【详述】统计类型的SQL非常慢,经常慢。
【背景】点查就很慢
【业务影响】
【是否存算分离】否
【StarRocks版本】3.5.2
【集群规模】3fe+3be(fe与be独立部署)
【机器信息】fe:8C/16G/万兆;be:40C/128G/万兆
SQL:select * from xxx表 where corpid in (1个值) ;

如果corpid是2-4个值,那么查询要十几秒。
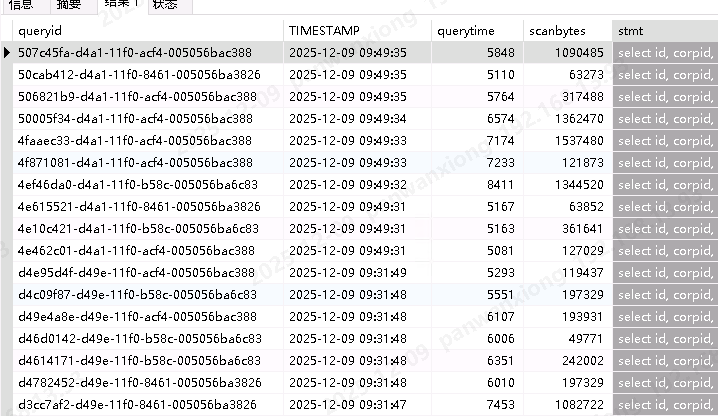
主键也是分区键,也是排序键,还创建了bloom索引

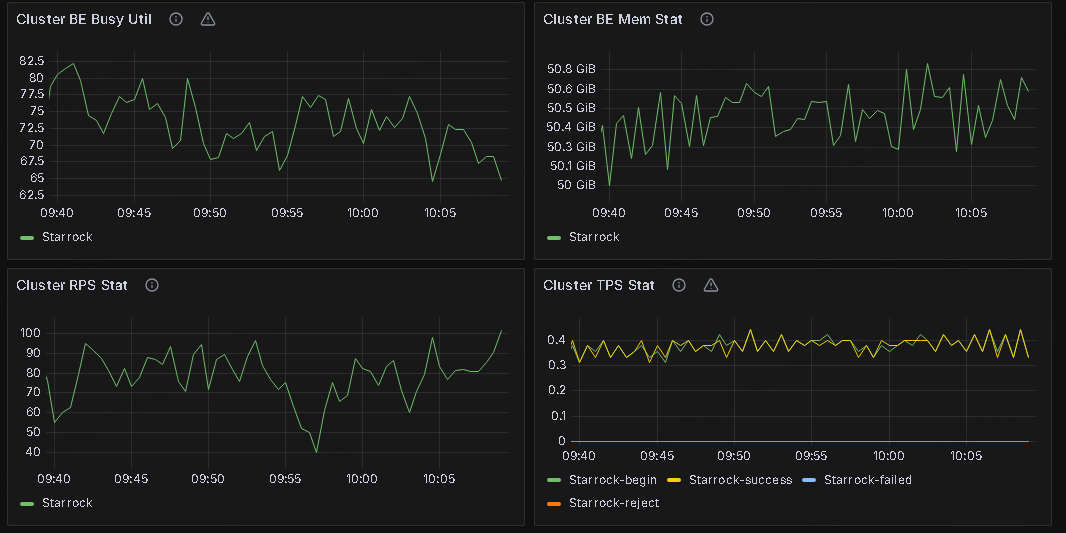
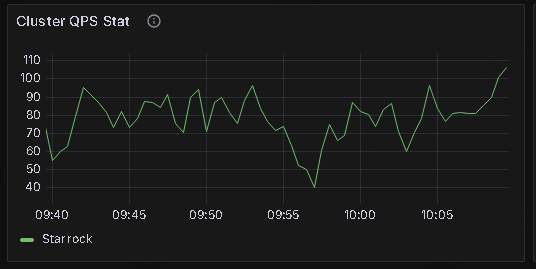
对应时间的监控

【详述】统计类型的SQL非常慢,经常慢。
【背景】点查就很慢
【业务影响】
【是否存算分离】否
【StarRocks版本】3.5.2
【集群规模】3fe+3be(fe与be独立部署)
【机器信息】fe:8C/16G/万兆;be:40C/128G/万兆
SQL:select * from xxx表 where corpid in (1个值) ;
主键也是分区键,也是排序键,还创建了bloom索引
对应时间的监控
抓个query profile
SET global big_query_profile_threshold = ‘5s’; 这个好像没有用?在浏览器看到几十毫秒的也打印出来,因为慢SQL不是实时都存在,好难抓。
- 描述:用于设定大查询的阈值。当会话变量
enable_profile设置为false且查询时间超过big_query_profile_threshold设定的阈值时,则会生成 Profile。NOTE:在 v3.1.5 至 v3.1.7 以及 v3.2.0 至 v3.2.2 中,引入了big_query_profile_second_threshold参数,用于设定大查询的阈值。而在 v3.1.8、v3.2.3 及后续版本中,此参数被big_query_profile_threshold替代,以便提供更加灵活的配置选项。
set global pipeline_dop=1; 试一下
好像没有什么效果,观察了两天还是有in 一个值的慢SQL。
bloom 不是这么设的,你取消这个设定在试试
如果是 primary key,要看数据的分布,如果分布的很平均,就只会从某个Tablet 命中
corpid 是什么类型的?