为了更快的定位您的问题,请提供以下信息,谢谢
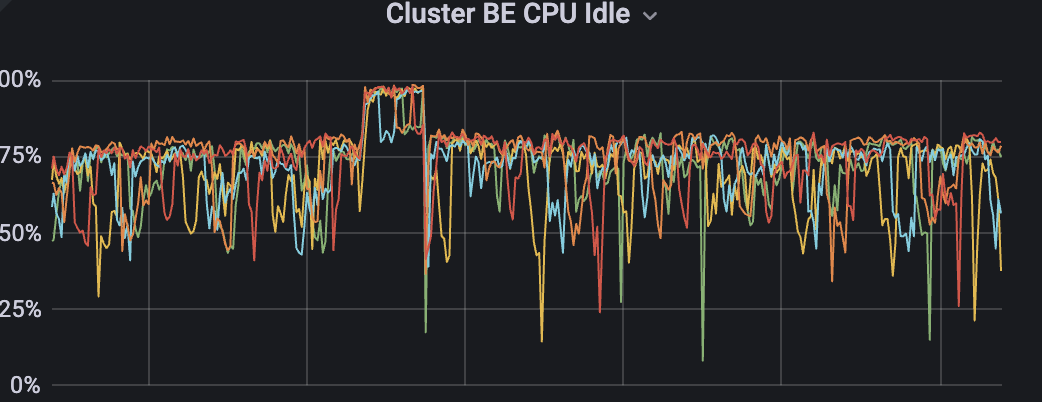
【详述】随着数据量激增,数据写入事务超时,查询报错 OlapScanNode fail scan info is invalid,表不可用
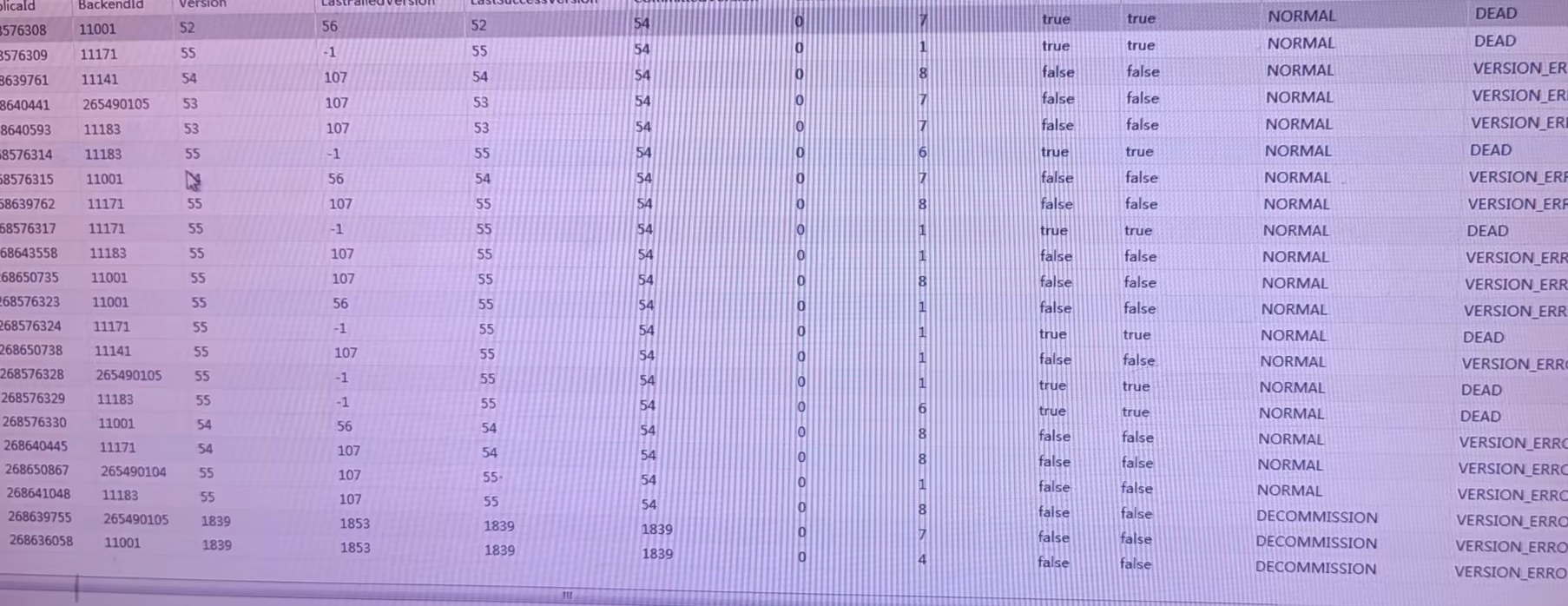
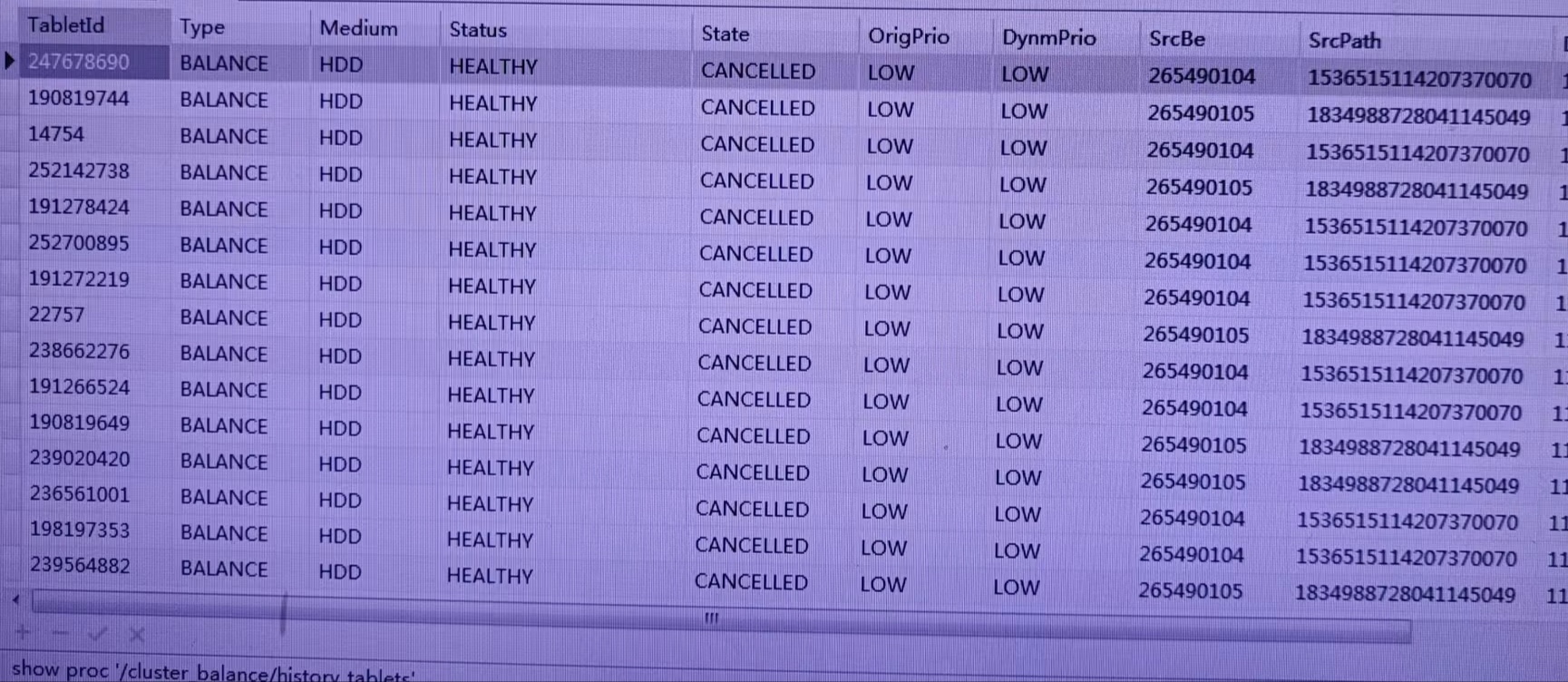
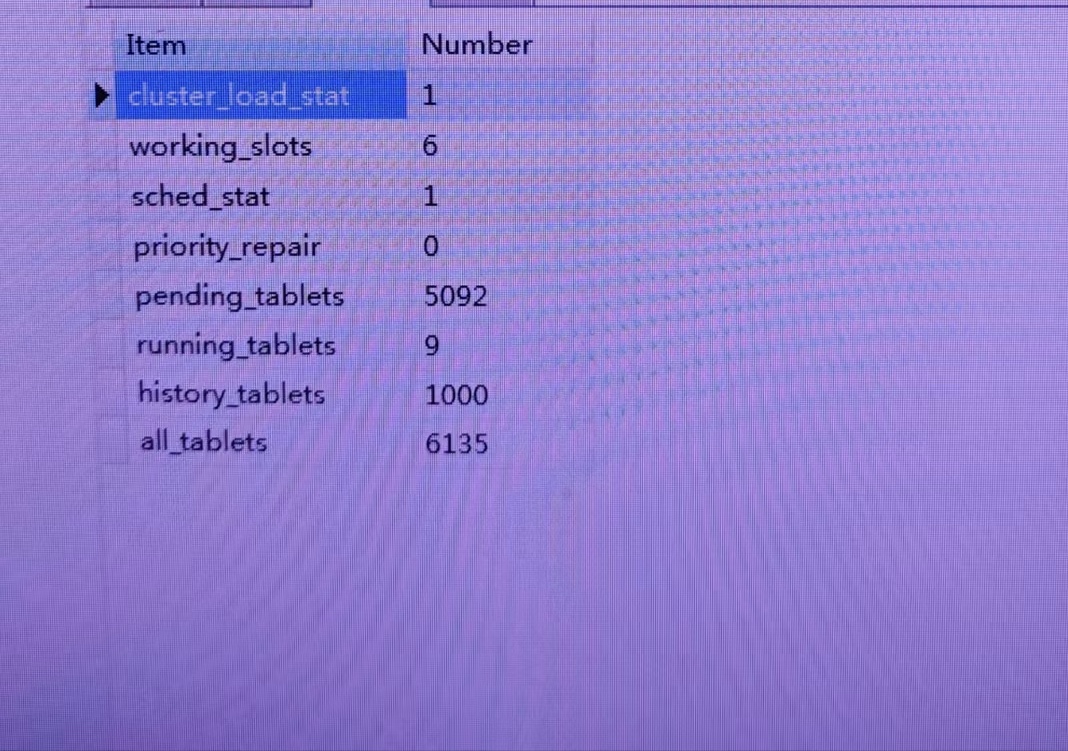
SHOW PROC '/statistic/<DbId>' 可以看到不健康的 tablet 数量为 145,然后停掉所有写入后,执行手动恢复。
ADMIN REPAIR TABLE table_name;
执行后等了几个小时之后发现不健康的 Table 数量降到了90,等到了昨天晚上降到了 60,今天早晨发现是 59,基本上恢复不动,Table 大部分状态都是 VERSION_ERROR。
所以想问下这种情况怎么手动恢复,或者能否删除这些 tablet 先恢复数据表可用? 谢谢
【背景】数据量比往常大
【业务影响】无法写入和查询
【是否存算分离】否
【StarRocks版本】3.2.8
【集群规模】3fe(1 follower+2observer)+6be(follower fe 独享,observer与be混部)
【机器信息】CPU 鲲鹏920 ARM 96核/内存 256G/网卡万兆
【联系方式】
【附件】