select count(*) from ods_xzf_t_mpos_trade_water where create_time>=‘2025-08-01 00:00:00’;
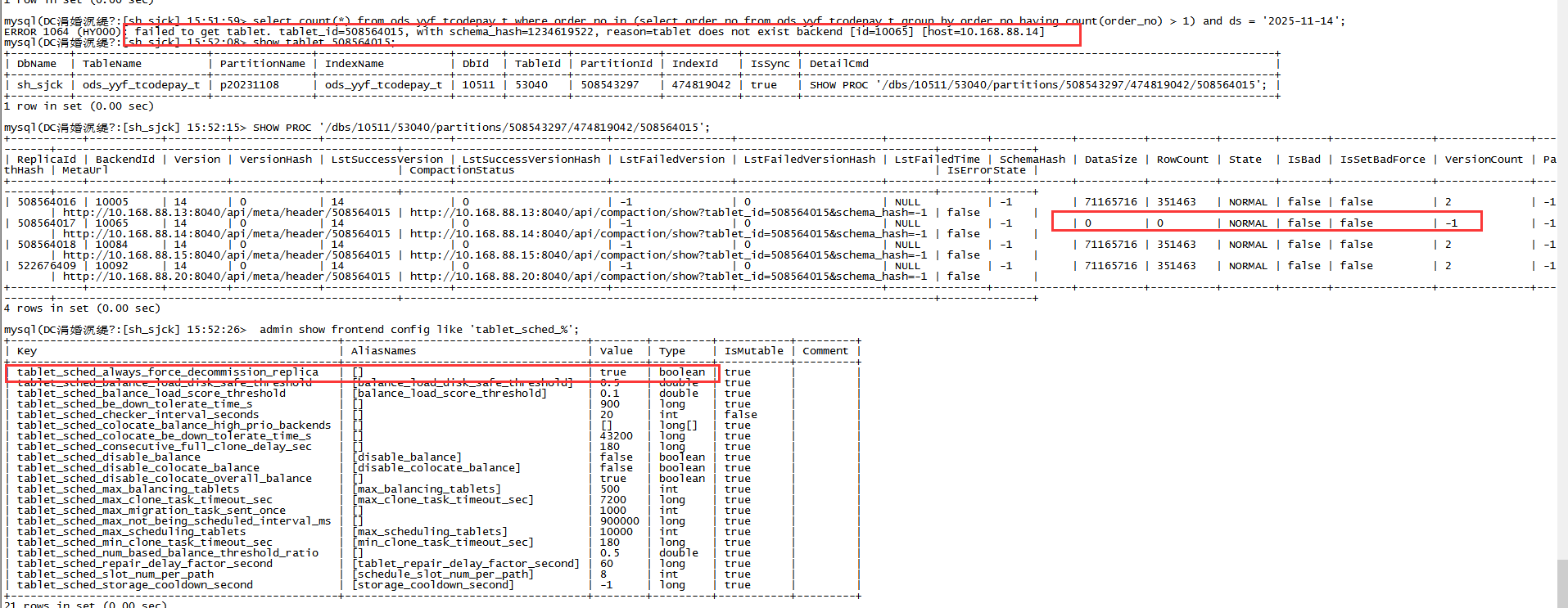
ERROR 1064 (HY000): failed to get tablet. tablet_id=328595869, with schema_hash=424008707, reason=tablet does not exist backend [id=10065] [host=10.168.88.14]
这是一个非常典型的 StarRocks FE 元数据不一致的问题,通常发生在集群拓扑结构发生变化(如您提到的 FE/BE 剥离、新增 FE)或 BE 节点出现故障时。
问题诊断:FE 元数据不一致
核心现象:
一个 FE 报错,其他 FE 正常。
报错信息:failed to get tablet. tablet_id=328595869, with schema_hash=424008707, reason=tablet does not exist backend [id=10065] [host=10.168.88.14]
问题 FE 上的副本状态: 存在一条 versioncount=-1 的记录,指向 BE 10.168.88.14。
分析:
FE 元数据同步机制: StarRocks 的 FE 节点通过 Raft 协议保持元数据一致性。Leader FE 负责写入,Follower FE 从 Leader 同步。
Tablet 不存在: 报错 FE 认为 tablet_id=328595869 应该存在于 BE 10.168.88.14 上,但当它尝试查询时,BE 告诉它“这个 Tablet 不存在”。
versioncount=-1: 这通常是 BE 节点在报告 Tablet 状态时,由于某些原因(如磁盘故障、数据损坏、Tablet 被删除但元数据未及时清理)无法提供正确的版本信息时出现的异常状态。
FE 剥离/新增 FE 导致的问题: 在集群拓扑变化时,如果新的 FE 节点在同步元数据时,恰好 BE 节点 10.168.88.14 上的这个 Tablet 处于异常状态,或者在同步过程中发生了 Leader 切换,可能导致这个新的 FE 节点(或同步失败的 FE 节点)的元数据中,关于这个 Tablet 的信息是错误的或过时的。
结论: 报错的 FE 节点上的元数据中,关于 Tablet 328595869 的信息是错误的,它错误地认为 BE 10.168.88.14 上存在一个可用的副本,而其他 FE 节点可能已经通过正常的健康检查机制,将该副本标记为不可用或已删除。
应急处理和后续影响分析
1. 应急操作分析
重启 FE 并用 --helper 启动: 这是一个正确的尝试,目的是让 FE 重新从 Leader FE 同步完整的元数据。但如果 Leader FE 上的元数据本身存在一些“脏数据”或同步机制在特定情况下失败,可能无法解决问题。
BE 节点操作:
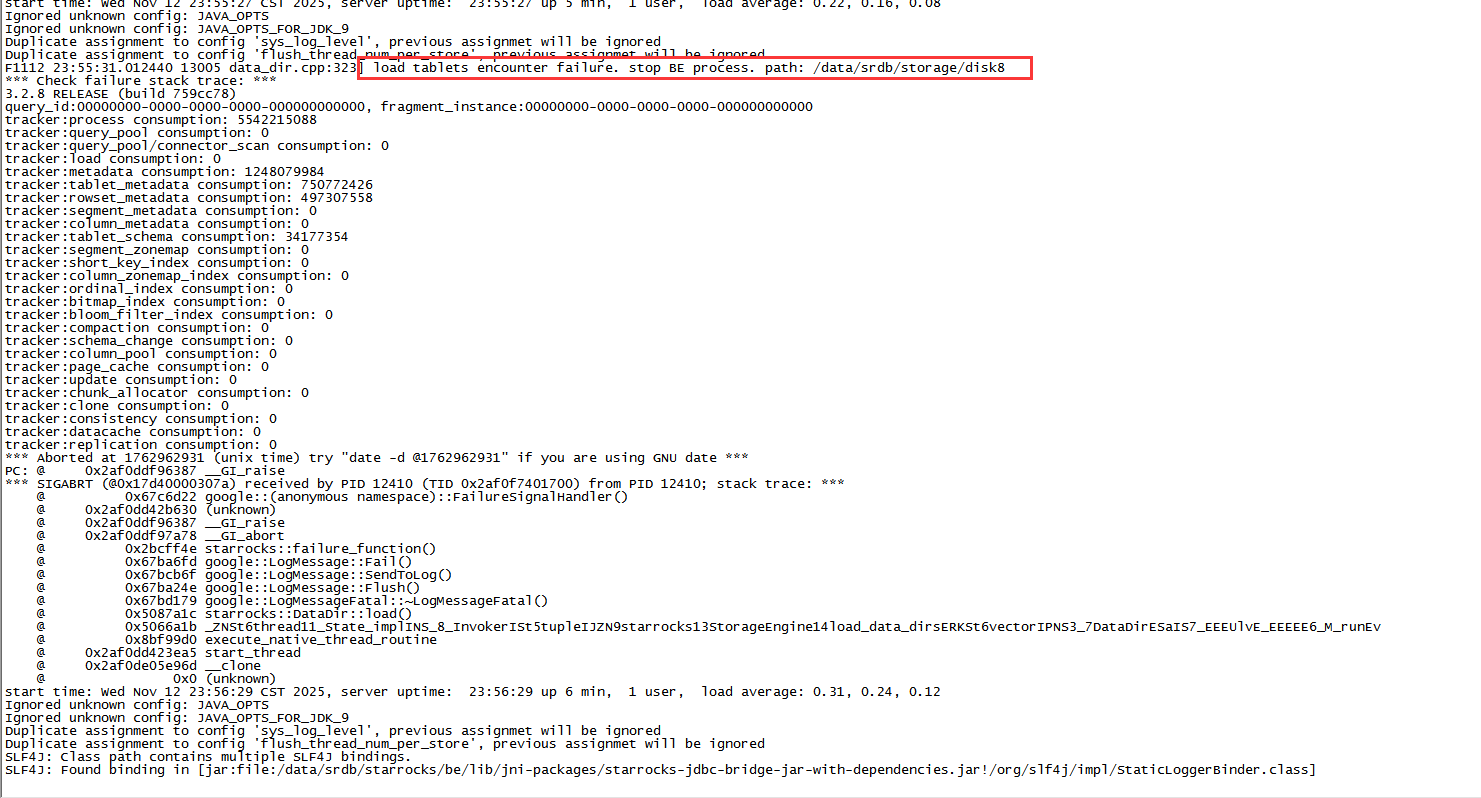
将 /data/srdb/storage/disk8 从 be.conf 去掉: 这是一个正确的应急操作。如果 BE 上的某个磁盘(disk8)出现问题,导致其上的 Tablet 无法访问(如 versioncount=-1),将该磁盘移除可以避免 BE 尝试使用该磁盘上的损坏副本。