) / 。对于 ODPS 写入的 Paimon 表,则需要在任务下挂一个单独的 compact 排序任务。
为何有效 :在双 11 场景下,活动周期往往持续数十天。当天数据属于实时增量,而从活动开始到昨天的历史数据占比更大;因此对离线数据进行表排序收益显著。压测实测显示,排序后读取的数据块数约为排序前的 1/1000。 离线分支完成排序后,活动开始到昨天(占比最大的历史数据)基本都处于“已排序、数据块读取量很小”的状态;实时分支由于无法排序,读取的数据块会相对多一些,但实时数据通常只存在于当天,整体占比小,因此对整条 SQL 的查询时延影响相对有限。
3)检查是否命中 MapJoin:小维表建议显式 broadcast
当 SQL 需要 join 小表(例如小于 10MB 的维表)时,建议在维表前显式加 broadcast,以触发类似离线 MapJoin 的执行策略。实测显示,引入 broadcast 后查询时延可显著下降,典型场景下可从十几秒优化到约 3 秒,整体查询时延约为原先的 1/3。
SELECT xxx
FROM table_a t0
LEFT JOIN [broadcast] dim_table_b t1
ON t0.cate_id = t1.slr_main_cate_id
AND t1.ds = 'xxx'
4)检查跨地域访问:计算与存储尽量同地域部署
还需要确认 StarRocks 实例与所读取的 Paimon 表是否处于同一地域。若不在同一地域,查询时延会明显增加。建议将 StarRocks 的部署地域与 Paimon 表存储地域保持一致。
5)主键表建议开启 deletion vectors:减少无效数据读取
对于 Paimon 主键表,建议开启 ‘deletion-vectors.enabled’ = 'true’参数。该能力会在写入阶段记录哪些主键数据已被删除;读取时可跳过已删除数据,减少无效扫描,从而提升查询性能。非主键表不需要开启该参数。
3 阶段成果与未来规划
3.1 阶段成果
整体来看,该方案带来了四方面阶段性成果。
-
数据链路得到简化 :通过统一存储与统一查询面,消除了数据同步链路,并降低了多份存储带来的成本与复杂度。
-
数据使用门槛显著降低 :基于 Paimon 的实时/离线中间层,不仅数据开发人员可以使用,业务分析师也可以通过 StarRocks 自助消费近实时数据,从而减少部分简单需求对数据研发排期的依赖。
-
回刷开销得到明显削减 : 核心场景的回刷效率提升约 80%,年化节省成本接近 1000 万。 其关键在于查询可以直接读取 Paimon 公共层并关联 Paimon 维表,业务变更时只需刷新维表,无需回刷与该维表相关的整条数据链路。
-
在高性能实时分析方面,低成本解决了跨天交叉维度实时 UV 的计算难题,满足大促期间近实时决策需求。 具体做法是将可累加指标(如订单数、订单支付金额等)与不可累加指标(如 user_id)分开处理:可累加指标在查询侧直接聚合;不可累加指标则将 user_id 做 RB 化后存入中间层,StarRocks 读取 Paimon 表时通过 RB 相关函数计算 UV。
3.2 未来规划
面向下一阶段,规划主要集中在四个方向。
第一, 希望 StarRocks 具备更强的自动物化能力 :针对用户高频查询的 SQL 自动生成物化结果,并在后续查询中自动完成改写,直接命中物化表。由于物化表往往已经完成聚合,其数据量相较直接查询中间层可以小很多个量级,从而显著降低扫描与计算开销,进一步提升查询速度与稳定性。
第二,计划进一步 丰富 StarRocks 的元数据能力 。
第三, 优化 StarRocks 的调度策略 ,重点是调度层面的 CPU 负载均衡能力。
第四,希望 StarRocks 具备直接读取 Fluss 的能力 ,从而支持秒级查询场景。目前 Paimon 仍以分钟级链路为主,如果能够在读取侧进一步下探到 Fluss,将更好覆盖对秒级实时性有明确诉求的业务场景。