StarRocks 管理员 跨集群数据表同步工具

- 集成MySQL外表,ENGINE=MYSQL。
- 集成StarRocks外表,ENGINE=OLAP。
- 集成Jdbc Catalog。
- 集成官方starrocks-cluster-sync-2.0
- 集成兼容所有StarRocks版本
- 支持一键创建MySQL、StarRocks外表,支持跨集群克隆表结构,迁移数据。
- 支持迁移方式v1:源、目标容量级别,容量批次导入。
- 支持迁移方式v2:源、目标分区稽核,单分区覆写。
- 支持迁移方式v3:源、目标分区稽核,多攒批覆写。
- 支持迁移方式v4:仅对目标分区稽核,单分区覆写。
- 支持迁移方式v5:仅对目标分区稽核,多攒批覆写。
- 支持指定一次性初始化,或流式增量。
- 支持定时通知迁移进度到飞书群组。
- 支持自定义迁移分区。
- 支持自定义设置作业并发度。
模拟场景:
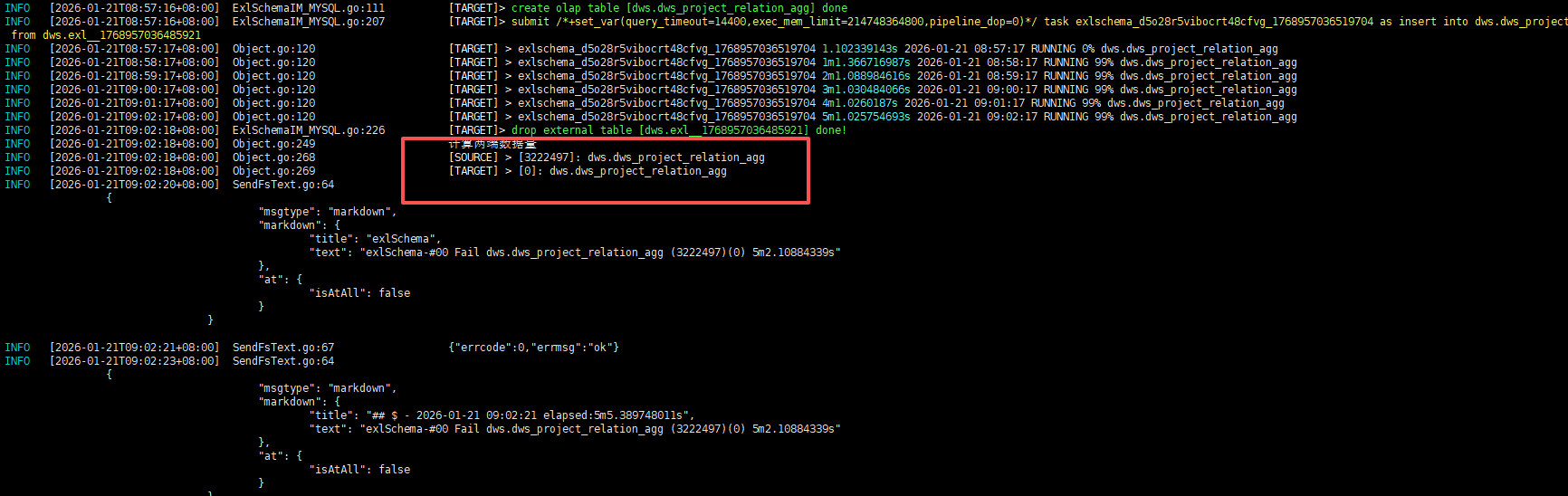
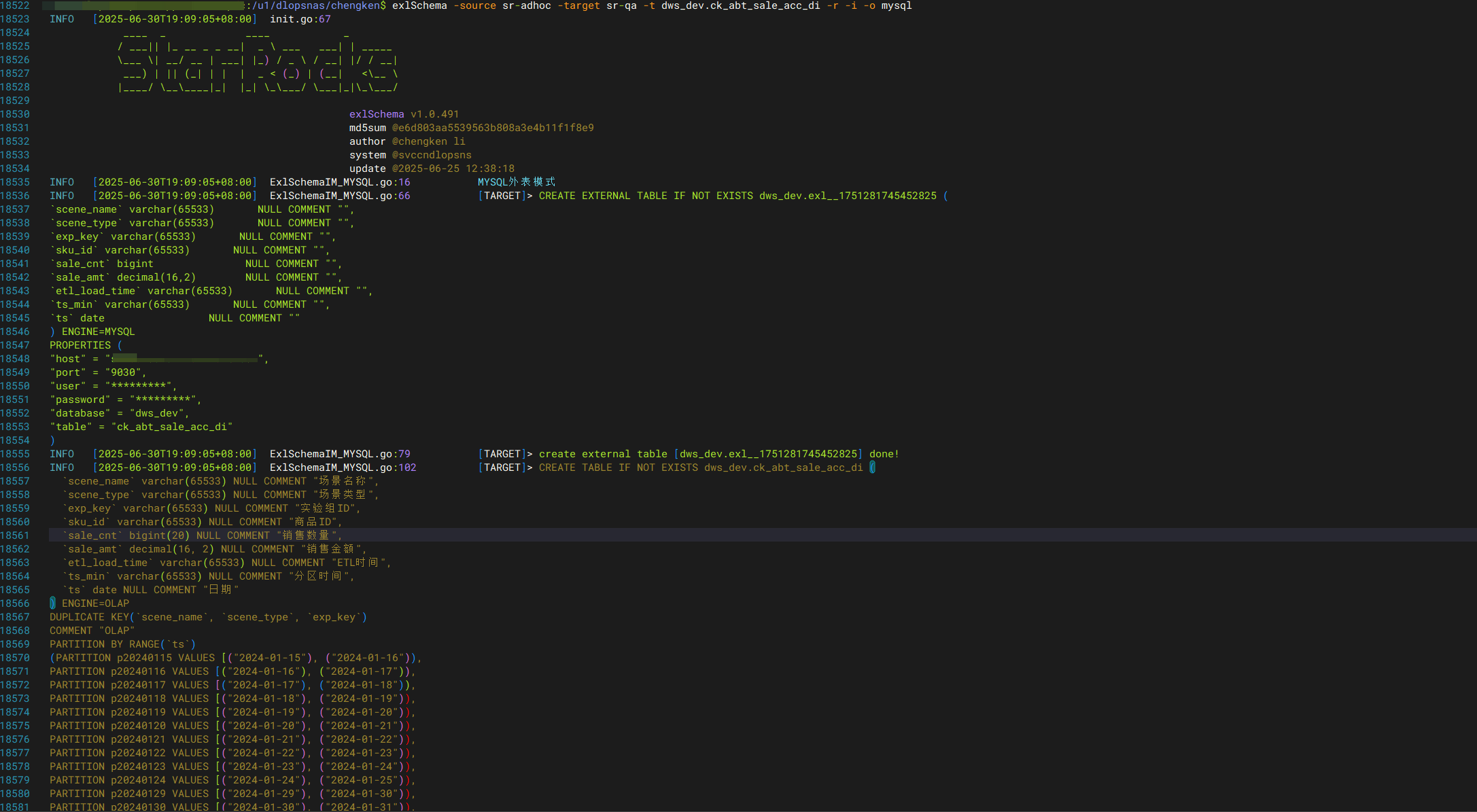
全量同步(表结构+数据)- MYSQL外表方式
exlSchema -source <源集群简称> -target <目标集群简称> -t <库表名 /支持同步多个库表,逗号分隔/> -r -i -o mysql
- 自动创建外表
- 自动创建内表
- 自动insert写入。
- 走9030端口

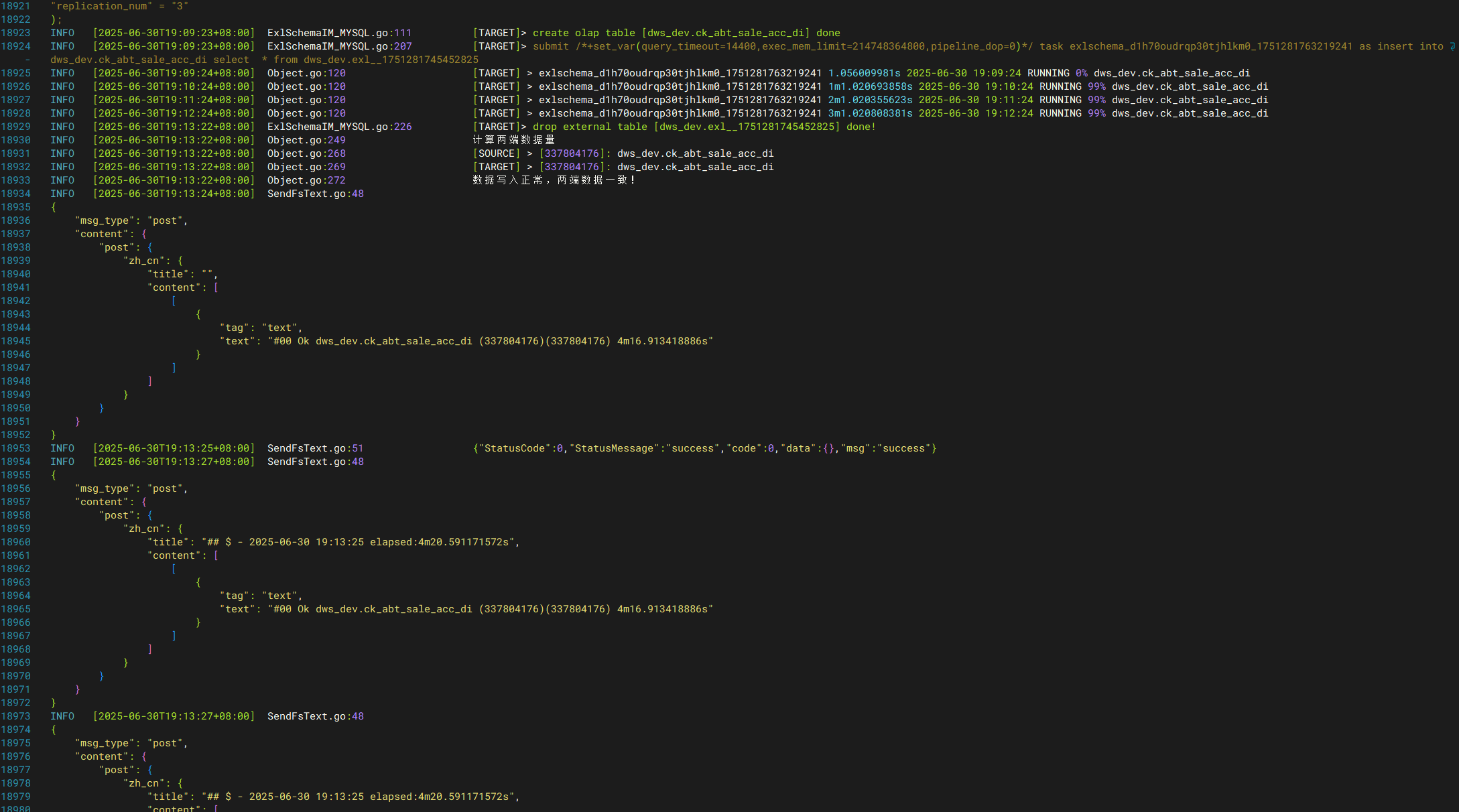
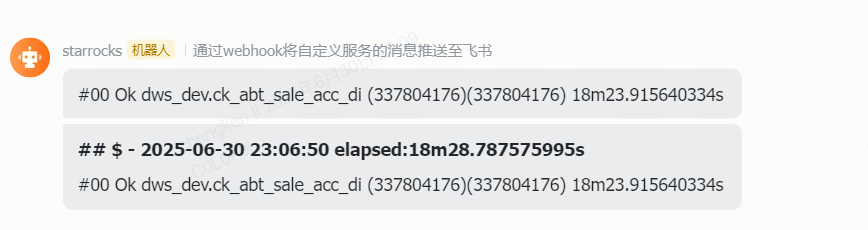
迁移完成,推送飞书。

3个亿,4分钟。
多表同步-t <t1,t2,t3…>

迁移完成,推送飞书。
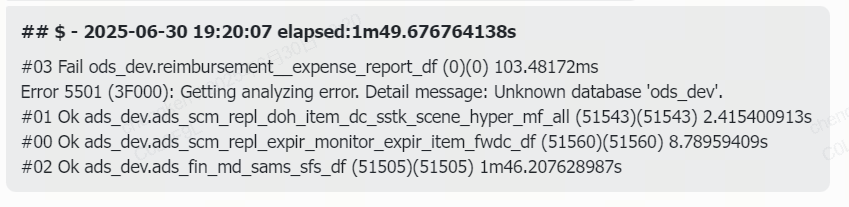
这里出现的信息有:总耗时,task耗时,同步状态,表名,源端数据量,目标数据量。
全量同步(表结构+数据)- STARROCKS外表方式
exlSchema -source <源集群简称> -target <目标集群简称> -t <库表名 /支持同步多个库表,逗号分隔/> -r -i -o starrocks
- 自动创建外表
- 自动创建内表
- 自动insert写入。
- 走9020端口
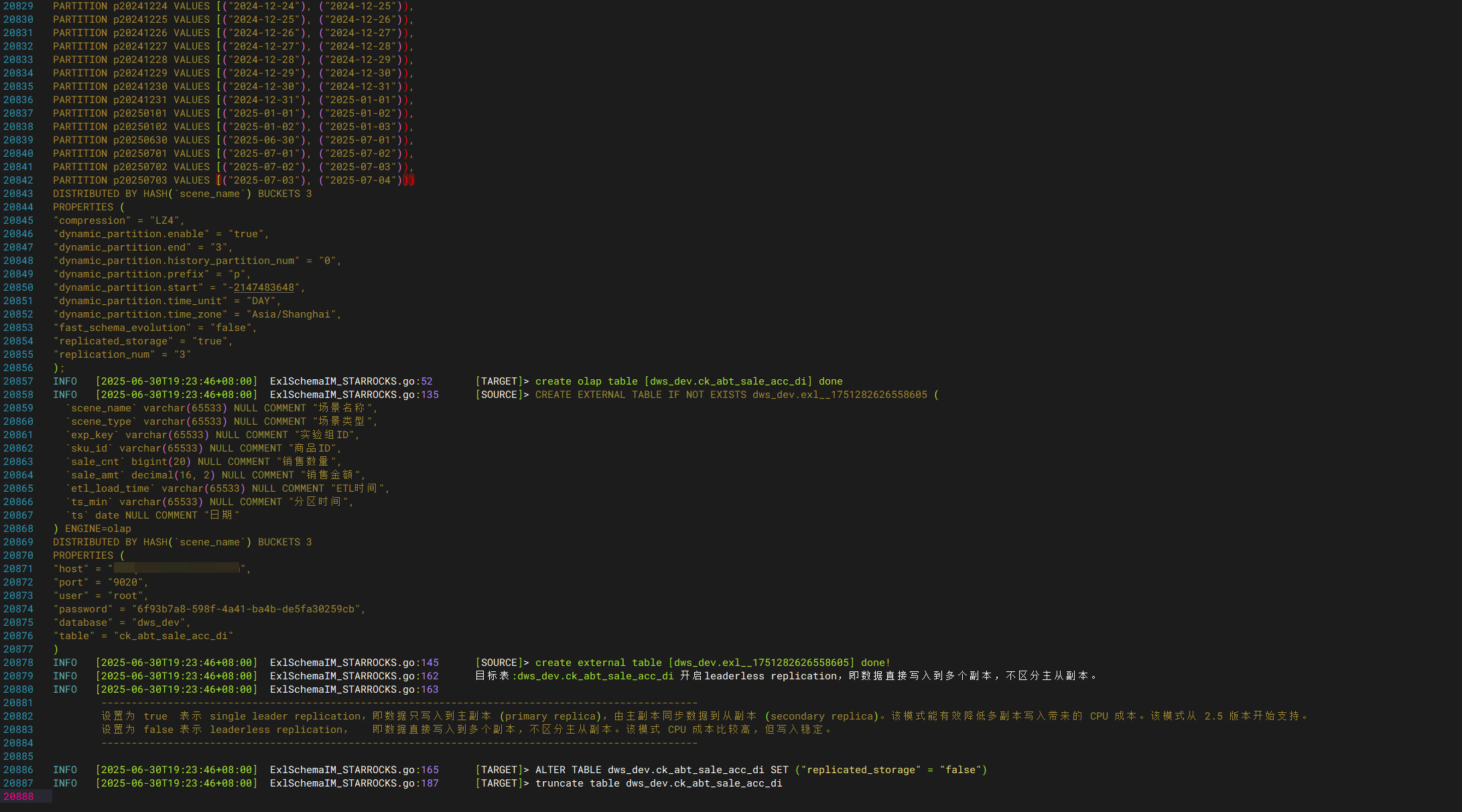
starrocks olap外表传输有个缺点就是,需要等元数据缓冲完成后,才支持写入,否则failed。
全量同步(表结构+数据)- 官方元数据模式
exlSchema -source <源集群简称> -target <目标集群简称> -t <库表名 /支持同步多个库表,逗号分隔/> -r -i -o meta
- 自动匹配配置文件
- 自动默认一次性写入
- 走9030、9020端口

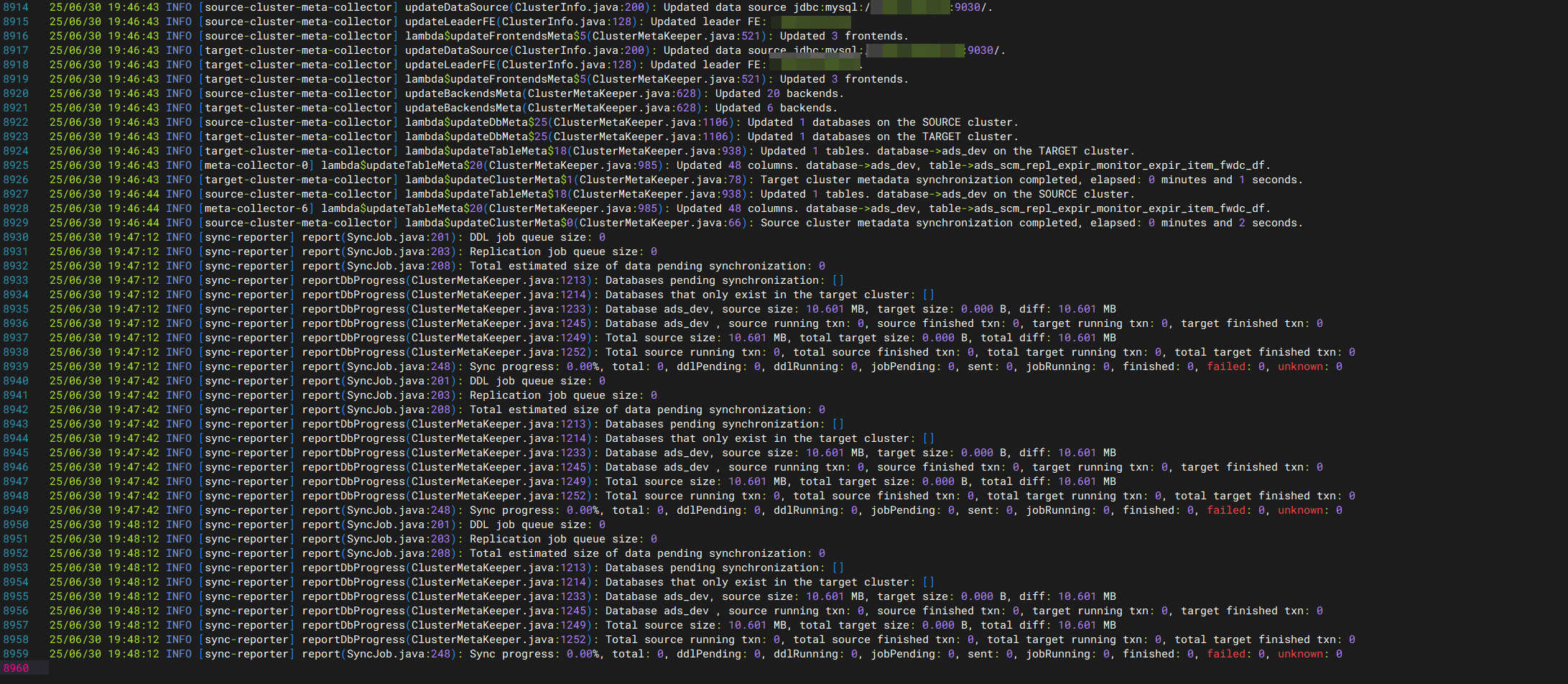
等程序走完就好
全量同步(表结构)- 库级别结构模式
exlSchema -source <源集群简称> -target <目标集群简称> -t <库名 /支持同步多个库,逗号分隔/> -r -i -o ghost -level db
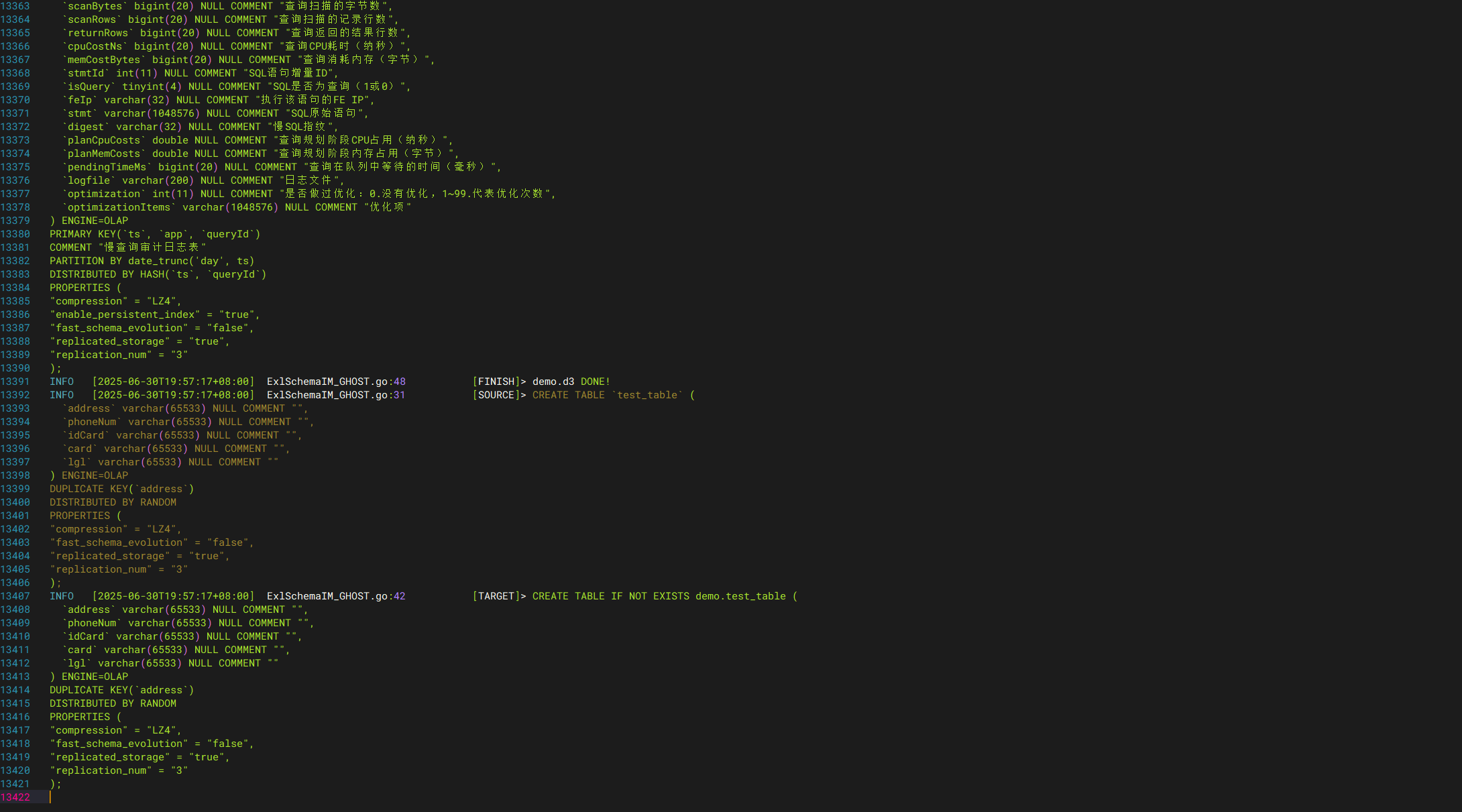
由于这个模式只是同步表结构,速度很快,也可以使用-thread xx指定线程数进行加快同步
同理,每个模式运行结束后,都会收集同步状态、结果发送到飞书

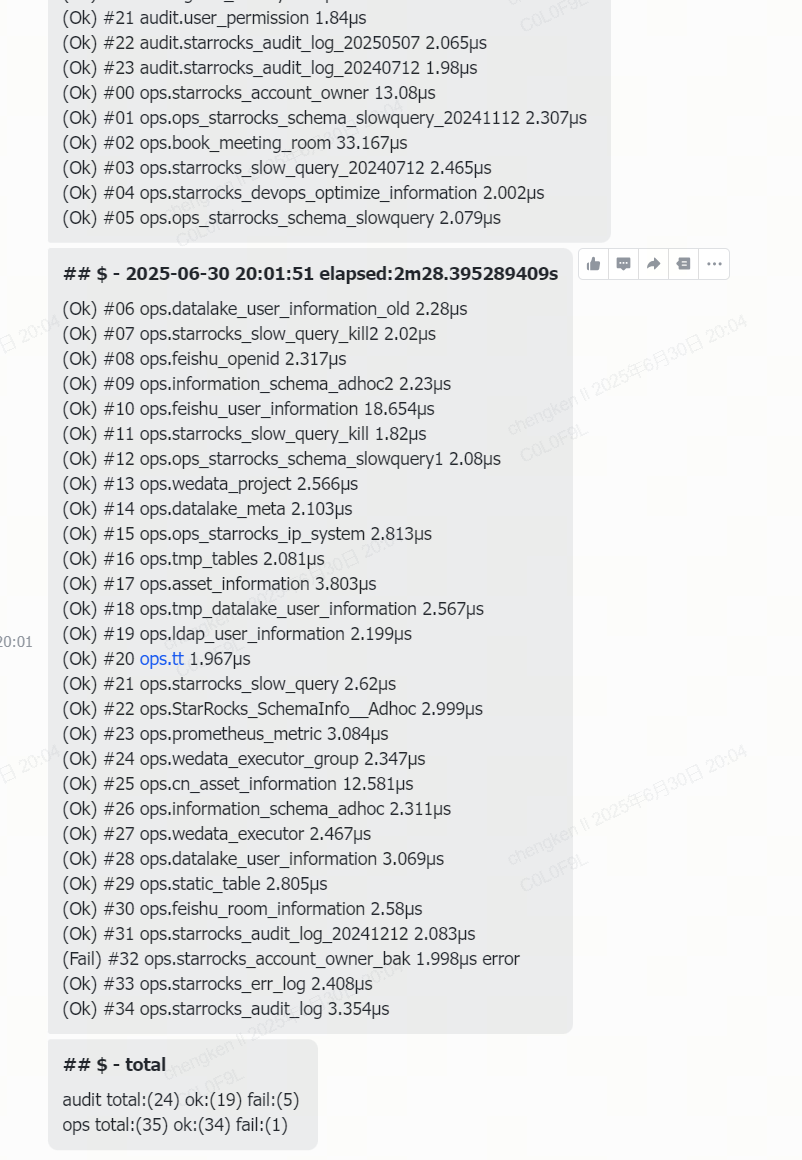
再登录目标集群,表结构已经过来

全量/分区同步(表结构+数据)- Jdbc Catalog 源、目标容量级别,容量批次导入v1模式
全量一次性模式
exlSchema -source <源集群简称> -target <目标集群简称> -t <库名 /支持同步多个库,逗号分隔/> -r -i -o v1 -a <jdbc catalog名称>
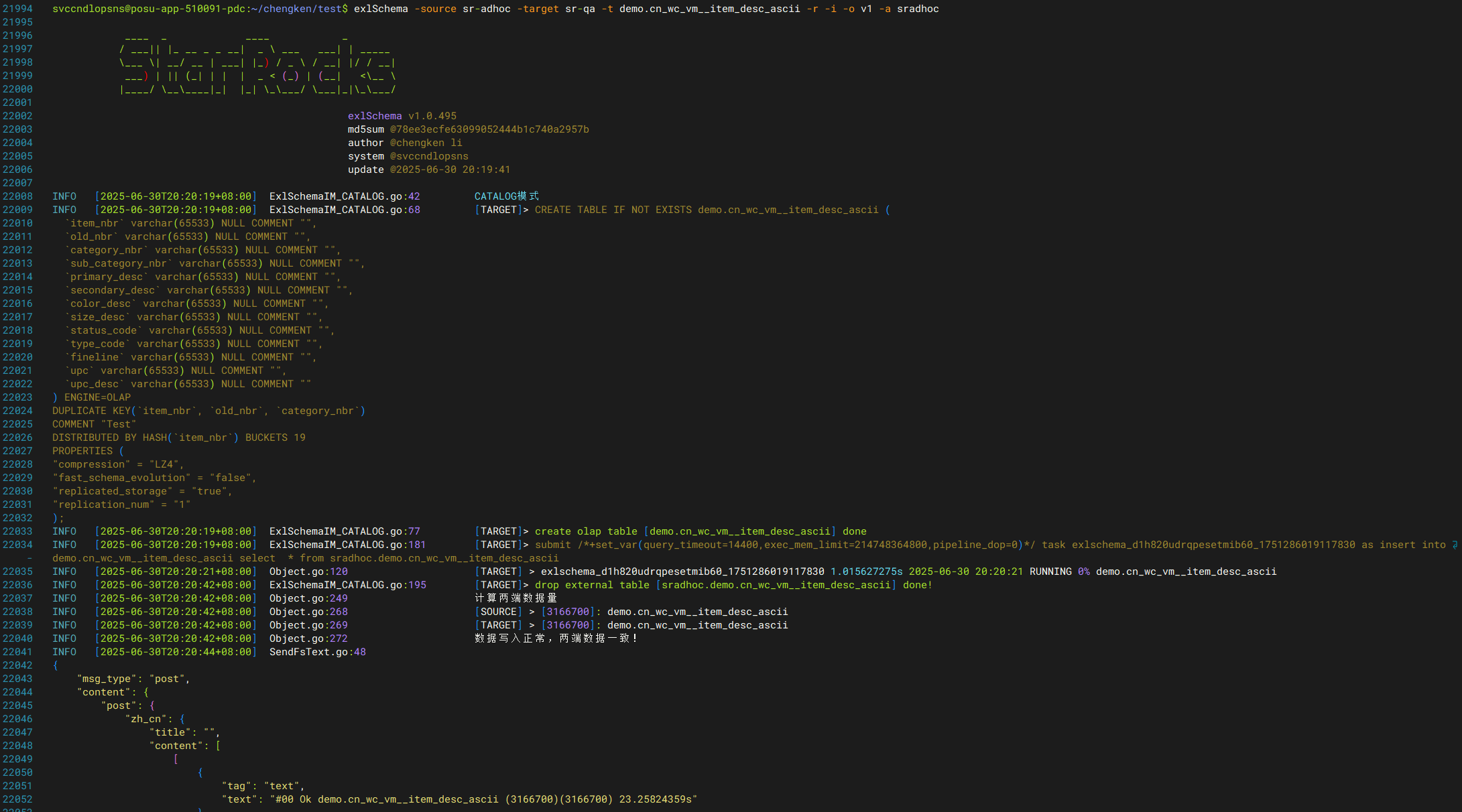
单例批次同步模式
-batch


这种特点是,当带宽能力不足,且担心打满带宽时,可以自动分配区间逻辑表达式进行task级别拆分同步,同时可以支持使用-speed参数(默认1GB)进行分配,比如4GB的表,当不指定时,默认1,那么就会生成4个逻辑表达式,如果使用-speed 2,那么就会生成2个逻辑表达式。
每个task完成后自动汇报耗时。

当然,也可以使用-batchcheck 参数预览每个单例切割出来的逻辑表达式
例如表大小4GB,-peed=1时

例如表大小4GB,-speed=4时

把所有的task都收拢,然后一起上报给job级别,最后发出finished通知

发出Fail通知,原因是目标表中已经存在数据了,但是没有进行truncate直接写入,导致数据翻倍,可使用-truncate进行生成写入的前置清空
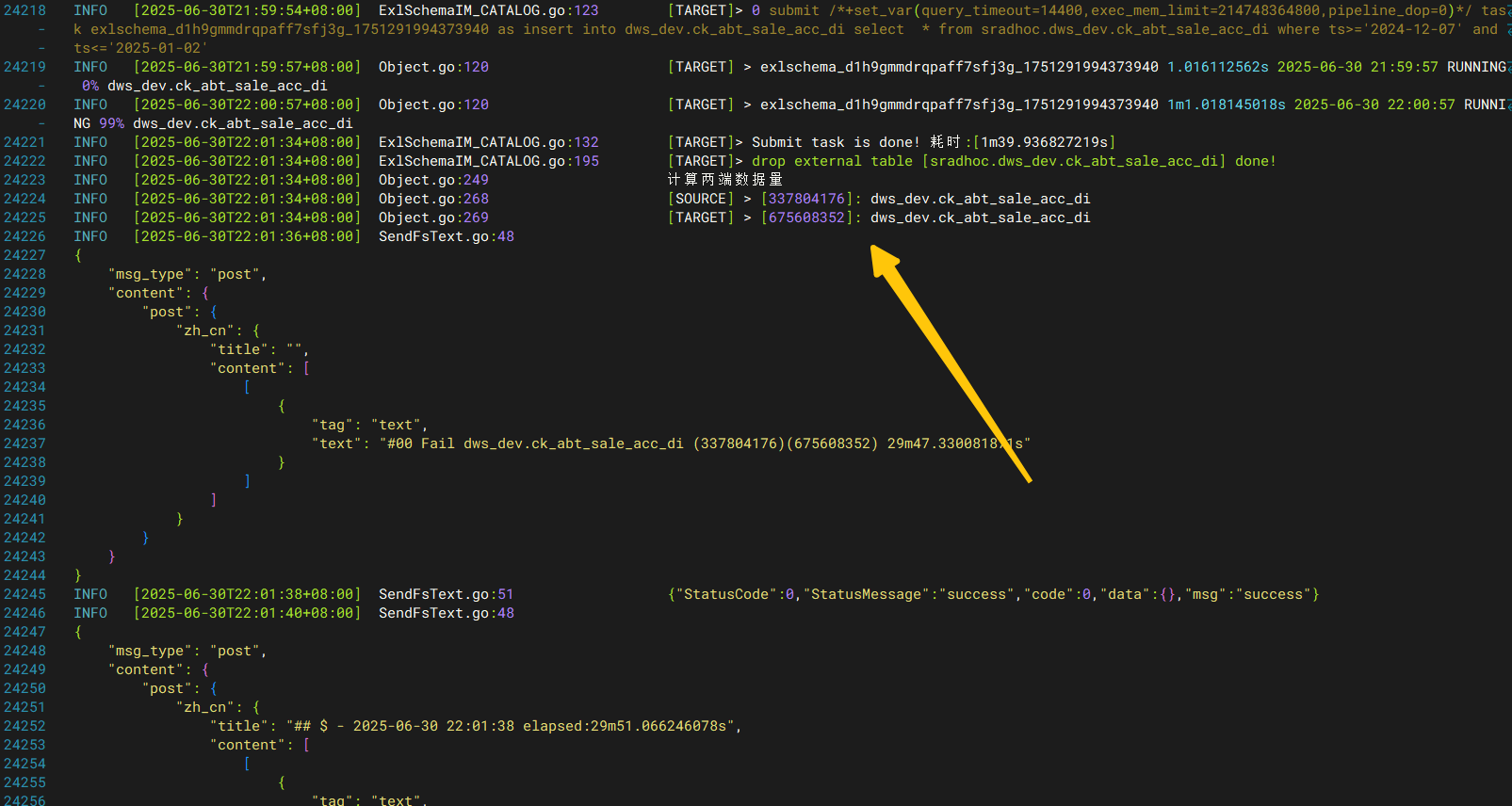
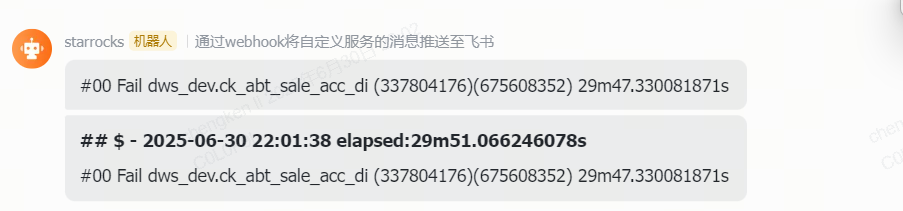
当然,类似这种数据翻倍的清空,就是两端数据不一致,稽核失败。也可以选择使用补数模式
-complement 补数模式,自动稽核两端数据,保证数据量高度一致

如遇到解析异常事件,会弹出最佳同步模式推荐
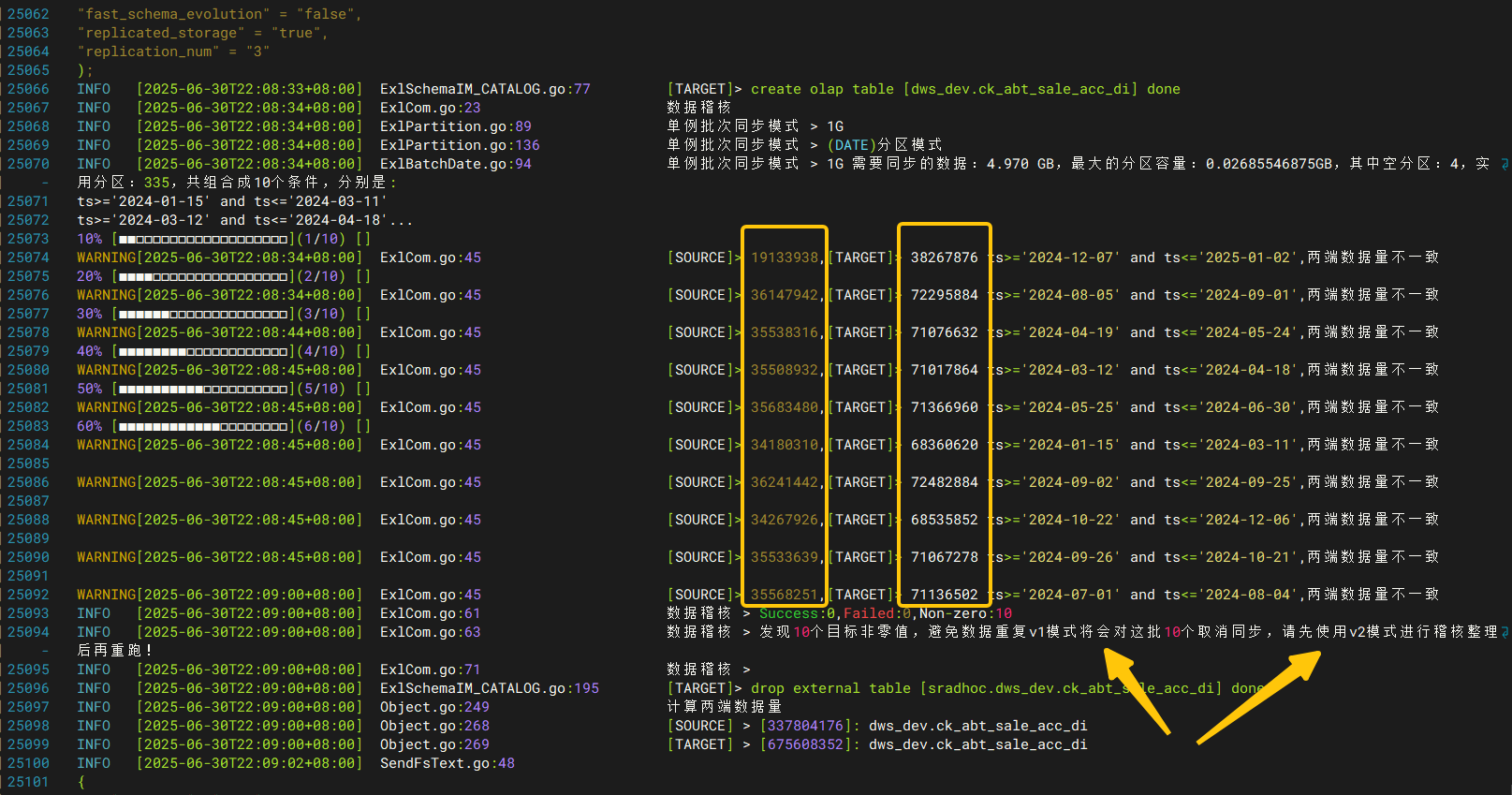
使用v2模式进行稽核
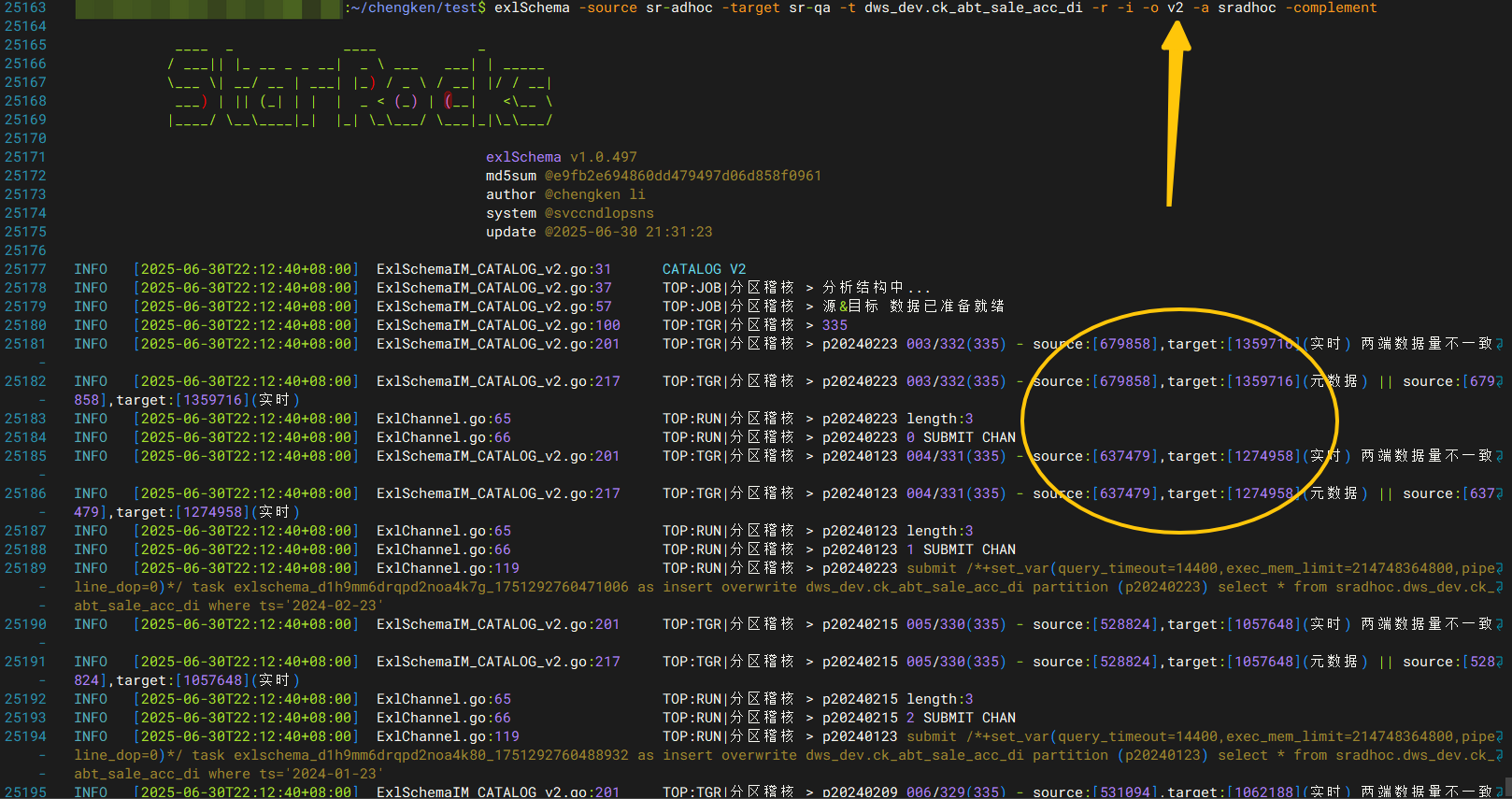
直接识别每个分区,两端数据量,出现差异直接分区级别overwrite覆写,覆写完成后进行二次稽核并汇报
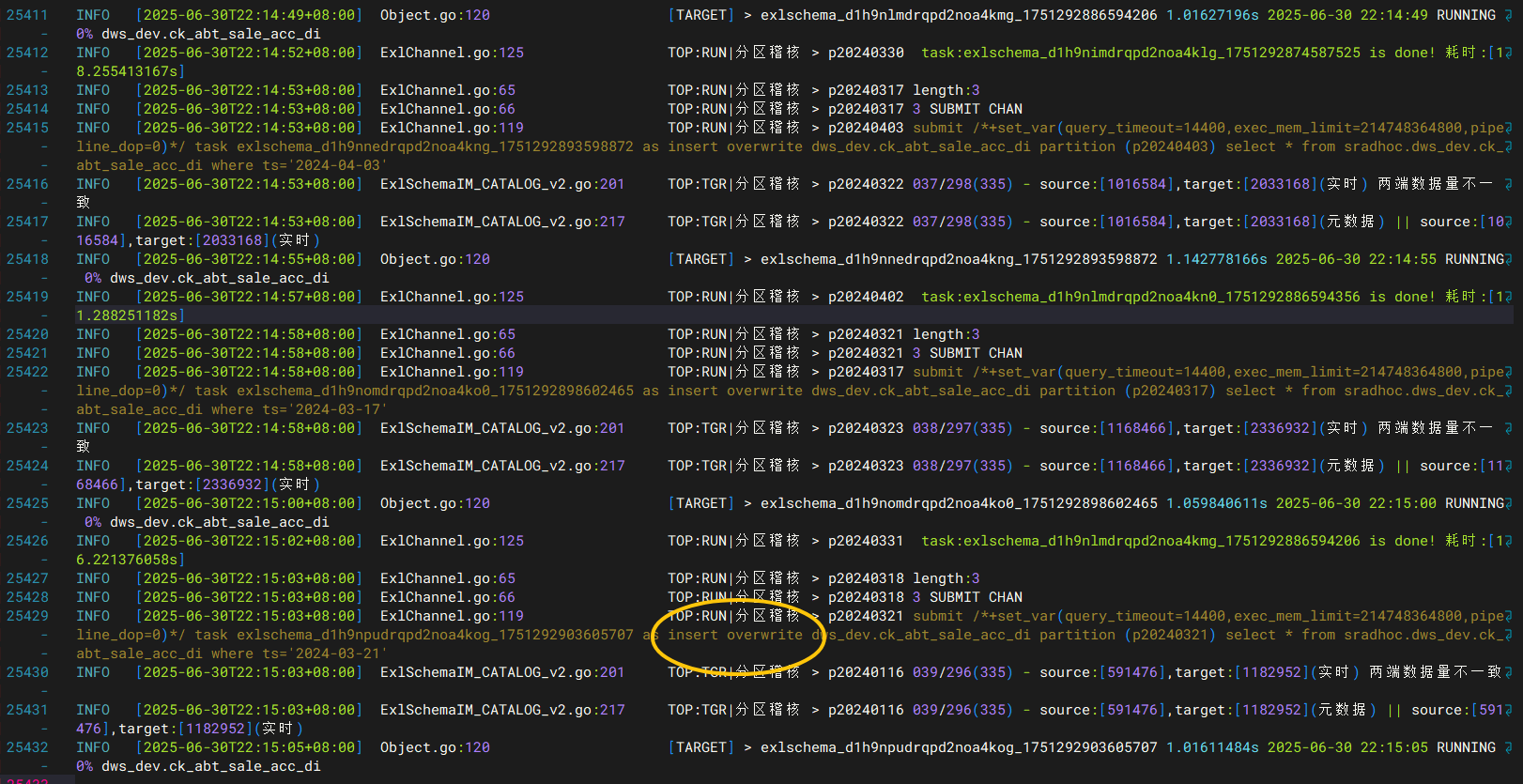
v2这种方式由于是单个分区写,线程池默认是3,相对比确实会慢一些,但想单分区多并发写入也是可以的,-thread 10(默认3),代表支持同时10个task在running
全量/分区同步(表结构+数据)- Jdbc Catalog 源、目标分区稽核,单分区覆写v2模式
exlSchema -source <源集群简称> -target <目标集群简称> -t <库名 /支持同步多个库,逗号分隔/> -r -i -o v2 -a <jdbc catalog名称> -complement

上面描述了,v2模式单分区覆写,优点是稳定,缺点也是很明显的,为什么会有v2的出现,假如一个表,单分区是10GB+,整表是TB级别的,这个时候为了尽量降低带宽的影响时,v2模式就能发挥稽核效率了。 但它确实也是龟速爬行,于是v3模式出现了。
全量/分区同步(表结构+数据)- Jdbc Catalog 源、目标分区稽核,多攒批覆写v3模式
攒批写入,-o v3
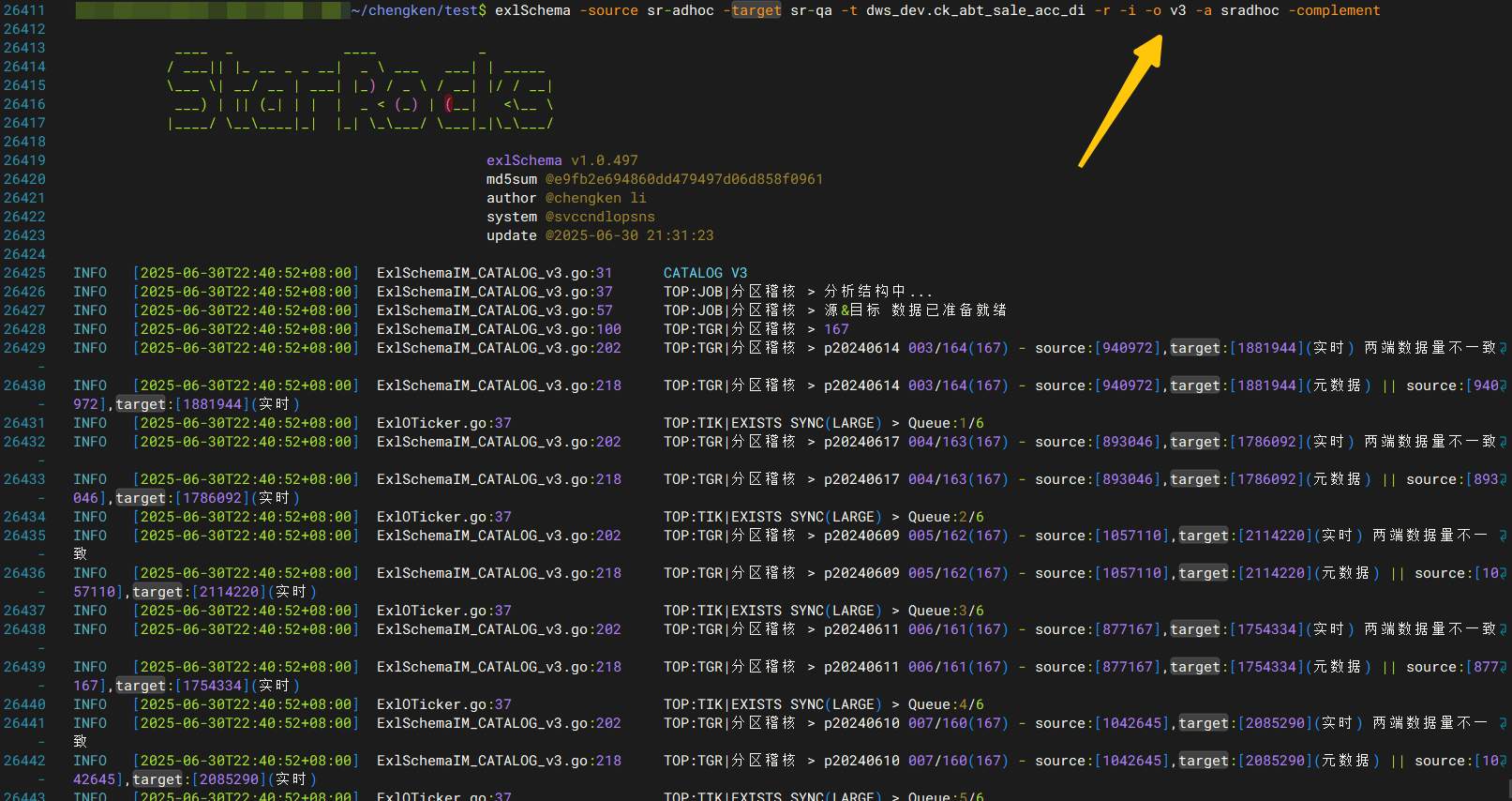

当指定并发数-thread 10时
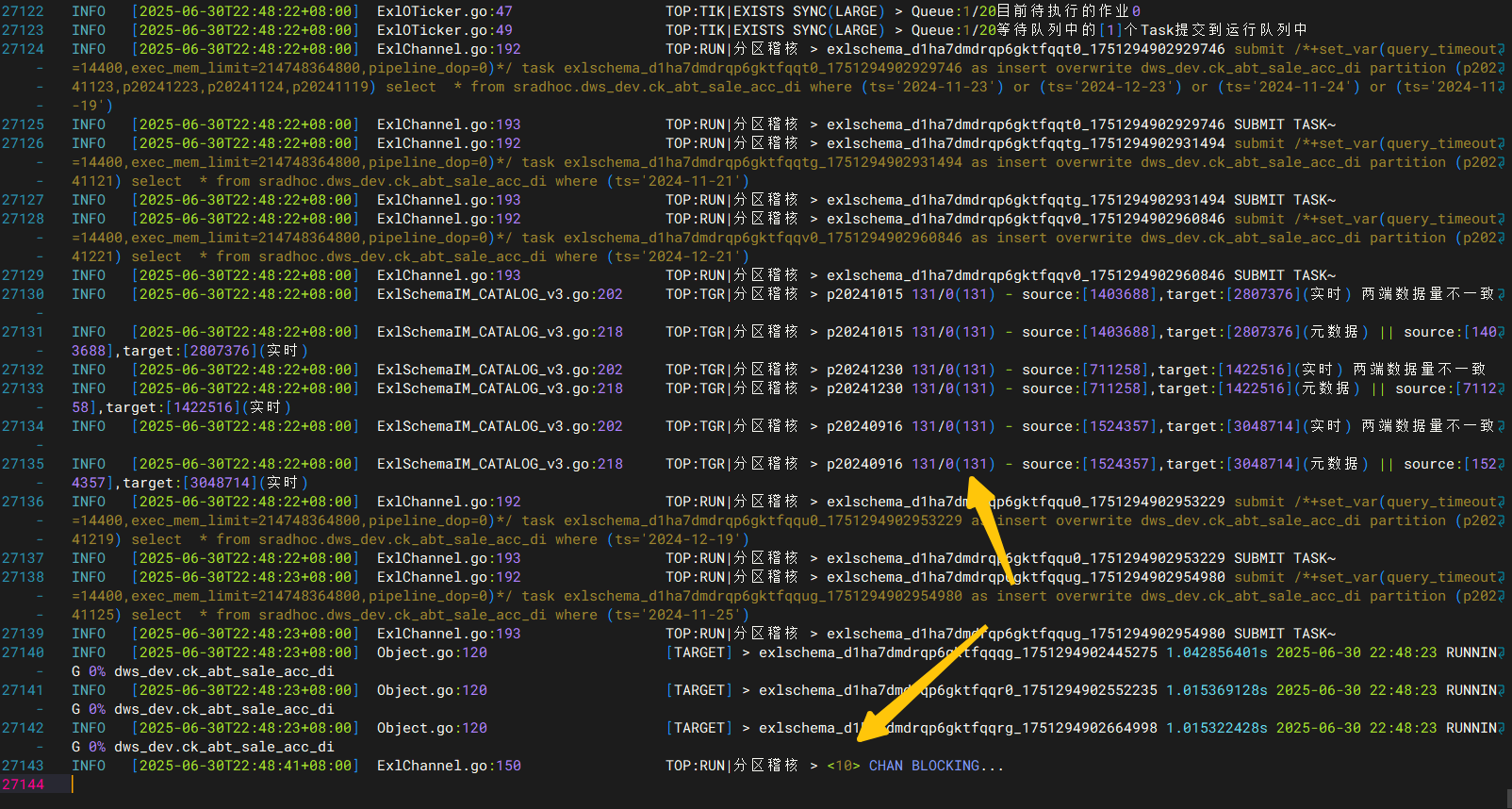
此时可以预览 select * from information_schema.task_runs where state=‘RUNNING’
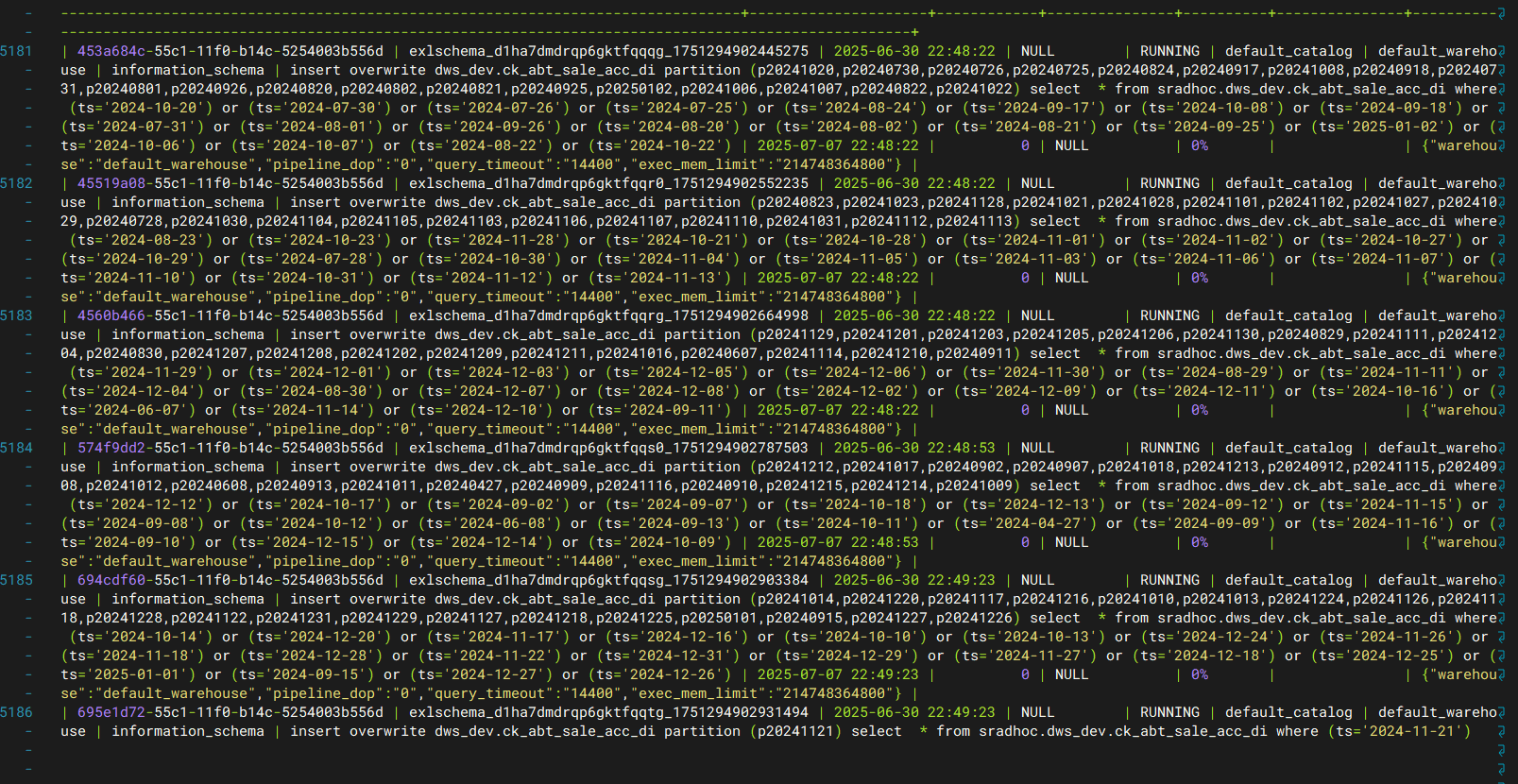
task完成,汇报
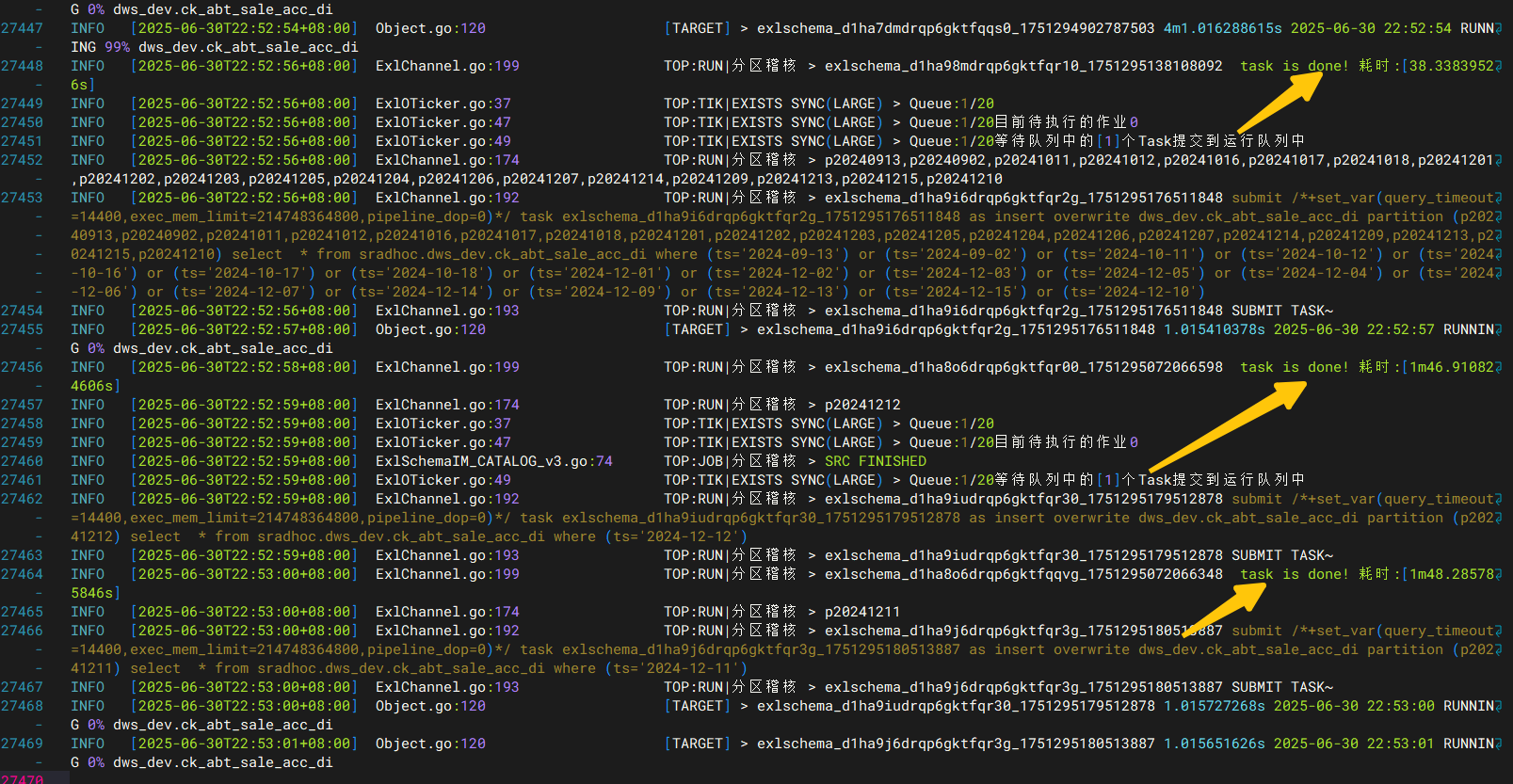
当线程池逐渐减少时,代表还剩下多少个task在running
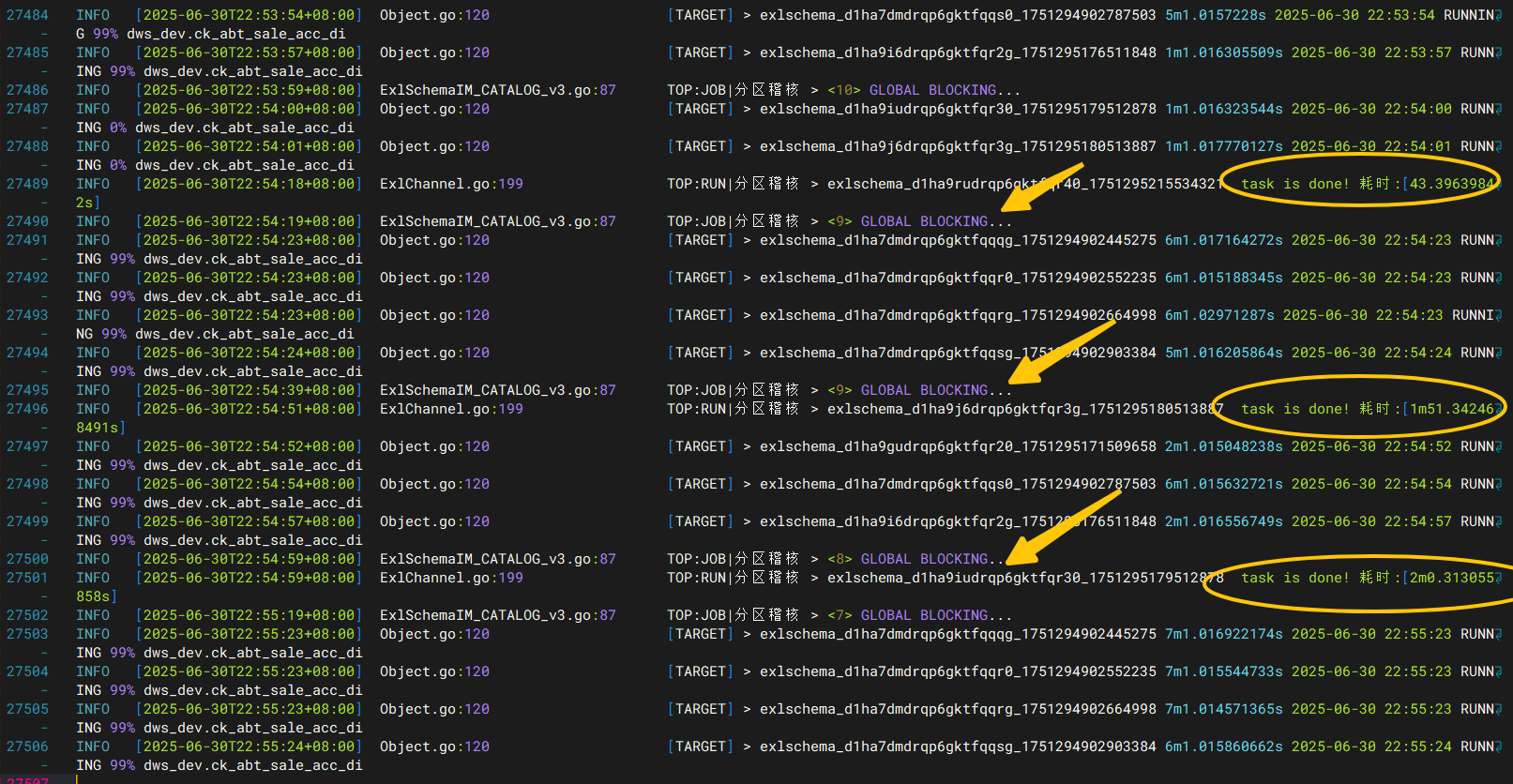
结束

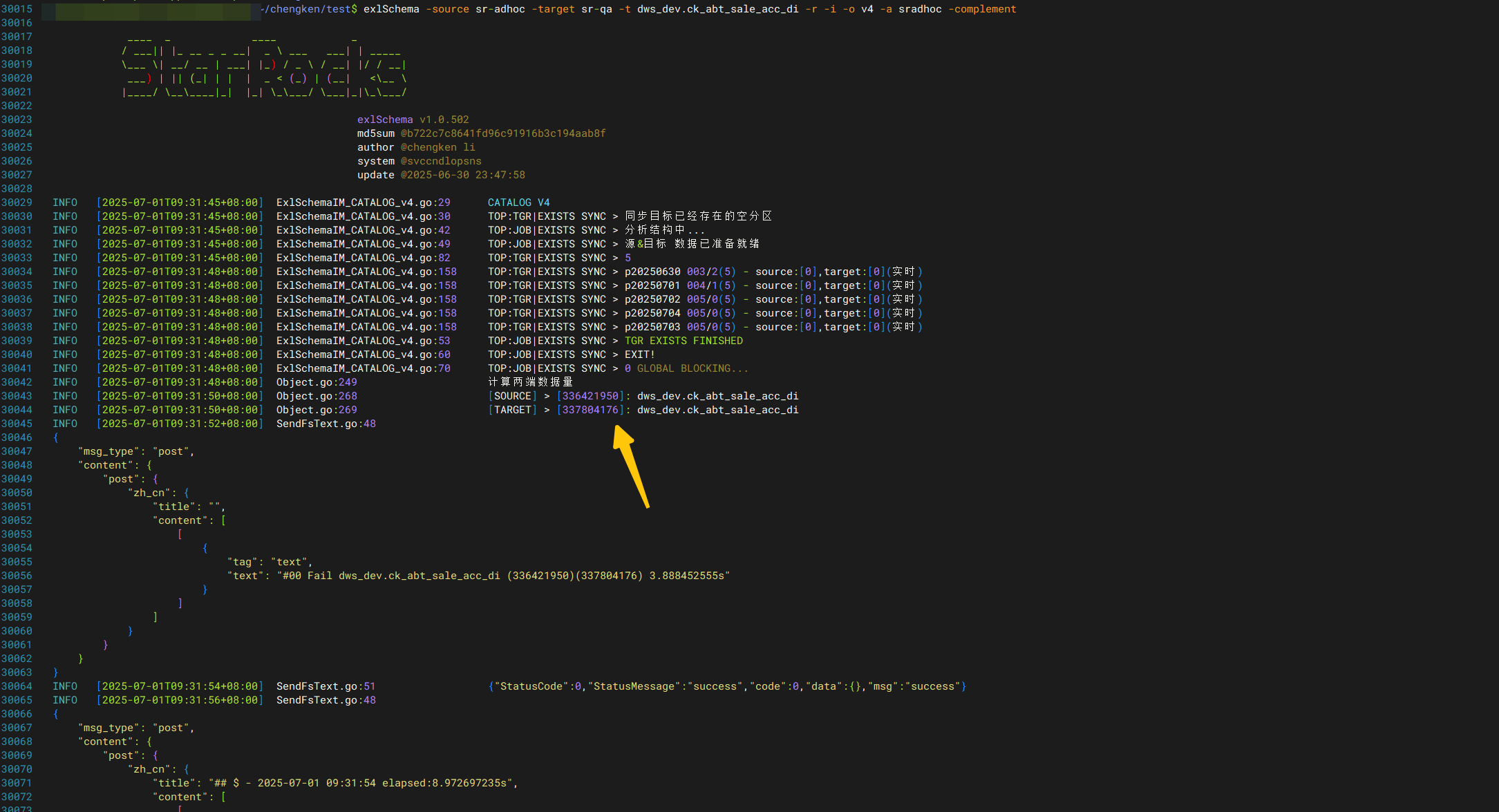
全量/分区同步(表结构+数据)- Jdbc Catalog 仅对目标分区稽核,单分区覆写v4模式
-o v4
全量/分区同步(表结构+数据)- Jdbc Catalog 仅对目标分区稽核,多攒批覆写v5模式
-o v5
v4,v5模式的使用场景:当目标表的数据量比源端多时,v4/v5不进行清理源端分区,不强调两端一致。只将源端存在,目标不存在的分区进行加载写入。如源端不存在,但目标存在的数据、分区,只对目标表进行处理。
无论是v1-v5模式,有的分区源端存在,但目标不存在的情况下,使用-add参数在数据同步时会自动生成添加分区语句。
v1-v5模式依赖Jdbc Catalog,如果启动时没有指定-a 那么将触发提示词

如:
源端表属性

目标端表属性

目标分区数大于源端,这个时候触发v4,v5模式,将以目标分区、数据量为准。假如出现源与目标分区级别数据量不一致,将触发进行二次稽核同步模式
配置说明
配置文件.exlSchema.yaml,同样需要维护starroks登录信息元数据表。
- 支持集成官方的starrocks-cluster-sync,如用到官方scs,则需要在配置中填写目录
- 支持自定义飞书群组机器人key
- 支持自定义飞书代理地址
- -h 查看程序帮助,有兴趣使用的可自行探索