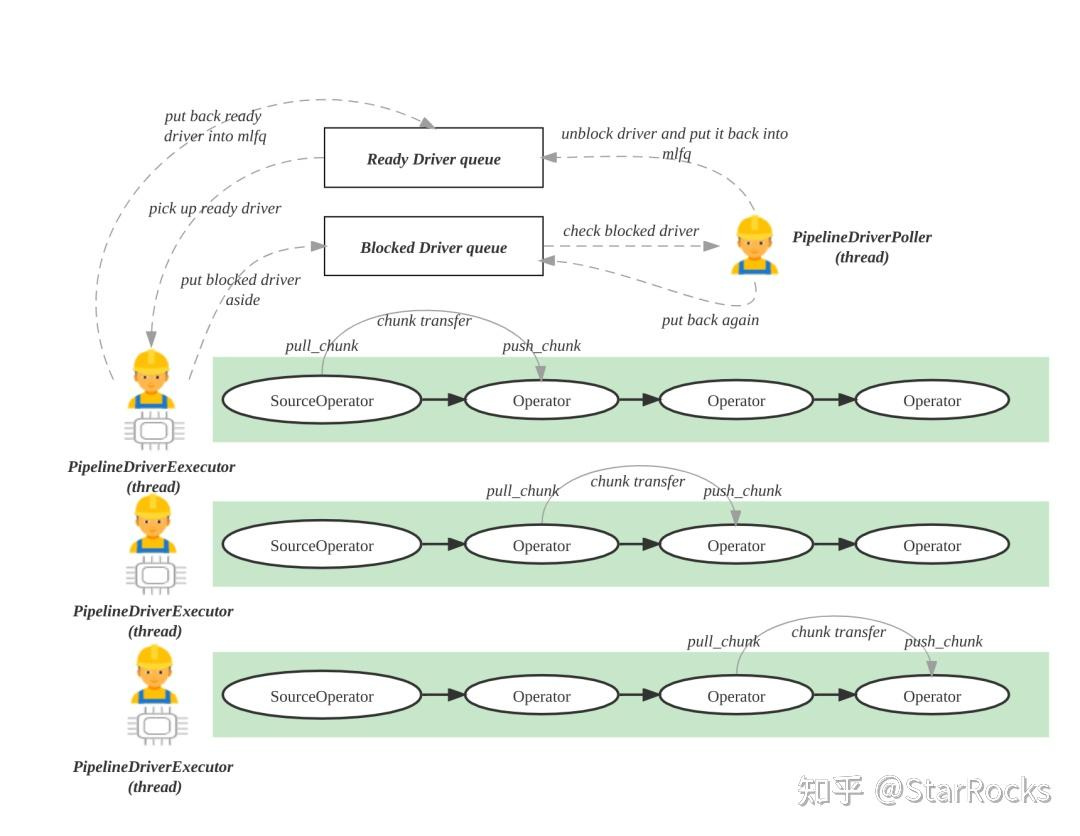
如果在不考虑算子本身内存消耗的情况下, 只考虑chunk消耗的内存.
那么每个算子在push_chunk后都会pull_chunk, 那四个算子就会占用4个chunk的内存? 可以这样理解吗?
有没有办法限制pipeline执行器, 整条流水线只能同时处理一个chunk?
因为我们现在遇到一个问题, 在处理大json字段的数据时内存消耗过大, json字段单行数据量1MB, 4096行的chunk_size会导致单个chunk消耗4G内存, 但是实际内存消耗会比较大(怀疑是流水线上同时加载的chunk过多), 导致sql经常内存溢出.