
在使用spark Connector的查询方式时,官方提供的方式是:
val df = spark.read.format(“starrocks”)
.option(“starrocks.table.identifier”, s"test.mytable")
.option(“starrocks.fenodes”, s"<fe_host>:<fe_http_port>")
.option(“user”, s"root")
.option(“password”, s"")
.option(“starrocks.filter.query”, “k=1”)
.load()
有几个问题点:
1、“starrocks.fenodes”, s"<fe_host>:<fe_http_port>"这种使用8030端口进行数据查询和获取的时候的流程是怎样的?
是这样嘛:通过8030端口查询时,服务器会返回数据所在backend的元数据信息到客户端,然后客户端通过这些backend的信息,再去backend节点进行查询?
2、如果某个backend节点挂了,再使用8030端口查询的时候,会返回这个挂掉的backend节点信息吗?
因为我这边在实际的使用过程中出现了这样一个问题: 我有三台backend节点,但是今天挂了一台,在使用http8030这种端口查询时,还是会访问挂掉的这条backend节点
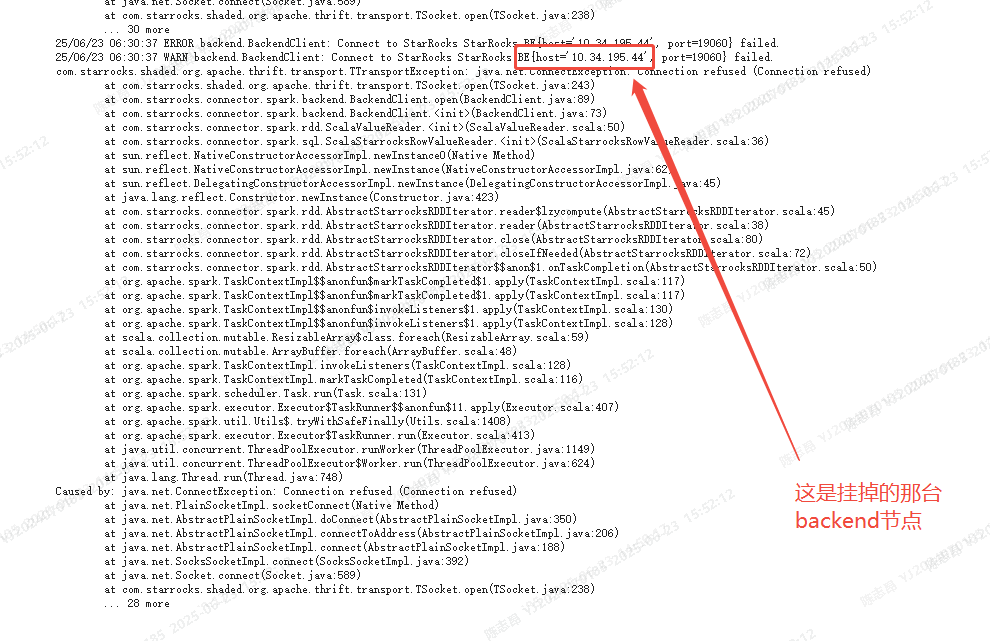
以上,望开发人员给予解释。