

导读:
StarRocks 4.0 已正式发布!这一版本带来了多项关键升级。本篇聚焦 JSON 查询性能的系统性提升——通过全新的 FlatJSON 列式存储与执行优化机制,StarRocks 4.0 让 JSON 在实时分析场景中具备接近原生列存的性能。
无论是日志、埋点还是 IoT 数据,用户都无需额外 ETL,即可直接对 JSON 进行高性能查询分析,真正让“灵活的数据结构”与“高效的分析能力”兼得。
在实时分析场景中,日志、点击流、埋点、用户画像等数据几乎无处不在。这些数据通常以 JSON 格式存储——它灵活、通用、无需建模,尤其适合快速变化的业务场景:字段可以随时新增或删除,系统之间也能无障碍传输。
正因如此,JSON 成为互联网业务中最常见的数据格式。然而,当这种灵活的数据进入数据库,情况就截然不同了。
在日志分析或行为分析场景中,即便 SQL 写得没问题,查询仍可能迟迟跑不出来。
SELECT
get_json_string(event, '$.type') AS event_type,
COUNT(DISTINCT user_id)
FROM events_log
WHERE
get_json_string(event, '$.region') = 'US' AND
to_datetime(get_json_int(dt, '$.event_ts')) BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY event_type;
这条简单的 SQL 为什么这么慢?因为在数据库眼里,JSON 就是一块黑盒:
-
存储层需要将每一行的完整 JSON 读入内存;
-
即便 SQL 只访问其中少数字段,也必须读取整个对象;
-
过滤条件无法利用索引,只能全表扫描;
-
基于字符串的计算代价高,无法使用字典编码等优化手段。
看似只是过滤 region=‘US’、分组 event_type 并做一次去重计数,但执行时间可能长达几十秒。CPU 飙升、延迟高企——这并非 SQL 写得复杂,而是因为 JSON 最初并非为分析而设计的。
当 JSON 成为分析的基础时,它的优势很快就会变成劣势:
-
**存储臃肿:**字段名和值反复存储,空间占用大,压缩效果差;
-
**查询开销大:**字段读取操作需要遍历和搜索 JSON,CPU 消耗高
-
**Schema 变化快:**字段随时增减,历史数据不一致,建模困难;
-
**类型不统一:**同一字段在不同记录里类型不同,增加查询复杂度;
-
**字段数量多:**单条 JSON 常常包含上百字段,但查询通常只关心少数字段。
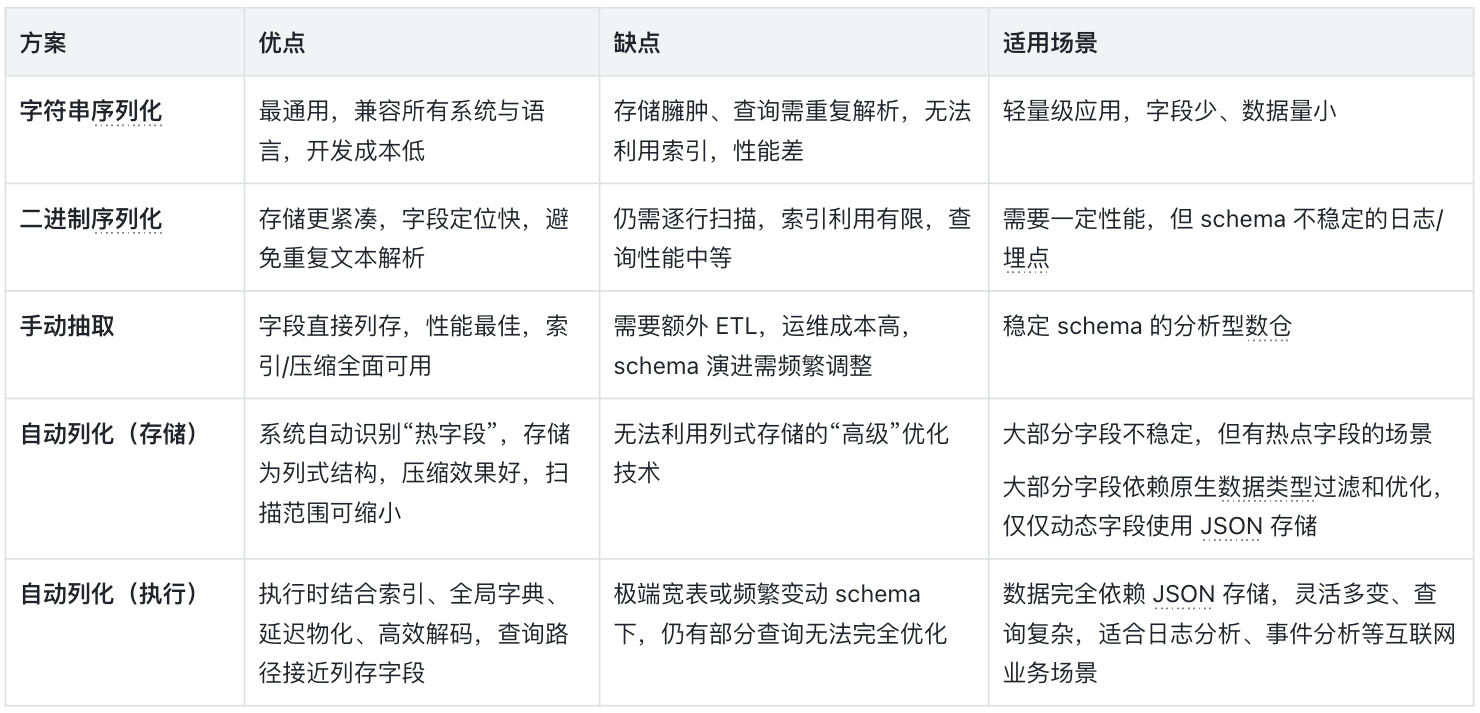
数据库的几种应对方案
多年来,工程师一直在尝试各种解决思路,大体可以分为三类:
-
二进制序列化:典型代表是 PostgreSQL 的 JSONB。这种方式在写入时就解析 JSON 字符串,并将其序列化为二进制格式,以减少查询阶段的字符串解析开销。这类方案能够一定程度上优化性能,但依然不适合 OLAP 场景,StarRocks 的早期版本也采用了类似思路。
-
用户手工抽取:传统数仓更倾向于让用户在 ETL 阶段手动将 JSON 字段展开成独立列。这种做法能获得接近列存的性能,但代价是维护复杂。在 StarRocks 中,用户也可以通过 Generated Column(生成列) 来实现类似能力,比如:
ALTER TABLE tbl ADD COLUMN json_event_type STRING AS get_json_string(event, '$.event_type') -
自动列化存储:理想的方向是让系统自动识别并抽取常用字段,实现“对用户无感知”的列式化存储。
不过,这种方案的实现极具挑战——系统需要智能地处理异构 schema、 schema 演进等复杂问题。因此,各数据库产品在这一方向的优化深度差异很大。
从 Binary JSON 到接近列存的 JSON
为了解决这些问题,StarRocks 在 2.3 版本支持了 Binary JSON,即以二进制序列化格式来存储 JSON,规避了每次解析字符串的开销,并且搜索字段时能够应用二分查找来降低 CPU 开销。但是即便如此,总体仍然是非常低效,以文首查询为例:
-
系统无法利用索引过滤,需要读取所有 JSON 数据,带来巨大的 I/O 放大
-
每一行都要多次
get_json_*,解析region、event_type、user_id -
过滤条件
region='US'需要逐字符比较,CPU 热点函数可能 80-90% 都耗在解析和比较上 -
聚合阶段又要基于字符串做哈希和去重,无法利用字典编码进行优化
哪怕只有几千万行数据,这样的查询依旧可能需要几十秒。
JSON 能力的持续演进
在持续优化 JSON 查询性能的过程中,StarRocks 逐步实现了从“字符串存储”到“列式存储”的演进:
-
2.3 之前:不支持原生 JSON,仅能以字符串形式存储;
-
2.3 版本:引入 JSON 类型,采用二进制序列化格式,并补充丰富的 JSON 查询函数;
-
3.3 版本:推出 FlatJSON 列式存储,自动将 JSON 中的高频字段列化,使存储层性能首次接近列存;
-
4.0 版本:在执行层加入 索引、全局字典、延迟物化 等优化,使 JSON 查询性能接近原生列存字段。
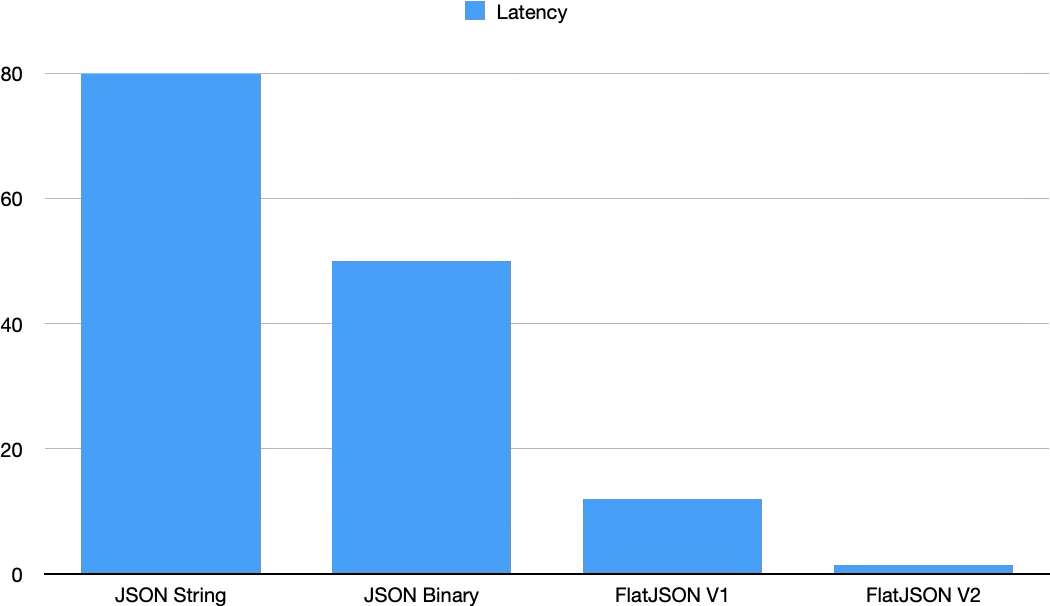
性能差异直观对比
在深入技术细节之前,可以先直观感受不同方案带来的性能差异。以文首相同的查询为例,不同版本的 JSON 实现具有显著的性能差异:
接下来,本文将从技术原理角度展开介绍 FlatJSON 如何实现“既灵活又高效”的存储与查询能力。
FlatJSON 列式存储
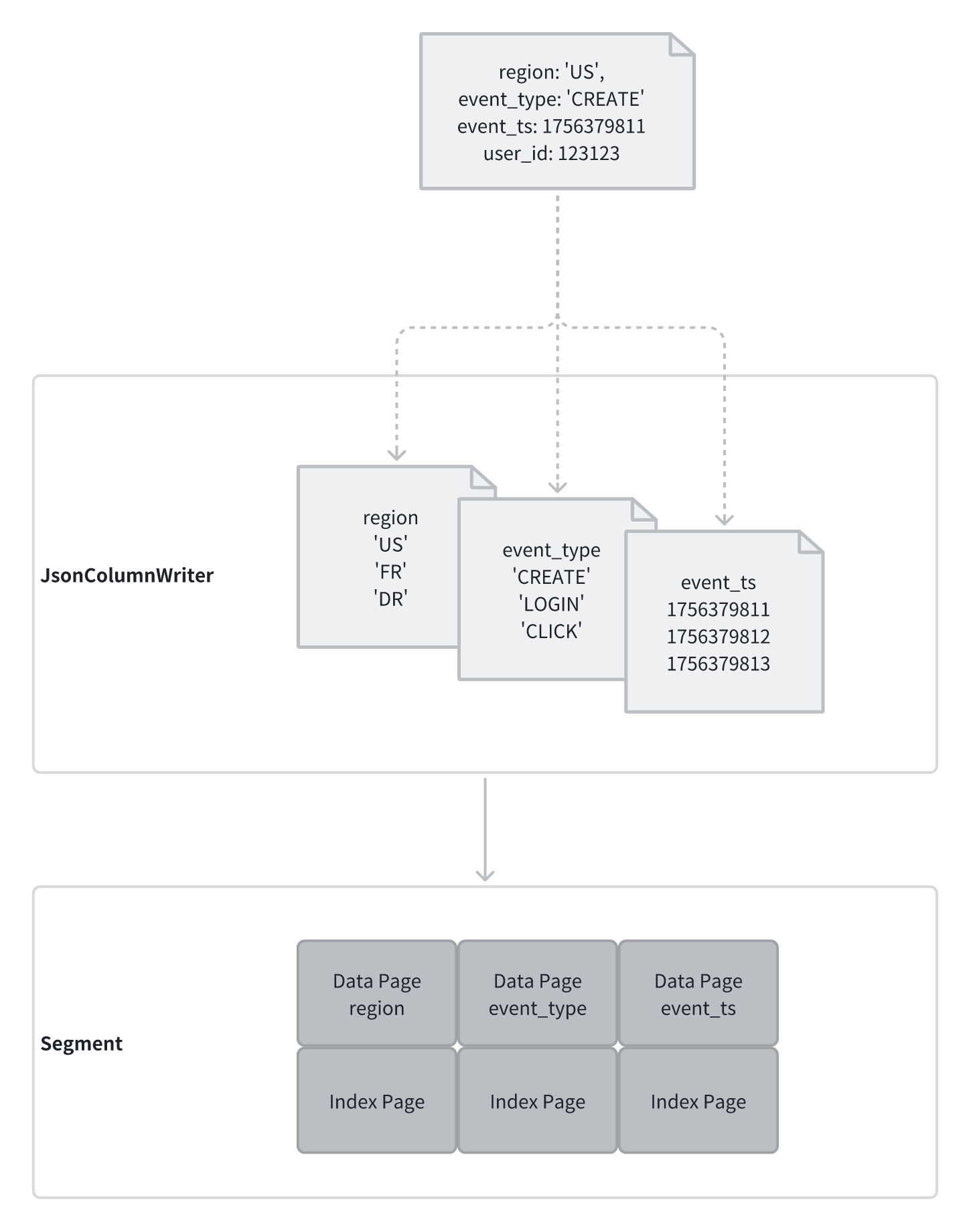
要理解 FlatJSON 的设计原理,首先需要回顾 StarRocks 的基础存储结构:
-
Segment 是 StarRocks 的最小文件存储单元,通常大小约为 1GB,每次导入数据至少会生成一个 Segment 文件;
-
Segment 采用列式存储格式,每个列(Column)独立存储为多个 Page,Page 层面支持 Encoding + Compression;
-
Segment 内部支持多种索引:默认会创建轻量级索引(如 ZoneMap、SortKey Index),同时支持按需构建复杂索引(如 Bitmap Index、Bloomfilter Index);
-
数据在写入时会根据用户指定的 ORDER BY 进行排序。
基于这一架构,FlatJSON 在数据导入阶段进行列化存储:
-
扫描 JSON 键集合,统计字段频率,识别出“热字段”(例如每条记录都包含 “region” 字段);
-
自动推断字段类型——能以数值存储的字段绝不存为字符串,对于多类型字段选择可兼容的公共类型;
-
将识别出的字段单独存储为列式格式(如 INT、STRING、DOUBLE 等);
-
对低频或不固定字段,统一写入一个“冗余列”,以 JSON 类型存储,作为兜底方案。
经过这一过程,原本需要层层解析的 JSON 数据,在物理存储上被转化为一张“半结构化表”。
在 Segment 文件内部,这些字段已经与普通列无异——可被按需读取,也能创建索引。
为什么 FlatJSON 更快?
-
列存压缩更高效:低基数字段(如 region)可使用字典编码,减少存储空间;
-
消除冗余存储:无需重复存储 JSON key;
-
I/O 成本更低:查询只需读取被列化的字段;
-
免解析执行:查询阶段不再解析 JSON 字符串,直接读取 Segment 文件中的列数据
SELECT
get_json_string(event, '$.type') AS event_type,
COUNT(DISTINCT user_id)
FROM events_log
WHERE
to_datetime(get_json_int(dt, '$.event_ts'))
BETWEEN '2024-01-01' AND '2024-12-31'
AND get_json_string(event, '$.region') = 'US'
GROUP BY event_type;
回到文首的示例查询:
-
存储引擎只需读取 $.type、$.event_ts、$.region 这几个被列化的字段,无需再加载完整的 JSON 数据;
-
对于表达式 get_json_string(event, ‘$.type’),系统不再解析 JSON 字符串,而是直接读取 Segment 文件中的对应列。
得益于这种列式化设计,JSON 性能有了质的飞跃!
FlatJSON 列式查询
在存储实现列化之后,执行层的优化同样关键。以下将介绍 FlatJSON 在执行阶段的四项核心技术,以及它们如何进一步提升查询性能。
- 索引(Index):把大海捞针变成定向查找
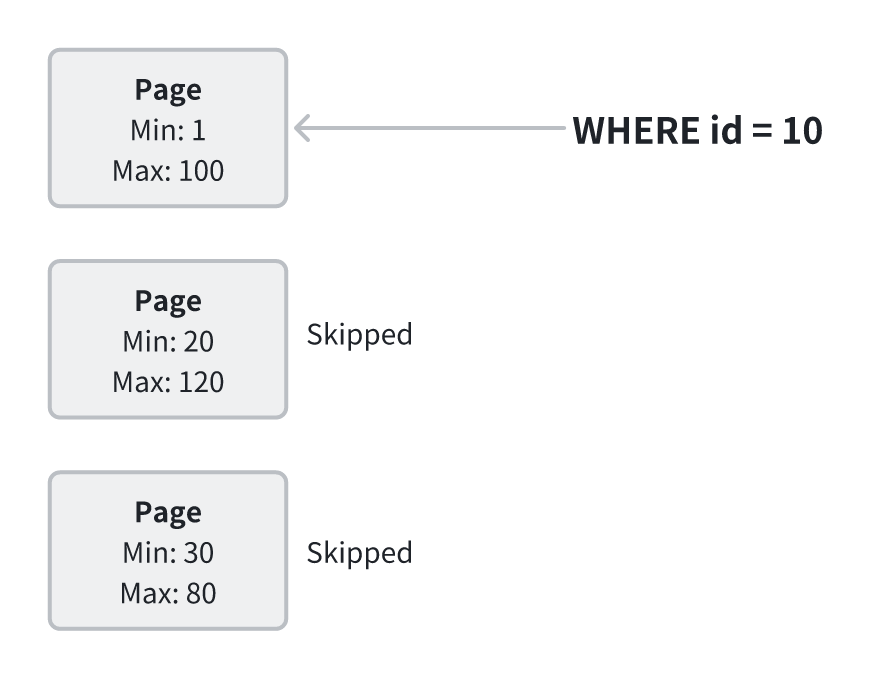
为避免全表扫描,FlatJSON 支持在已列化字段(如 region、event_time、event_type)上创建合适的索引,例如 ZoneMap。ZoneMap 会记录每个 Page 的最小值和最大值,在查询时可据此快速判断哪些 Page 可能命中过滤条件,从而跳过无关数据。
性能提升的核心来自于扫描量的降低:
-
通过利用过滤条件的选择度,系统可以直接跳过无关的数据块,将 I/O 成本从“全表扫描”降至“部分数据读取”。这种方式在谓词选择度较高的场景(例如 region=‘US’ AND dt BETWEEN …)中效果最为显著;当分区键或排序键与查询条件对齐时,收益会进一步提升。
-
若查询条件选择度较低,或使用模糊匹配(如 LIKE ‘%xx’),索引过滤的效果会受到限制。
-
但在多数典型分析场景中,通过 ZoneMap 过滤,I/O 开销仍能减少一个数量级,从而显著提升整体查询性能。
- 高效解码(Dictionary Decoding)
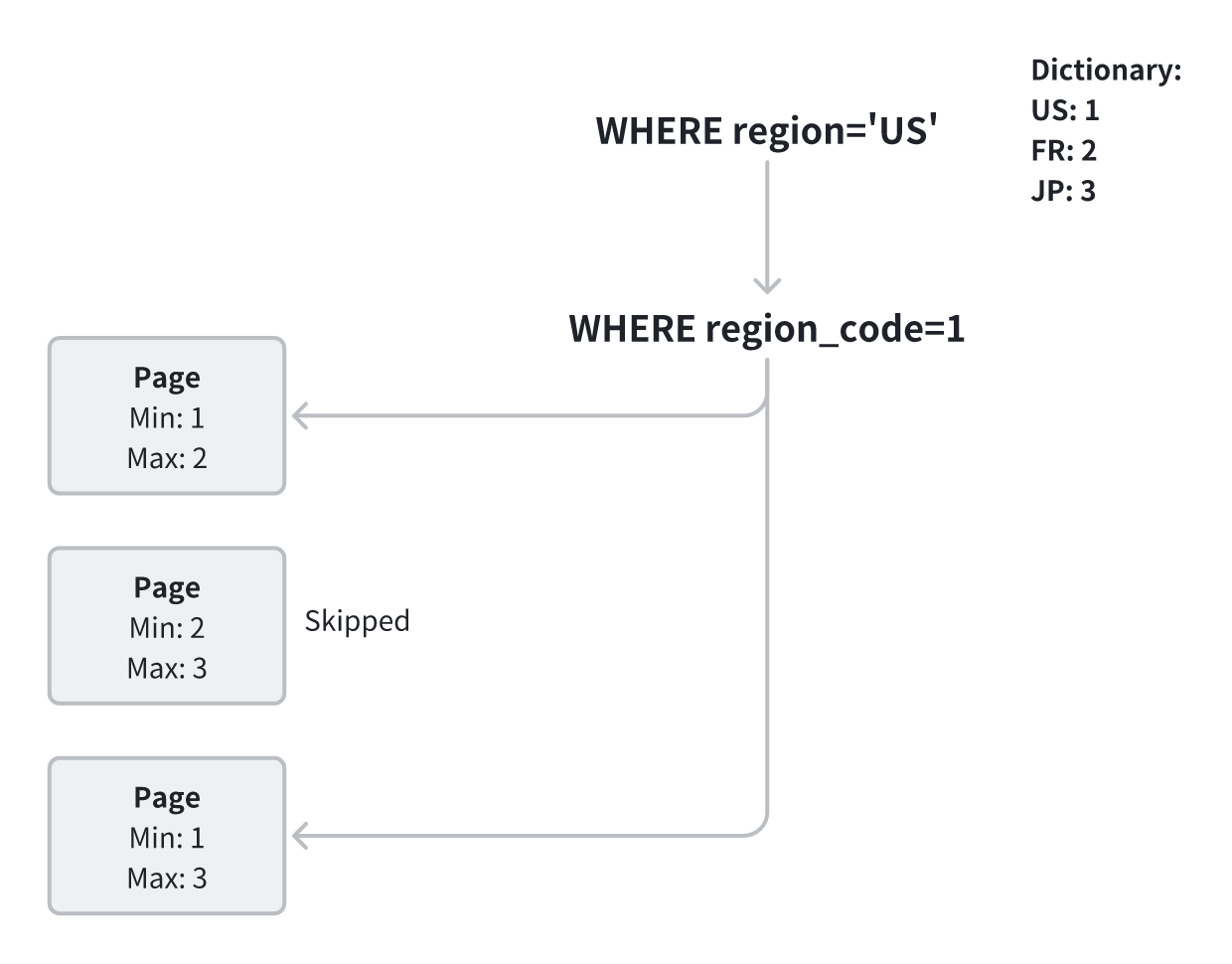
对于低基数字符串字段,Segment 在写入时会自动进行字典编码。以 region 字段为例,系统会将其拆分为两部分存储:字典和字典码,从而消除重复字符串。
在查询执行阶段,StarRocks 会对字典编码数据进行谓词改写:例如 region=‘US’ 会被改写为 region=1,然后利用索引直接过滤对应的数据块。这种方式避免了频繁的字符串比较,计算更轻量,内存与 I/O 效率均明显提升。
在完成过滤后,系统再将字典码翻译回实际字符串,用于计算。
- 延迟物化(Late Materialization)
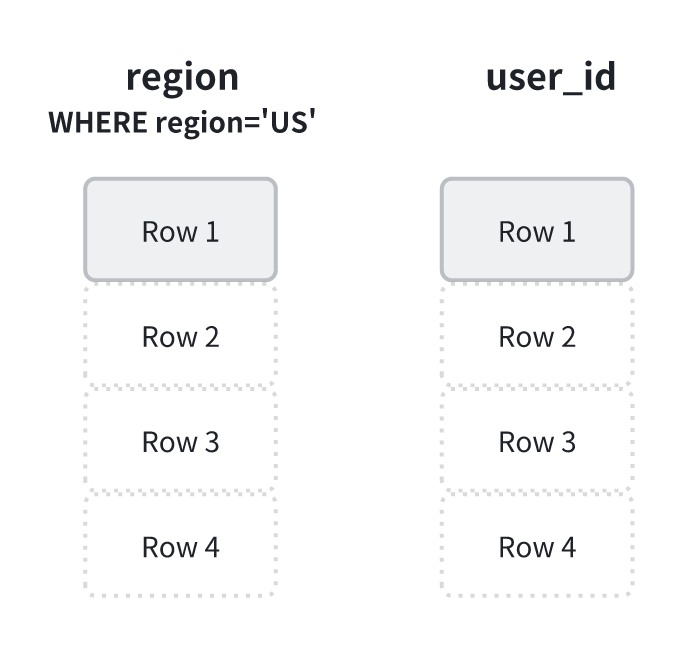
在传统的执行路径中,数据库通常会在过滤之前就将整行数据解码。这意味着,即使最终被过滤掉的记录,也已经付出了完整的解析与对象创建成本。
延迟物化的思路正好相反:在初始阶段仅使用轻量级的数据结构(例如行号)来表示记录,在完成所有过滤操作之后,再根据筛选结果去读取真正需要的列。以 region=‘US’ 为例,StarRocks 会先读取并过滤 region 字段,仅记录满足条件的行号。随后再按照这些行号读取 user_id 字段,从而避免无谓的数据加载。
延迟物化的核心在于延后不必要的计算与解码:它减少了 I/O 读量,提高了缓存命中率,并让 CPU 资源集中用于真正需要的数据。
因此,在低选择度的查询中,这一机制能显著降低无效计算成本。
- 全局字典(Global Dictionary):把字符串降维成整数计算
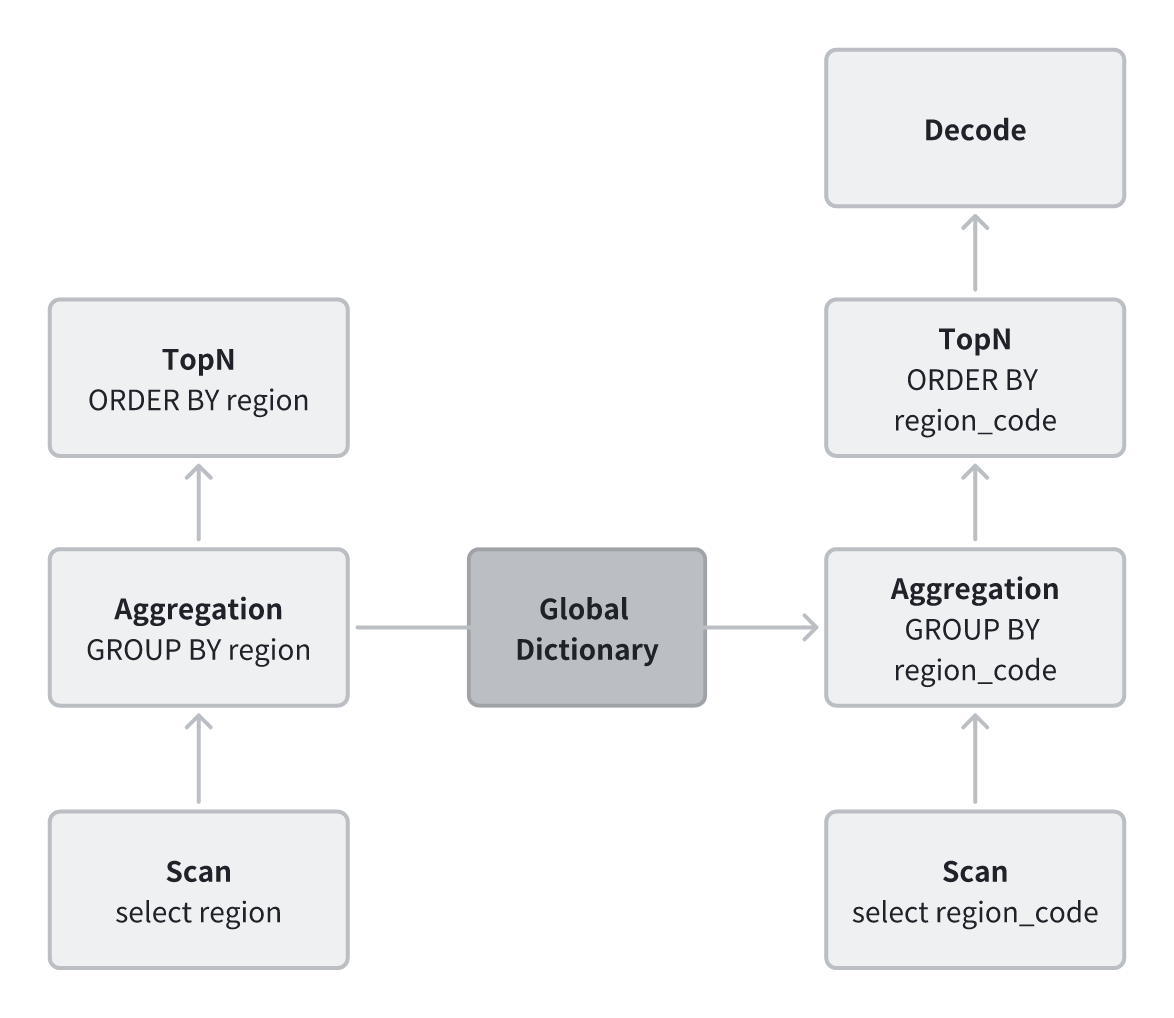
在 StarRocks 中,字符串一直是影响查询性能的关键因素。无论是过滤还是聚合,都需要进行逐字符比较或字符串哈希,不仅消耗大量 CPU,还容易破坏缓存局部性。为此,StarRocks 在 Segment 局部字典的基础上引入了 全局字典,通过汇总各节点的局部字典,构建出统一的全局映射表。
有了全局字典,字典编码的使用范围不再局限于单个 Segment,而可扩展到 聚合、排序、关联等计算场景。原本昂贵的字符串运算被“降维”为整数运算:CPU 只需执行轻量的整型比较或哈希操作,缓存命中率显著提升,哈希表也更紧凑、更高效,聚合时的冲突率大幅降低。
例如,原本的 GROUP BY region 操作需要在哈希表中频繁进行字符串查找和更新;使用全局字典后,执行计划可改写为 GROUP BY region_code,以整数完成聚合,仅在最终输出阶段再将整数解码为字符串,从而显著减少计算开销。
- 小结对比
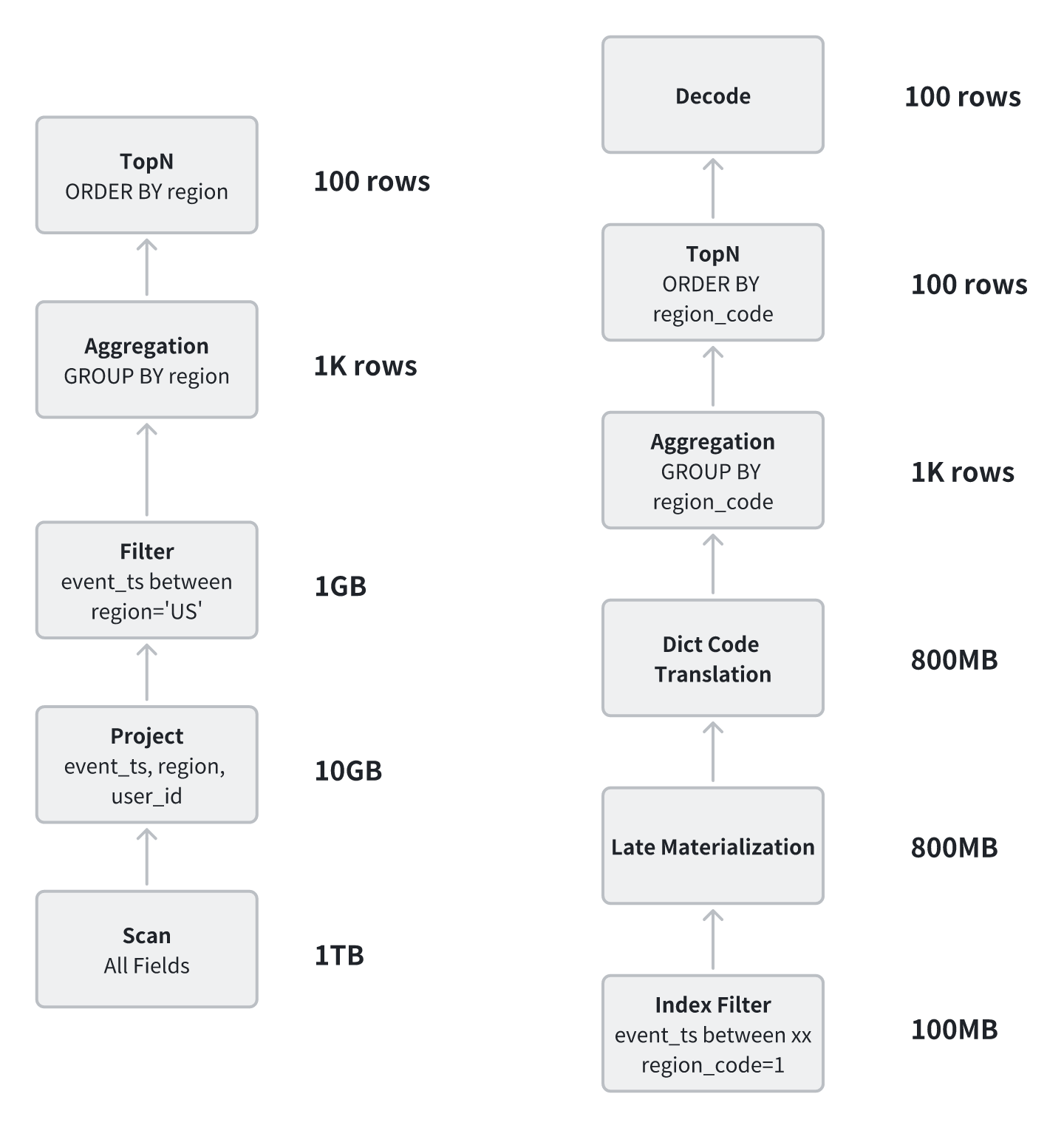
回到文首的示例,可以直观看出两种执行方式的差异:
-
传统 JSON 查询:读取完整 JSON → 路径解析 → 类型转换 → 执行过滤与聚合;
-
FlatJSON 查询:直接命中列存字段 → 索引与字典过滤 → 全局字典计算 → 延迟解码。
相比传统方式,FlatJSON 在执行路径上大幅减少了解析、比较和全量扫描等开销。
在实际测试中,对 10 亿行 JSON 数据执行相同的聚合查询,传统方式可能耗时约 30 秒,
而基于 FlatJSON 的查询仅需 约 500 毫秒,I/O 与 CPU 成本均降低了数个数量级。
业务场景的真实收益
在真实的业务场景中,FlatJSON 的价值不仅体现在性能提升上,更体现在对灵活性与易用性的平衡。
- 埋点日志分析
痛点:实时看板需要对最新埋点数据进行聚合和分组,通常涉及数十亿行 JSON。传统模式下,查询需要逐行解析 JSON,返回结果往往需要数十秒甚至更久;同时,埋点字段变化频繁,新字段出现时必须修改 ETL 流程。
FlatJSON 方案:在数据导入阶段,系统会自动将常用字段(如 user_id、event_time、region、event_type 等)拍平成列存格式。新字段出现时,不会影响现有查询,用户仍可通过 JSON 函数直接访问,系统会根据访问频率判断是否列化。
收益:查询延迟从数十秒降至数百毫秒;同时兼容频繁变化的埋点 schema,分析团队无需因字段变更频繁修改表结构或 ETL 流程。
- 电商报表生成
痛点:电商订单数据通常以 JSON 形式存储,包含 SKU、价格、促销、地域、配送等上百个字段。传统方案依赖复杂的 ETL 流程来抽取字段,开发与维护成本高;当字段新增或类型不一致(例如 price 既可能是字符串也可能是数值)时,整个数据流水线容易出错。
FlatJSON 方案:在导入阶段,FlatJSON 自动识别并列化高频字段,同时保留完整的 Binary JSON 结构。即使 schema 动态变化或字段类型异构,查询仍可正常执行,常用字段的访问性能依旧接近原生列存。
收益:报表生成时间从分钟级缩短至秒级,开发和运维团队无需频繁调整 ETL 流程,分析团队能更快速地响应业务变化。
- IoT 实时监控
痛点:IoT 设备上报的数据通常以 JSON 格式存储,包含数十个指标,不同型号设备间的字段差异显著(异构 schema 十分常见)。传统模式下,数据库需要完整解析 JSON;若字段缺失或类型不一致,查询容易退化甚至报错。
FlatJSON 方案:FlatJSON 会在导入阶段自动将高频指标(如温度、湿度等)列化存储,其余字段保留在 Binary JSON 中。查询时系统能自动跳过不存在的字段,避免执行错误;对于类型不一致的字段,执行层可进行统一处理或延迟物化。
收益:支持千万级设备数据的实时聚合,能够在秒级生成监控报表。同时,IoT 场景中的动态与异构 schema 由系统自动处理,显著减少人工清洗和建模成本。
FlatJSON 不仅解决了性能问题,也让动态 schema 与异构 schema 成为可控的系统成本。对开发者而言,不必再因字段新增、缺失或类型不一致而焦虑;对分析师而言,依旧可以通过 SQL 自由查询,而无需担心底层数据结构的频繁变化。
如何使用 FlatJSON
FlatJSON 的启用方式非常简单,使用方法与标准 JSON 类型几乎相同。
-- Minimal table with a JSON column and FlatJSON enabled
CREATE TABLE events_log (
dt DATE,
event_id BIGINT,
event JSON
)
DUPLICATE KEY(`dt`, event_id)
PARTITION BY date_trunc('DAY', dt)
DISTRIBUTED BY HASH(dt, event_id)
PROPERTIES (
"flat_json.enable" = "true", -- enable FlatJSON for this table
"flat_json.null.factor" = "0.3" -- optional: skip extracting too-sparse fields
);
可以通过表属性来开启或关闭 FlatJSON;新导入的 JSON 数据会自动被列化存储。
此外,还可以通过参数 flat_json.null.factor 设置阈值,以避免抽取过于稀疏的字段。
插入几行示例数据
INSERT INTO events_log VALUES
('2025-09-01', 1001, PARSE_JSON('{
"user_id": 12345, "region": "US", "event_type": "click", "ts": 1710000000
}')),
('2025-09-01', 1002, PARSE_JSON('{
"user_id": 54321, "region": "CA", "event_type": "purchase", "ts": 1710000300,
"experiment_flag": "A" -- rare field, remains in JSON fallback
}'));
像平常一样使用 JSON 函数进行查询。
-- Filter + group on fields that FlatJSON likely extracted (high-occurrence)
SELECT
get_json_string(event, '$.event_type') AS event_type,
COUNT(*) AS cnt
FROM events_log
WHERE
get_json_string(event, '$.region') = 'US'
AND get_json_int(event, '$.ts') BETWEEN 1710000000 AND 1710003600
GROUP BY event_type;
总结
FlatJSON 为 JSON 在数据库中的处理提供了一种工程化的解决路径。在存储层,FlatJSON 通过自动列化高频字段,提高压缩率并显著降低扫描成本;在执行层,则结合索引、全局字典和延迟物化等优化技术,减少了解析与解码开销。实际测试表明,在相同 SQL 下,查询延迟可从数十秒下降至亚秒级。
对于用户来说,无需再在“灵活性”和“性能”之间反复取舍。埋点、日志、IoT 等动态 schema 的数据可以直接写入 StarRocks,既能支持快速变化的业务需求,又能提供稳定可预期的查询性能,从而降低建模和 ETL 成本,让团队更专注于业务分析本身。