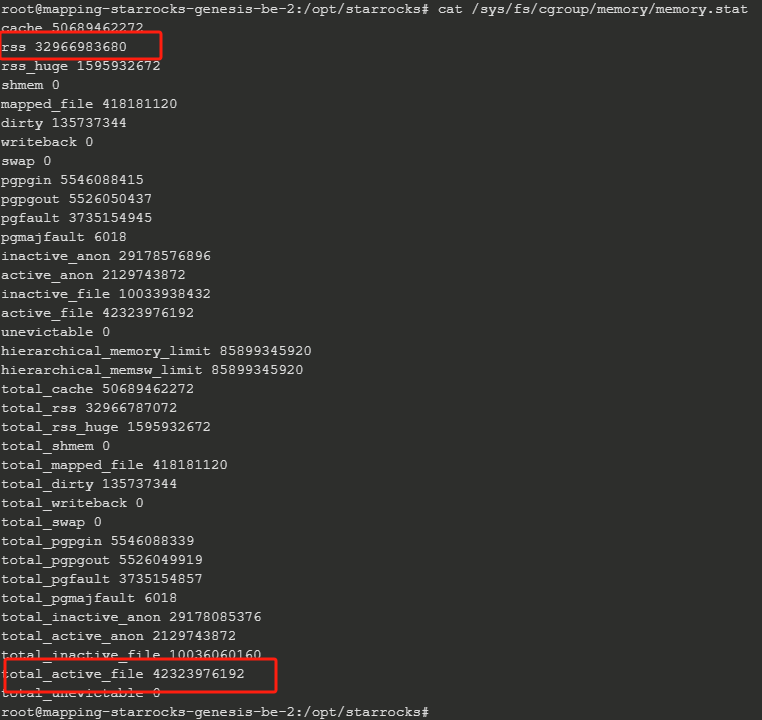
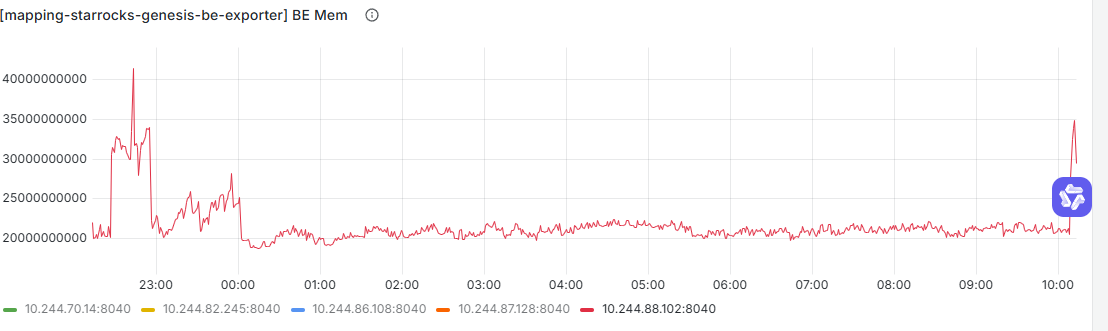
【详述】我们的starrocks集群部署在k8s上,BE单节点分配了80G内存,BE进程本身占用内存一般在30G左右,k8s监控pod内存会周期性的突破到70+G,查了一下多的40G内存基本都是page cache(total_ative_file)占用,想问问同样在k8s上部署的同学,你们有没有碰到过这个问题,又是如何解决的?
【背景】无
【业务影响】暂无,但是会频繁触发内存告警
【是否存算分离】否
【StarRocks版本】3.4.3-a01aa59
【集群规模】3FE + 3BE
【机器信息】FE 8C16G,BE 16C80G
【附件】
k8s内存监控

be进程内存监控
内存详情