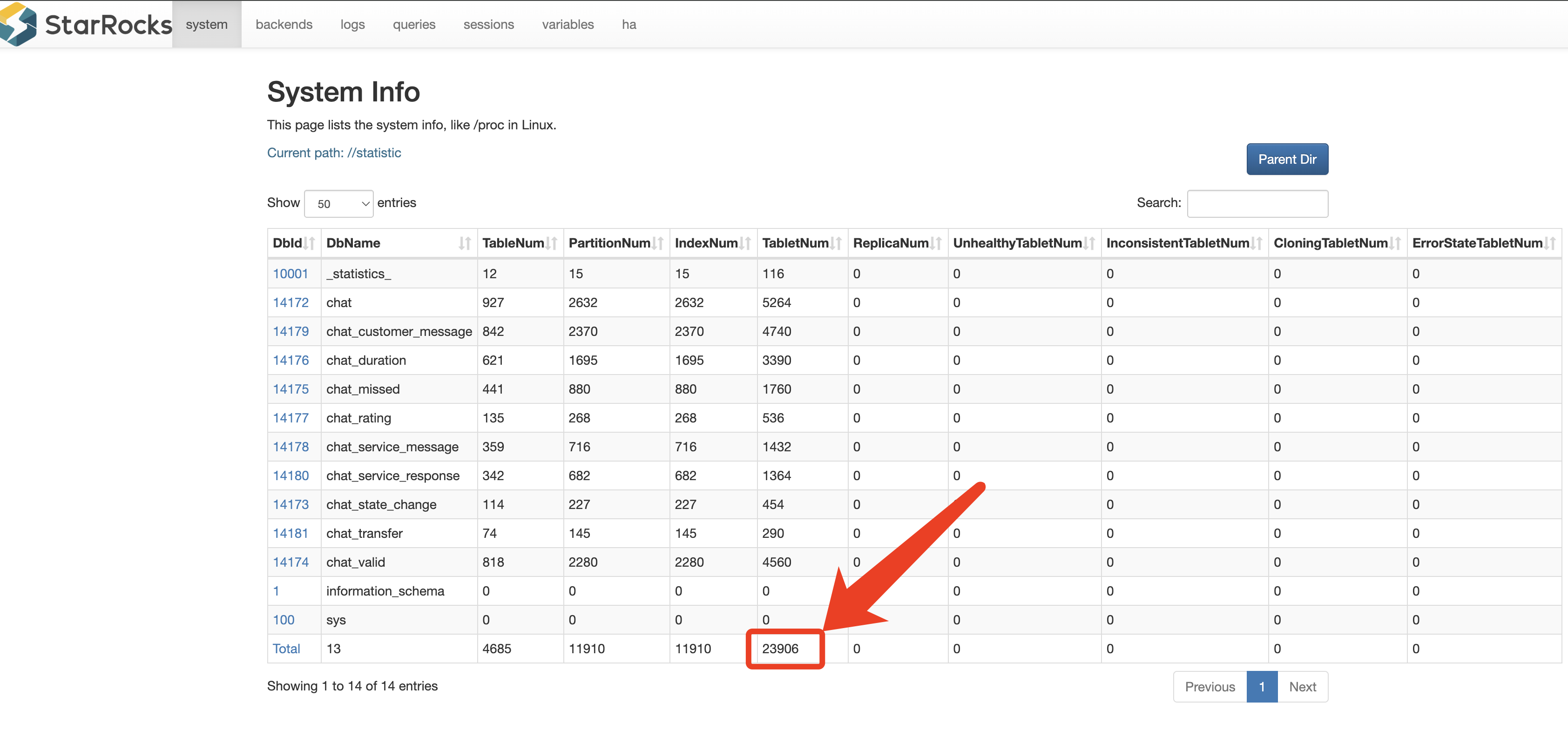
您遇到的 CN 节点内存耗尽并崩溃的问题,很可能与您 1.6 万张表 的数量以及 StarRocks 的内存管理机制有关,特别是 CN 节点对元数据的处理方式。
核心原因分析:表数量过多导致的元数据压力
虽然您的 数据导入量 (200MB/天)很小,但 1.6 万张表 的数量对 StarRocks 的内存消耗是巨大的。
1. CN 节点与元数据
CN 节点(Compute Node) 的主要职责是查询计算,但它也需要维护一份**元数据(Metadata)**的缓存,以便进行查询规划和数据路由。
-
FE 节点(Frontend) :FE 节点是元数据的核心管理者,它将 所有 元数据(包括数据库、表、分区、索引、统计信息等)完整地加载到内存中。您从 8GB 升级到 16GB 解决 FE 崩溃问题,正是因为元数据量超过了 8GB 的限制。
-
CN 节点 :CN 节点虽然不存储完整的元数据,但它会从 FE 同步并缓存必要的元数据信息。 表数量越多,CN 节点需要缓存的元数据对象就越多,占用的内存就越大。 即使是元数据的缓存,1.6 万张表也会产生巨大的内存开销。
2. 内存消耗的组成
CN 节点的内存消耗主要包括:
-
元数据缓存: 1.6 万张表的元数据对象。
-
查询执行内存: 即使是 Stream Load 导入,CN 也会参与数据预处理和写入,需要内存来处理导入任务。
-
Tablet/Segment 句柄: 维护大量表的 Tablet 和 Segment 句柄也会占用内存。
3. 内存碎片和 JVM 压力
CN 节点(在 StarRocks 3.x 版本中,CN 节点通常基于 C++ 实现,但其内部组件和依赖可能仍有内存管理开销)和 FE 节点(基于 Java/JVM)都会面临内存压力。
-
FE 内存: 1.6 万张表的元数据可能已经占用了 16GB FE 内存的大部分。
-
CN 内存: 即使 CN 节点设置了
mem_limit = 70% ,如果元数据缓存和导入任务的内存需求超过了剩余的 30% 或总体的 16GB 限制,就会导致 OOM(Out of Memory)崩溃。
结论和建议
是的,对于您这种表数量极多的场景,CN 节点也需要较大的内存配置。 内存需求不是由数据量(200MB/天)决定的,而是由**元数据量(1.6 万张表)**决定的。
1. 内存配置建议
-
CN 节点: 16GB 内存对于 1.6 万张表来说是不足的。 建议将 CN 节点的内存升级到 32GB 或 64GB 起步 ,以确保有足够的空间容纳元数据缓存和后续的查询计算。
-
FE 节点: 既然 16GB 已经稳定,可以暂时保持,但如果未来表数量继续增加,FE 内存也需要相应提升。
2. 架构优化(更重要的长期解决方案)
按租户分表(1.6 万张表)在任何 OLAP 系统中都是一个极端的做法,会给系统的元数据管理带来巨大压力。
强烈建议您重新设计表结构,使用一个或少数几个大表,并通过列来区分租户:
-
使用一个大表 + 租户 ID 列:
- 创建一个统一的表,包含一个
tenant_id 列。
- 所有租户的数据都导入到这个大表中。
- 查询时,通过
WHERE tenant_id = 'xxx' 来过滤数据。
-
使用分区(Partition)或 Colocate Group:
- 如果租户数量可控,可以考虑使用分区来管理数据生命周期,但 1.6 万个分区也是一个巨大的数字。
- 如果查询隔离性要求高,可以考虑使用 StarRocks 的 Colocate Group 或 Database 来进行逻辑隔离,而不是物理分表。
这样做的好处:
-
大幅减少元数据: 表数量从 1.6 万降到 1 个或少数几个。
-
降低内存消耗: FE 和 CN 节点的元数据压力将彻底解除。
-
提高查询效率: 优化器在处理少量大表时效率更高。
总结: 请先尝试升级 CN 节点的内存到 32GB 或 64GB 来解决当前的崩溃问题。同时,将表结构优化(从 1.6 万张表改为少数几张大表)作为长期和根本的解决方案。