

作者:云汉翾 哈啰资深大数据开发工程师
导读 :
作为国内领先的出行与生活服务平台,哈啰在多业务协同与实时调度场景下,对数据分析性能和系统稳定性提出了更高要求。
为应对业务多元化带来的数据增长与计算压力,哈啰技术团队完成了大规模 ClickHouse → StarRocks 迁移,并自研数据对比工具实现全流程自动校验(该工具后续将开源)。
迁移后,查询性能提升 3–5 倍,系统成本下降超 80%,查询响应从分钟级降至秒级,营销 ROI 提升约 60%。
目前,哈啰已在多云环境部署 15 个 StarRocks 集群,支撑普惠金融、两轮出行及算法平台等核心业务。
接下来,本文将带你了解这次迁移背后的技术思路与落地成效。
哈啰(Hello)起步于共享单车业务,如今已成长为国内领先的本地出行与生活服务平台。在出行领域,哈啰从单车起家,迅速拓展至助力车,并于 2019 年进入四轮出行市场,陆续上线顺风车和打车服务,形成覆盖多场景的综合出行网络。
在主业稳固的基础上,哈啰进一步向普惠生活服务领域延伸,推出自主品牌 哈啰电动车,与蚂蚁集团、宁德时代合资成立小哈换电提供两轮电动车换电服务,并打造聚合型租车平台哈啰租车。此外,哈啰还孵化了面向城市流浪猫管理的智能化品牌 “街猫”。
在数字化全面驱动业务增长的当下,哈啰作为覆盖普惠、两轮出行、算法平台等多业务场景的出行服务平台,对高效数据处理与实时分析能力提出了极高要求。
营销策略平台和两轮出行团队此前使用的 OLAP 引擎均为 ClickHouse。

其中,营销策略平台是哈啰精准营销的核心支撑,随着业务发展,平台数据规模突破 1000 亿条;两轮出行则是哈啰的核心业务,其数据平台承担着订单分析、用户行为追踪、运营监控等关键任务。
背景
原架构瓶颈
随着数据规模持续扩大,原 ClickHouse 集群逐渐暴露性能瓶颈,成为业务增长的阻碍:
- 集群扩展性差 :每次扩容需停服并重新刷写全量数据,导致业务中断,无法满足数据规模快速增长的需求;
- 资源占用率高 :日常运行中 CPU 与内存使用率长期超过 80%,资源余量不足,高峰时段易出现查询阻塞;
- 多表关联支持弱 :营销分析场景中频繁涉及多表 Join 操作(如用户画像表与活动参与表关联),ClickHouse 查询效率低,部分查询耗时超分钟级;
- 湖仓查询能力有限 :无法全量查询 Hive 数据湖中的历史数据,仅支持最近 60 天数据查询,制约长期营销效果分析。
引入 StarRocks
为解决上述问题,哈啰技术团队在深入评估多种方案后,决定引入 StarRocks 作为核心 OLAP 引擎。
其基于分布式架构设计,支持在线弹性扩缩容——新增节点后可自动均衡数据分片与计算负载,扩容过程中业务仍保持持续可用。
同时,StarRocks 具备精细化的资源隔离与调度能力,并提供多种 Join 算法(包括分布式 Hash Join、Broadcast Join、Colocate Join 等),可根据表规模与数据分布自动选择最优执行策略。
此外,StarRocks 拥有完善的湖仓一体查询能力,既能高效分析本地存储数据,也可直接访问数据湖中的 Hive、Iceberg、Delta Lake 等外部表,实现统一分析与治理。
凭借高吞吐、高可用与灵活扩展的特性,StarRocks 成为哈啰新一代实时分析平台的核心底座。
目前,哈啰已基于多云战略部署 15 个 StarRocks 集群 ,覆盖 IDC、阿里云、腾讯云及火山云等多环境, 日均处理请求量达 69.27 万次 ,为普惠、两轮出行核心业务及算法平台等多个关键系统提供稳定、高效的数据支撑。
在统一架构落地之后,团队进一步针对不同业务场景进行了分层设计与性能优化,确保在兼顾实时分析性能与数据湖开放访问能力的同时,实现资源利用最大化。
具体方案包括:
- 数仓分层存储: 将数据实时写入 StarRocks 中,所有热数据的查询均在 StarRocks 数据仓库中进行,上层数据应用在执行查询时,对于高 QPS 和低延迟要求的 SQL 直接走 StarRocks 内表。
- 数据湖查询加速: 将 ODS 层数据写入数据湖中,DWD、DWS、ADS 层则存储在 StarRocks 中。

从 ClickHouse 到 StarRocks 构建实时分析平台
数据迁移方案:
为实现从 ClickHouse 到 StarRocks 的无缝迁移,技术团队设计 “历史数据批量迁移 + 增量数据实时同步” 的双层方案:
- 历史数据迁移 :首先将 ClickHouse 中的历史数据导出到 CSV 文件中,然后基于 StarRocks Stream Load 接口编写 Shell 脚本工具,替代传统 ETL 工具(如 Flink、DataX),直接实现 ClickHouse 历史数据向 StarRocks 的高效导入。该方案无需部署维护额外中间件,降低系统复杂度;同时,Stream Load 的高吞吐特性结合脚本化的并发控制,可充分利用资源,确保 20TB + 历史数据快速迁移;
- 增量数据同步 :通过 Flink 任务同步至 StarRocks,保障迁移过程中数据不丢失、延迟低,实现业务 “无感迁移”。
相比传统 ETL 迁移方案,本次迁移方案具备三大核心优势:
- 降低系统复杂度 :直接通过 Shell 脚本与 StarRocks Stream Load 接口交互,省去中间件部署与维护成本,减少故障点;
- 提升资源利用率 :Stream Load 专为高吞吐设计,脚本化调用可灵活控制并发数与任务调度节奏,避免资源浪费;
- 降低维护成本 :Shell 脚本逻辑清晰,学习成本低,无需专业 ETL 工程师即可完成维护,解决传统工具配置繁琐、上手难的问题。
数据一致性保证
为确保迁移过程中数据结果的准确性与一致性,哈啰技术团队自研了一套轻量级数据对比工具,对迁移前后的查询结果进行精确校验。
在迁移过程中,面临两大技术挑战:
- 数据规模大:在亿级甚至百亿级数据量下,全量校验耗时过长、资源消耗大;
- 业务逻辑复杂:多表关联、函数计算(如聚合、日期转换)、字段类型映射(如 TINYINT→BIGINT)可能导致结果偏差,需精准校验查询结果。
- 核心方案:自研对数工具设计
为实现高效、准确的数据一致性校验,团队自研了一款轻量化、高兼容性的对比工具。该工具支持源端(ClickHouse)与目标端(StarRocks)之间的全量或抽样校验,可在不影响生产集群性能的前提下快速验证迁移结果。其核心设计包括:
- 多数据源适配与低侵入连接
- 跨源兼容:封装 ClickHouse JDBC(
ru.yandex.clickhouse)与 StarRocks JDBC(com.starrocks.jdbc)驱动,统一数据源接口,支持动态切换源端 / 目标端配置。 - 连接池优化:集成 HikariCP 连接池,限制并发连接数,设置超时时间(如 30 秒),避免高频校验对生产集群造成性能冲击。
- 跨源兼容:封装 ClickHouse JDBC(
- 字段类型映射规则引擎
针对不同数据库类型差异,预设字段映射校验规则,避免类型转换导致的比对误差:- 整数类型:允许源端 TINYINT/INT 与目标端 BIGINT 比对
- 浮点类型:支持阈值配置,如
abs(source_val - target_val) < 0.001即判定为一致(解决浮点精度误差) - 分母为 0:ClickHouse 返回 infinity,StarRocks 返回 null,这种特殊 case 认为对数一致
持续优化
为进一步提升平台的稳定性、查询性能与成本效率,哈啰技术团队围绕 StarRocks 的架构与执行引擎进行了持续优化,重点包括以下四个方向:
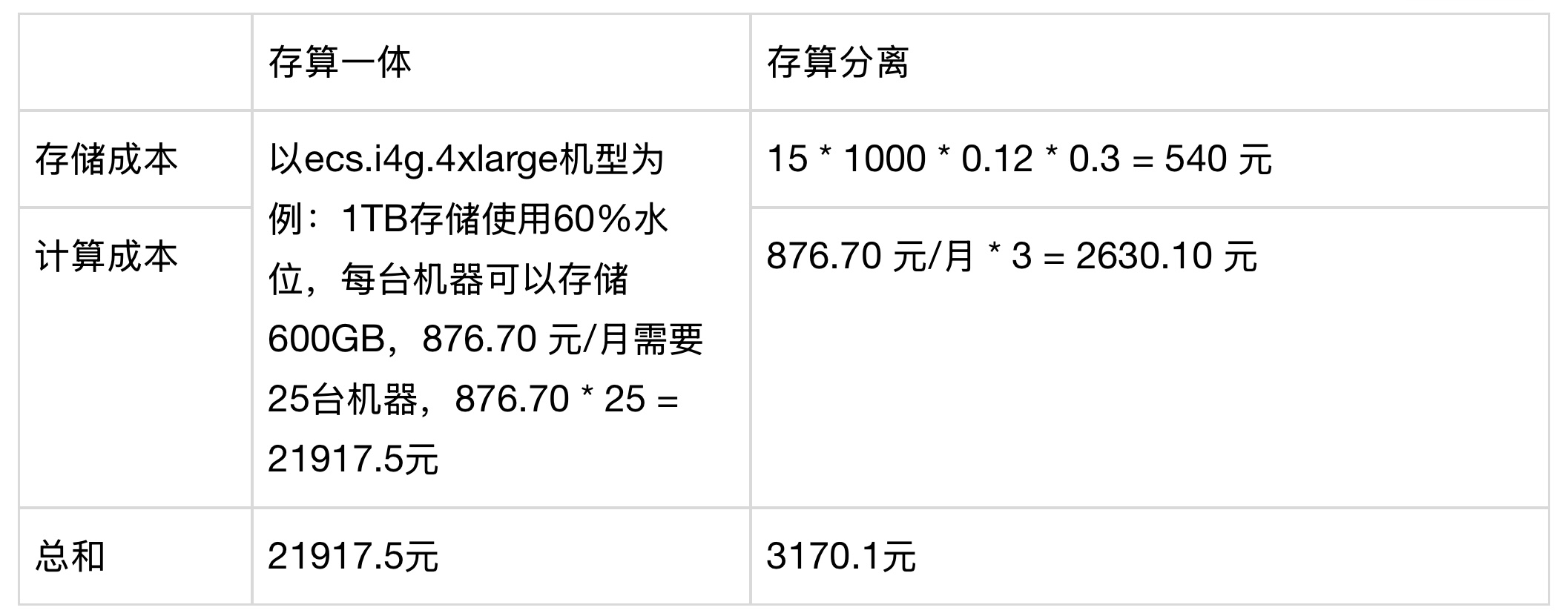
- 存算分离架构:实现成本降低 80%
在两轮业务方的虎克平台中,单表日写入量约 1TB。为应对高数据量写入与存储成本问题,团队采用存算分离构,以阿里云 OSS 作为底层存储介质。 测算结果显示,与存算一体架构相比,整体成本下降超过 80%:
阿里云 OSS 成本参考:
https://www.aliyun.com/price/product?spm=a2c4g.11186623.0.0.a8156038eZ5X3k#/oss/detail/ossbag
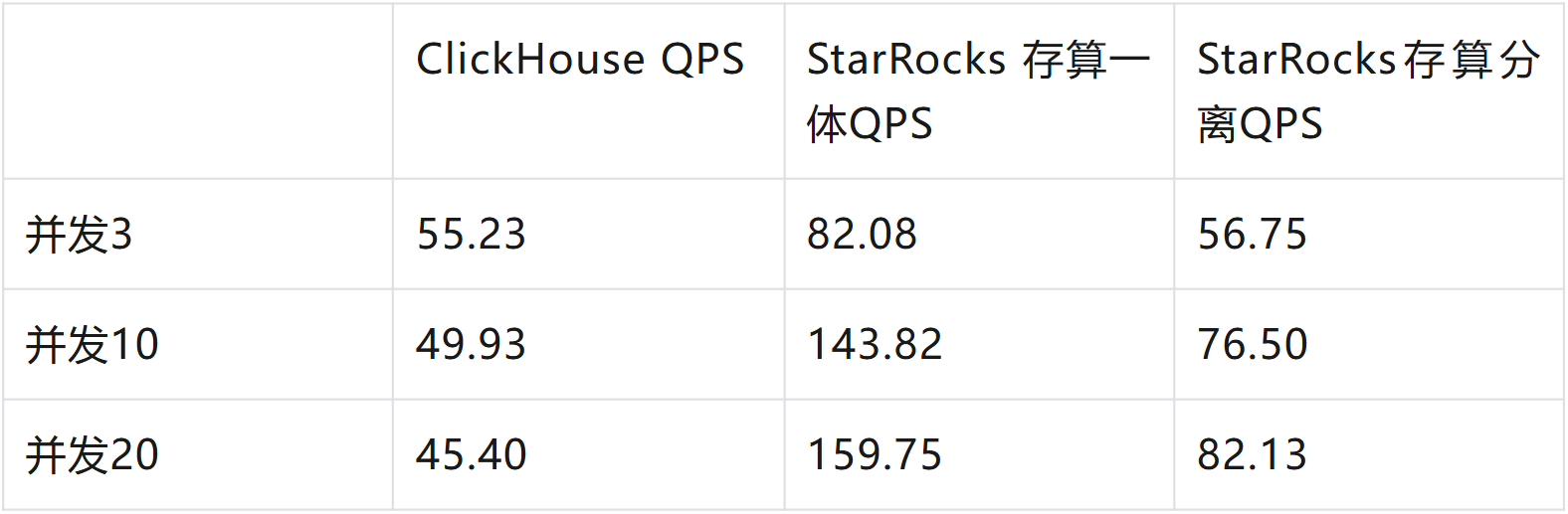
且在相同并发负载下,StarRocks 存算分离场景性能仍优于 ClickHouse。
- Bitmap 索引:加速高基数查询
针对用户 ID、设备 ID 等高基数列,采用 Bitmap 存储方式,利用高效位运算(AND/OR)替代传统 Count Distinct 计算。实践表明,该优化在保证查询性能提升 3-5 倍的同时,对数仓团队的改造成本最低。
- 大查询熔断机制:保障集群稳定
基于 StarRocks Resource Group 功能为营销策略平台业务配置独立资源组,设置查询超时阈值(600 秒)、内存上限(80%)及并发限制。当单次查询触发阈值时自动熔断,避免个别任务占用过多资源,保障整体集群稳定性。
4. SQL 语法兼容
在迁移过程中,SQL 兼容性至关重要。只有保证语法一致,才能让现有的分析工具和业务逻辑无缝迁移至新架构,从而降低学习成本、提升使用体验。
团队在社区提供的 SQLTransformer工具基础上进行了扩展,实现 ClickHouse 与 StarRocks 语法的深度兼容,使数据分析人员能够直接复用原有脚本与查询习惯,无需额外改造。
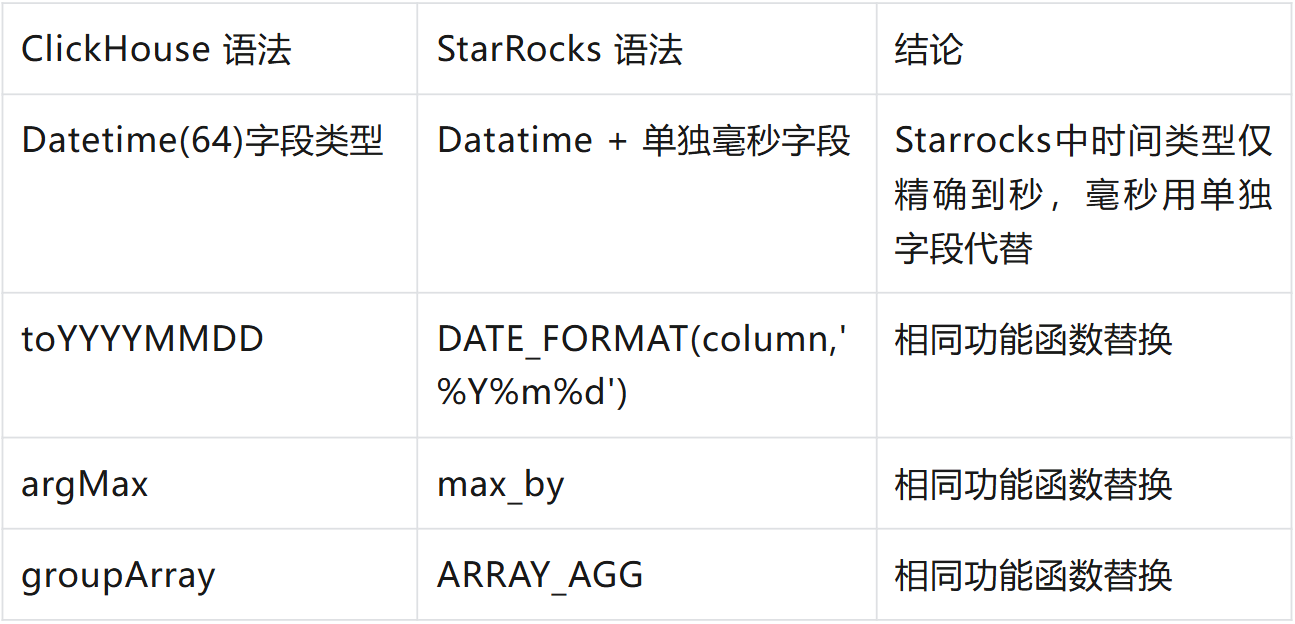
迁移成效
通过迁移至 StarRocks,哈啰实现了性能、业务、架构与运维多维度的全面提升:
- 性能显著提升,分析响应提速 3–5 倍 :核心查询从原 ClickHouse 的分钟级普遍降至秒级,实时用户画像与人群圈选分析大幅加速,帮助营销团队快速洞察业务变化、即时调整策略。
- 营销 ROI 大幅提升 :得益于数据处理效率的提升,营销活动在人群筛选、触达精准度及执行效率等方面全面优化,带动转化率与复购率提升约 60% ,显著增强营销资源使用效率。
- 统一 OLAP 平台,实现多源数据融合分析 :迁移整合后,StarRocks 支撑高并发、低延迟查询,打通业务数据库、日志系统等多类数据源,实现跨业务、跨场景的联合分析,消除数据孤岛。
- 运维效率提升,系统更稳定可靠 :在保障查询性能的同时,整体硬件资源消耗进一步降低,系统稳定性与可维护性显著增强,为后续数据规模增长和业务复杂化奠定坚实基础。
平台建设:打造标准化的 StarRocks 管理体系
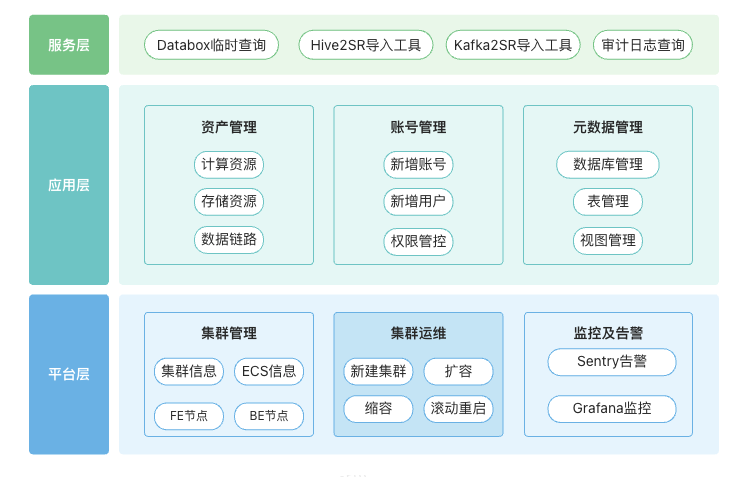
在迁移落地并取得显著成效之后,团队意识到要让 StarRocks 在多业务、多集群环境下持续稳定运行,仅依靠人工运维已无法满足规模化需求。
因此,哈啰自研了一套 OLAP 管理平台 ,以“ 全流程管控、全场景覆盖 ”为核心理念,实现对 StarRocks 集群的可视化管理与标准化运维。
平台整体聚焦集群管理、资产管理、权限管控及集群服务四大关键领域,通过模块化设计与标准化流程,构建起覆盖 StarRocks 运维全生命周期的管理体系。其核心模块包括:
- 集群管理模块: 精准记录 ECS 节点、FE 节点及 BE 节点的核心信息,实现节点状态全掌握。
- 资产管理模块: 统一管理各业务方的计算资源、存储资源,并清晰记录 StarRocks 表的上游写入数据链路。
- 权限管控模块: 双重管控业务方权限,既限制集群访问权限,也规范 StarRocks 表的查询权限,保障数据安全。
- 集群服务模块: 集成 StarRocks 运维与业务支撑所需各类工具,打造 “一站式服务平台”,大幅降低跨系统操作成本,核心功能包含:
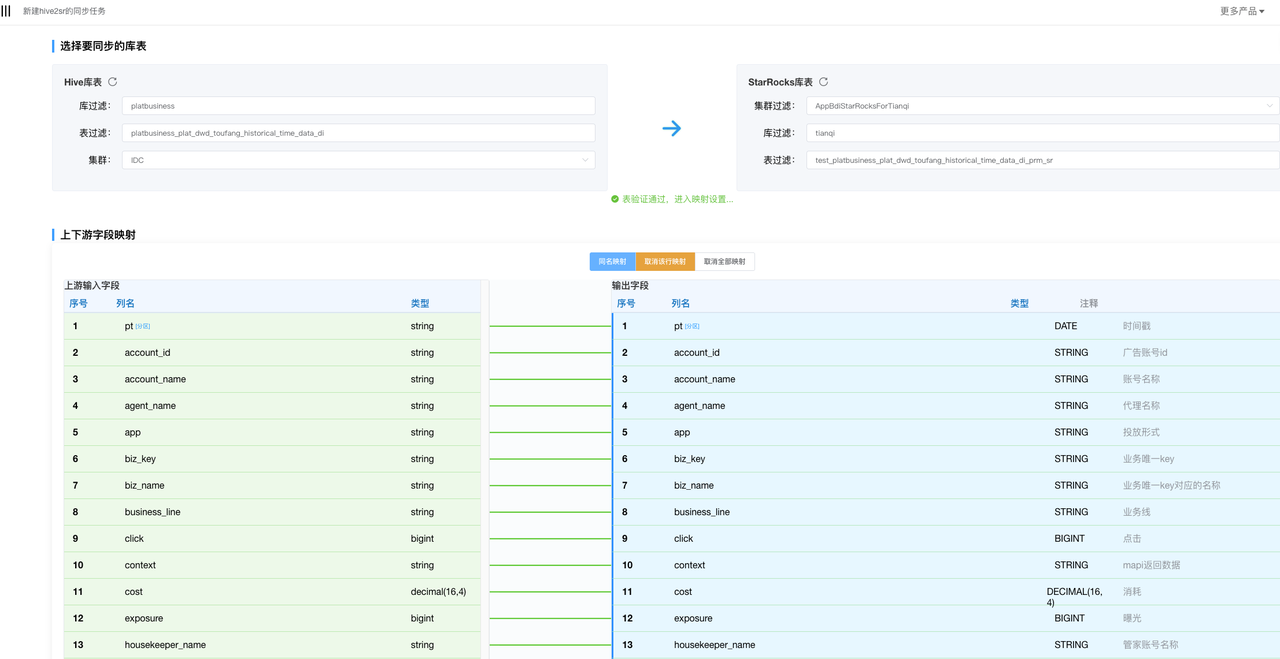
- 数据接入工具集成:内置 Hive2SR、Kafka2SR 工具操作界面,支持可视化配置数据同步任务(如选择数据源、设置同步频率、配置字段映射),并实时展示任务执行状态。
- 审计日志查询:提供高效查询功能,助力业务方快速定位慢查询问题。
- Databox 临时查询:简化取数流程,方便业务方快速获取并使用所需数据。
成效与价值
通过在核心业务场景中的规模化应用,StarRocks 不仅帮助哈啰解决了多业务线的数据处理痛点,更沉淀出一套可复用的技术与管理体系:
- 业务支撑升级: 从营销策略平台的实时画像分析,到两轮出行数据平台的复杂查询优化,StarRocks 将核心业务响应时间从分钟级降至秒级,推动业务从“事后分析”迈向“实时决策”,显著提升营销 ROI 与运营效率。
- 架构优化与成本降低: 通过多云部署与存算分离架构,StarRocks 满足哈啰的多环境战略需求,实现技术降本与资源利用率提升,资源利用率平均提升约 40%。
- 管理体系标准化:让规模化运维更简单
自研的 OLAP 管理平台覆盖集群运维、权限管理、数据接入等全流程功能,形成统一、可复用的技术管理体系。配套的迁移工具与监控方案也可复用于其他 OLAP 引擎替换场景,大幅提升新业务落地与扩展效率。
未来,哈啰将继续深化 StarRocks 的应用,探索其在实时数仓、湖仓一体、Data + AI 等场景的更多可能性,进一步释放数据价值,为出行业务的创新与增长提供更强力的技术支撑。