在日常运维中,我们常常面临突发问题,只能疲于“救火”。本文将从 资源使用率、服务可用性、业务持续性 等多个维度出发,介绍如何构建一套有效的监控与告警体系,实现从被动响应到主动干预,让问题止于萌芽阶段。
本文重点聚焦于 监控与告警的实战经验和最佳实践 ,不对监控系统的搭建流程进行详细展开。如需了解具体部署方式,可参考官方文档:https://docs.starrocks.io/zh/docs/administration/management/monitoring/Monitor_and_Alert/
我们还提供了 SRCA 视频课程,详细讲解如何搭建 StarRocks 监控系统,欢迎查阅学习。https://www.mirrorship.cn/zh-CN/training/course/SRCA
积分商城上线后,不少小伙伴反馈希望有更多样、轻松的积分获取方式。为此,我们特别准备了“轻松赚积分”活动,让你更简单地积累积分,快来看看吧~活动详情见文末
直播回放链接:
关键指标
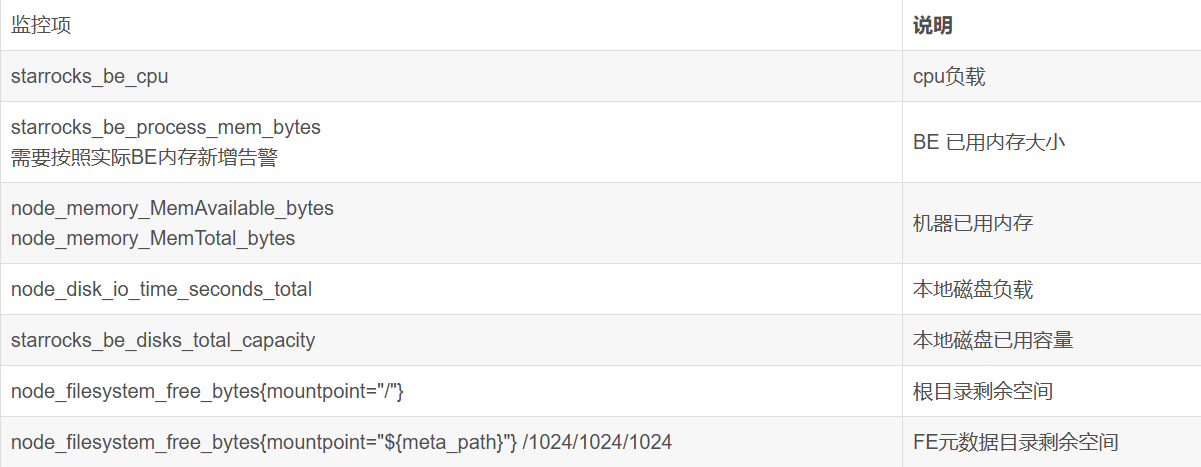
机器过载监控项
监控机器的过载情况,以更早期地帮助发现可能的问题。
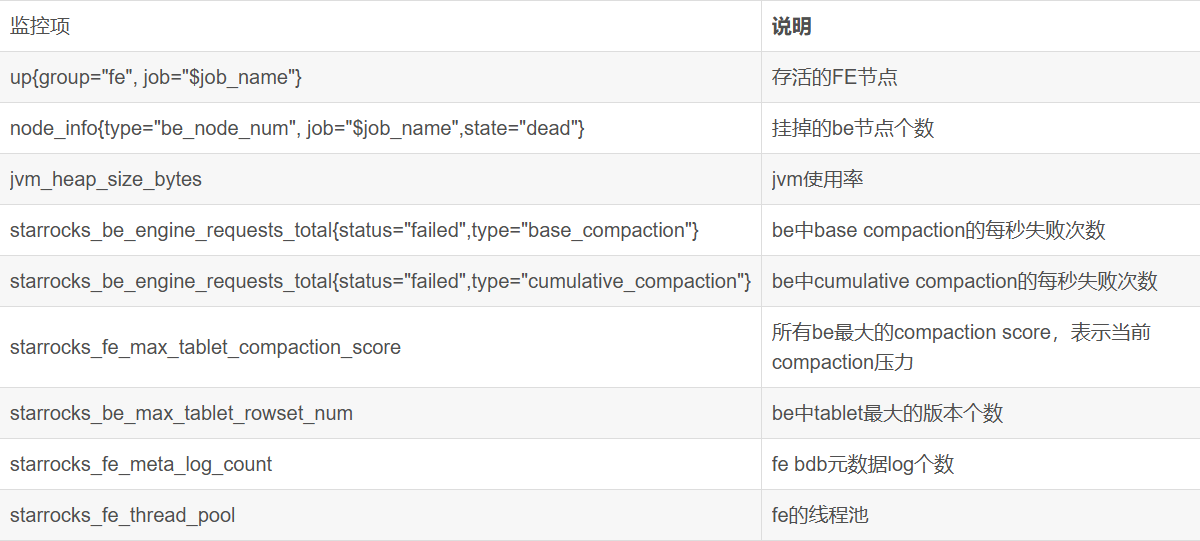
集群服务异常监控
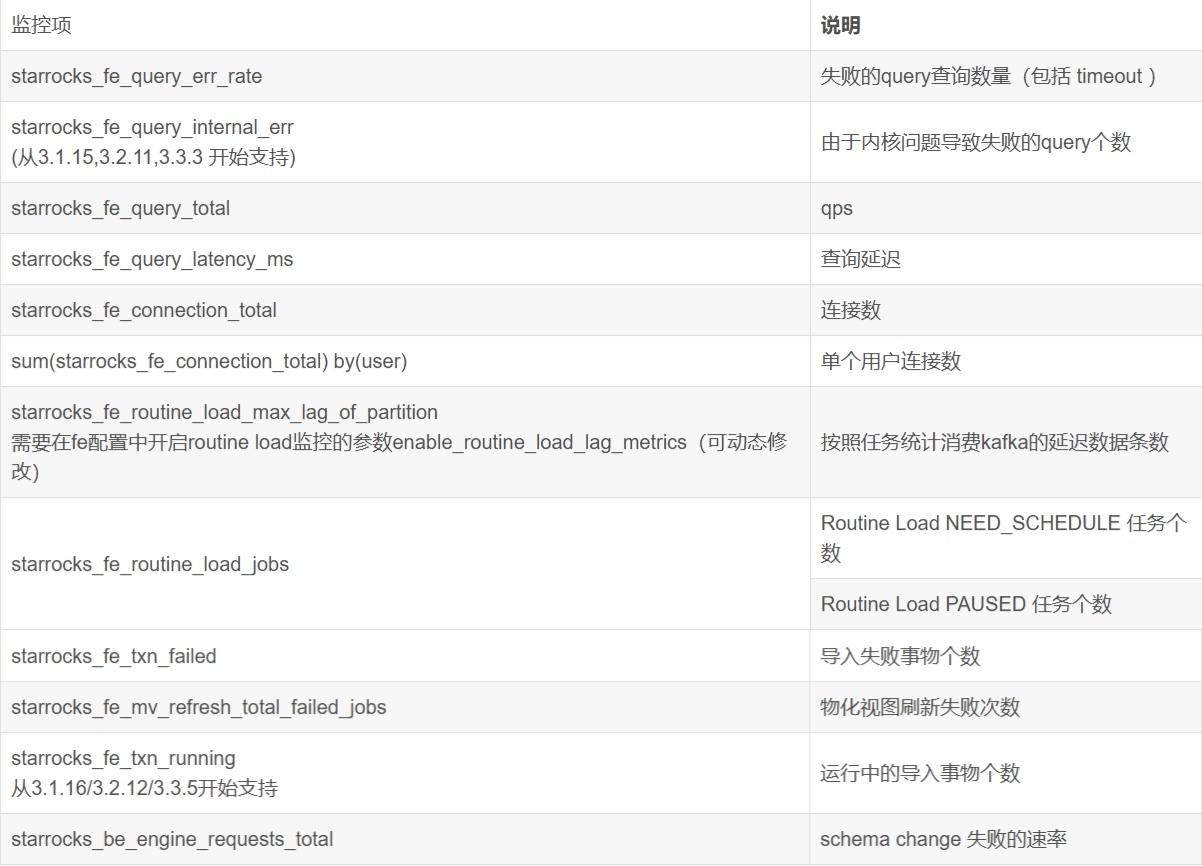
业务可用性监控
监控告警处理:
1. 机器过载监控
1.1 CPU负载高:
PromSQL
(1-(sum(rate(starrocks_be_cpu{mode="idle", job="$cluster_name",instance=~".*"}[5m])) by (job, instance)) / (sum(rate(starrocks_be_cpu{job="$cluster_name",host=~".*"}[5m])) by (job, instance))) * 100
报警描述
当 BE CPU Utilization 超过 90% 时发送报警。
处理方法:
1.1.1 排查是否有大查询
mysql> show proc '/current_queries';
+---------------------+-----+--------------------------------------+--------------+----------+--------------------+------------+------------------+-------------+---------------+-------------+------------+-------------------+---------------+---------------+
| StartTime | feIp| QueryId | ConnectionId | Database | User | ScanBytes | ScanRows | MemoryUsage | DiskSpillSize | CPUTime | ExecTime | Warehouse | CustomQueryId | ResourceGroup |
+---------------------+---------------------+--------------------------------------+--------------+----------+--------------------+------------+------------------+-------------+---------------+-------------+------------+-------------------+---------------+---------------+
| 2025-04-09 14:26:02 | fe1 | a7f4a79c-1524-11f0-9f54-58a2e1c214b4 | 0 | db2 | user1 | 28.044 GB | 11800576 rows | 4.267 GB | 0.000 B | 115.344 s | 746.592 s | default_warehouse | | rg |
| 2025-04-09 14:31:17 | fe1 | 63b27b8c-1525-11f0-8e05-58a2e1a95f4c | 29255 | db2 | user1 | 290.207 GB | 16443945800 rows | 172.825 GB | 0.000 B | 1228.805 s | 431.617 s | default_warehouse | | analytics |
| 2025-04-09 14:35:47 | fe1 | 043e07ce-1526-11f0-8e05-58a2e1a95f4c | 29579 | db3 | user3 | 9.433 GB | 10895360 rows | 830.153 MB | 0.000 B | 27.895 s | 162.280 s | default_warehouse | | rg |
| 2025-04-09 14:36:09 | fe1 | 115503cb-1526-11f0-8e05-58a2e1a95f4c | 29611 | db2 | user3 | 139.967 GB | 675728009 rows | 1.752 TB | 0.000 B | 4908.952 s | 140.262 s | default_warehouse | | analytics |
| 2025-04-09 14:36:26 | fe1 | 1bc5977f-1526-11f0-8e05-58a2e1a95f4c | 29638 | db1 | user3 | 5.356 GB | 6778880 rows | 1.672 GB | 0.000 B | 28.672 s | 122.801 s | default_warehouse | | rg |
| 2025-04-09 14:36:39 | fe1 | 23a5e2fd-1526-11f0-8e05-58a2e1a95f4c | 17450 | db1 | user1 | 40.721 GB | 275856819 rows | 14.370 GB | 0.000 B | 46713.143 s | 109.578 s | default_warehouse | | analytics |
| 2025-04-09 14:37:20 | fe1 | 3bb455c1-1526-11f0-ae9c-58a2e1bc0436 | 0 | db3 | user1 | 3.294 GB | 5586944 rows | 648.471 MB | 0.000 B | 11.011 s | 69.228 s | default_warehouse | | rg |
+---------------------+---------------------+--------------------------------------+--------------+----------+--------------------+------------+------------------+-------------+---------------+-------------+------------+-------------------+---------------+---------------+
查看具体某个sql在be侧的资源消耗
mysql> show proc '/current_queries/e432d68b-1527-11f0-8e05-58a2e1a95f4c/hosts';
+--------------------+------------+------------+----------------+-----------------+
| Host | ScanBytes | ScanRows | CpuCostSeconds | MemUsageBytes |
+--------------------+------------+------------+----------------+-----------------+
| be1:8060 | 892.682 MB | 48779 rows | 88.283 s | 16.992 MB |
| be2:8060 | 887.655 MB | 48848 rows | 79.635 s | 6.705 GB |
| be3:8060 | 882.707 MB | 48531 rows | 92.690 s | 7.525 GB |
| be4:8060 | 908.493 MB | 49199 rows | 97.415 s | 7.739 GB |
| be5:8060 | 898.157 MB | 48978 rows | 114.186 s | 8.507 GB |
| be6:8060 | 893.427 MB | 48497 rows | 109.230 s | 8.262 GB |
| be7:8060 | 895.787 MB | 48888 rows | 111.882 s | 8.510 GB |
| be8:8060 | 902.435 MB | 49060 rows | 113.347 s | 13.580 MB |
| be9:8060 | 897.161 MB | 48995 rows | 101.420 s | 7.783 GB |
| be10:8060 | 888.565 MB | 48995 rows | 150.883 s | 110.370 GB |
| be11:8060 | 904.634 MB | 49014 rows | 115.308 s | 8.058 GB |
| be12:8060 | 887.911 MB | 48393 rows | 107.796 s | 282.750 KB |
| be13:8060 | 897.564 MB | 48944 rows | 81.154 s | 20.759 MB |
+--------------------+------------+------------+----------------+-----------------+
也可以通过审计日志分析,插件安装参考 https://docs.starrocks.io/zh/docs/administration/management/audit_loader/
select timestamp,queryTime,stmt,memcostbytes,state from starrocks_audit_db__.starrocks_audit_tbl__ where TIMESTAMP>"2025-03-01 00:00:00" and timestamp<"2025-03-01 01:45:00" order by 4 desc limit 10;
1.1.2通过 top/perf排查
- 使用ps -ef定位be进程号
[yaochenggong@cs02 ~]$ ps aux|grep starrocks_be
yaochenggong+ 4921 0.2 0.1 3121372 80488 ? Sl Nov03 20:05 /home/disk1/yaochenggong/StarRocks-2.5.13/be/lib/starrocks_be
## 查找be线程对应的pid,如上所示为4921
- 查看具体线程
首先可以获取 top 结果并截图
top -Hp $be_pid
获取下 perf 的结果, 论坛提交帖子分析。
sudo perf top -p $be_pid -g >/tmp/perf.txt #执行1-2分钟,CTRL+C掉即可
1.1.3 通过 pstack 分析
- 尝试命令获取栈,连接fe执行下面语句,$backend_id为有问题的BE节点
admin execute on $backend_id 'System.print(ExecEnv.get_stack_trace_for_all_threads())'
- 使用 pstack 查看进程信息,下载工具 :
wget "https://cdn-thirdparty.mirrorship.cn/SRDebugUtil.tar.gz" -O SRDebugUtil.tar.gz
或者flamegraph工具 (详细步骤见github中README.md)
https://github.com/brendangregg/FlameGraph
如果走 SRDebugUtil 方式,先进行解压:
tar -zvxf SRDebugUtil.tar.gz
执行命令 获取 pstack 文件 ,论坛或者 github 提交 issue
cd SRDebugUtil
./bin/pstack 4921 >pstack.log ##获取be线程并输出文件,示例bepid为4921
1.1.4紧急处理
紧急情况下,为尽快恢复服务,可尝试重启对应的BE服务( 重启前保留pstack )(紧急情况:BE节点进程监控持续异常打满,无法通过有效手段降低cpu使用率)
1.2 BE 内存使用量过载:
PromSQL
starrocks_be_process_mem_bytes > 机器内存*90%
报警描述
当 BE 内存使用率超过 90% 时发送报警。
处理方法:
1.2.1 方法一:
可以从grafana的 BE Memory 模块查看具体是哪个部分内存增长
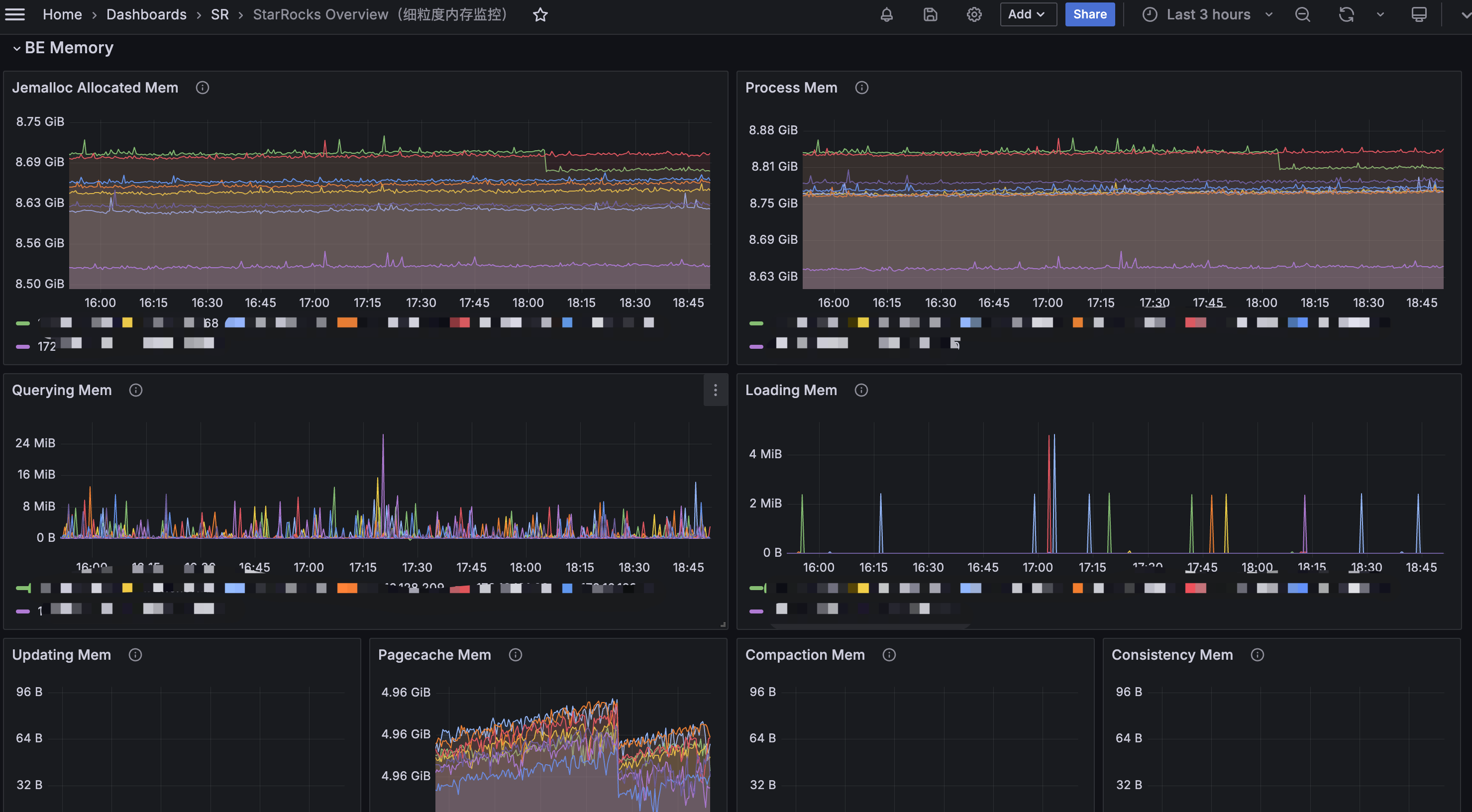
或通过 curl 命令来打印出具体的内存占比大小:
curl -XGET -s http://BE_IP:BE_HTTP_PORT/metrics | grep "^starrocks_be_.*_mem_bytes"
starrocks_be_bitmap_index_mem_bytes 2664800
starrocks_be_bloom_filter_index_mem_bytes 0
starrocks_be_column_metadata_mem_bytes 8368362336
starrocks_be_column_zonemap_index_mem_bytes 2823870320
starrocks_be_metadata_mem_bytes 13695679978
starrocks_be_ordinal_index_mem_bytes 4181644400
starrocks_be_rowset_metadata_mem_bytes 1666077053
starrocks_be_segment_metadata_mem_bytes 1189811470
starrocks_be_segment_zonemap_mem_bytes 821131057
starrocks_be_short_key_index_mem_bytes 149789730
starrocks_be_tablet_metadata_mem_bytes 2471429119
starrocks_be_tablet_schema_mem_bytes 432304679
starrocks_be_chunk_allocator_mem_bytes 0 ## 提高内存分配性能的 Cache,默认上限 2G
starrocks_be_clone_mem_bytes 0 ## clone tablet 使用的内存, 内存使用一般比较小
starrocks_be_column_pool_mem_bytes 0 ## 用于加速内存分配的 Pool,当前没有上限
starrocks_be_compaction_mem_bytes 0 ## Compaction 内存使用
starrocks_be_consistency_mem_bytes 0 ## consistency 计算 CheckSum 内存使用
starrocks_be_load_mem_bytes 0 ## 导入内存使用
starrocks_be_process_mem_bytes 95674408 ## 我们内存统计的 BE 进程内存使用
starrocks_be_query_mem_bytes 0 ## 查询内存使用
starrocks_be_schema_change_mem_bytes 0 ## SchemaChange 内存使用
starrocks_be_storage_page_cache_mem_bytes 0 ## BE 自有 StoragePageCache 内存使用
starrocks_be_tablet_meta_mem_bytes 14249776 ## Tablet 元数据内存使用
starrocks_be_update_mem_bytes 0 ## PrimaryKey 模型内存使用
具体看占用的大小后 ,我们可以根据对应的指标去查看不合理详情项,根据具体的指标去进行调整:
1.2.2 方法二:
通过 web 界面可以打印 mem_tracker 信息:
http://be_ip:8040/mem_tracker
展示界面为:
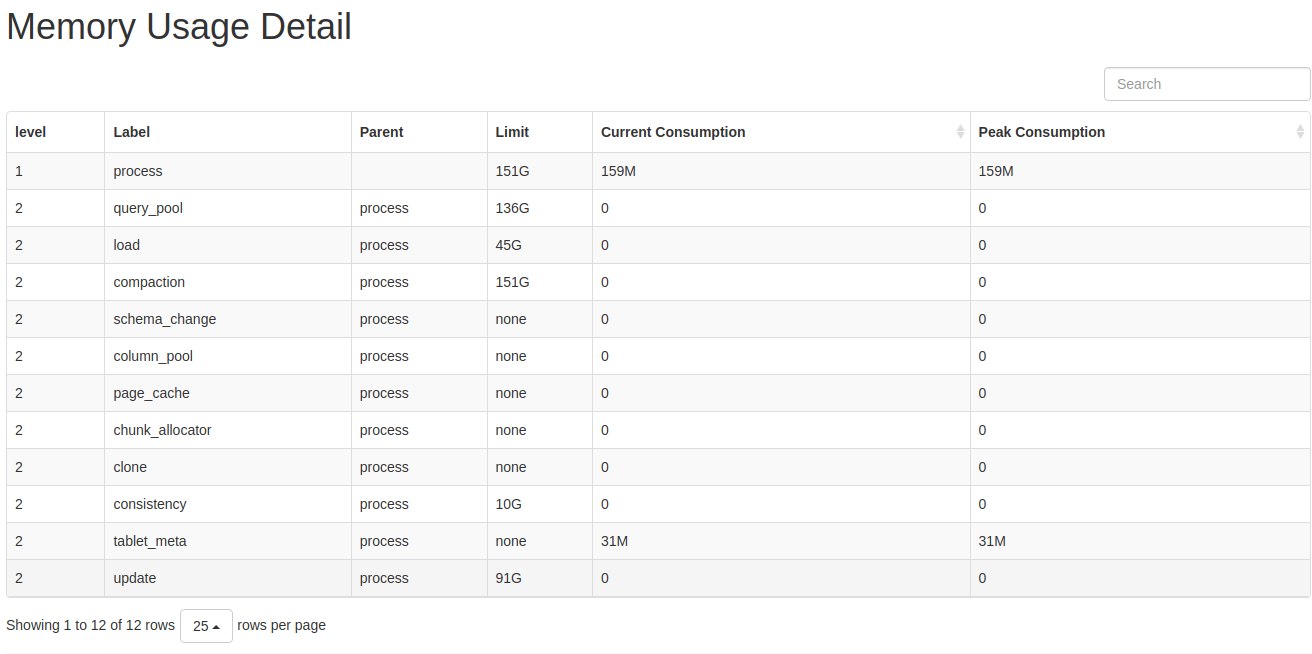
具体指标解释:
-
level: MemTracker 为树型结构,第一级为 BE 使用总内存,第二级为分类内存使用。 -
Label: 标识内存分类,对应指标的含义参考 内存分类。 -
Parent: 父结点 Label。 -
Limit: 内存使用限制,-1表示没有限制。 -
Current Consumption: 当前内存使用。 -
Peak Consumption: 峰值内存使用。
跟上述的方式一样,可以大体看出是哪一块占用的内存过多,从而可以进行合理的调整或者紧急处理进行重启 。
1.2.3 紧急处理:
- 紧急情况下,为尽快恢复服务,可尝试重启对应的BE服务 (紧急情况:BE节点进程内存监控持续异常打满,无法通过有效定位采取手段降低使用内存)
1.3 机器内存使用率高
PromSQL
(1-node_memory_MemAvailable_bytes{instance=~".*"}/node_memory_MemTotal_bytes{instance=~".*"})*100 > 90
报警描述
当机器内存使用率超过 90% 时发送报警。
处理方法
- 如果没有混合部署其他服务,则可以参考2和3排查 FE 或 BE 的内存占用
- 如果混合部署了其他服务,请通过 top 命令排查具体进程
紧急处理:
- 紧急情况下,为尽快恢复服务,可尝试重启对应的 BE 服务 (紧急情况:BE 节点进程内存监控持续异常打满,无法通过有效定位采取手段降低使用内存)
- 如果是其他服务影响了StarRocks,紧急情况下可考虑停掉其他服务
1.4 磁盘负载过高
PromSQL
rate(node_disk_io_time_seconds_total{instance=~".*"}[5m]) * 100 > 90
报警描述
当机器磁盘负载使用率超过 90% 时发送报警。
处理方法
node_disk_io_time_seconds_total每个 BE 节点上磁盘的 I/O util 指标。数值越高表示 I/O 越繁忙。当然大部分情况下 I/O 资源都是查询请求消耗的。
如果存在node_disk_io_time_seconds_total的告警 那么要先确认下业务上是否有变化,如果有的话能否回滚变更,维系回之前的资源平衡条件,没有的话则考虑是否是正常的业务增长导致需要扩容资源
1.4.1 排查机器是否有其他应用混部
是否有其他应用异常行为占用磁盘 I/O
iotop 查看是否有其他进程占用磁盘IO
1.4.2 是否有大查询
参考2.1
一般来讲大表的 SQL 做好分区的数据裁剪可以有效减少数据扫描量,此时可以检查下 SQL 的查询条件和该节点扫描的表是否建表比较合理。避免出现没有分区引起的无效io资源消耗。
1.4.3 是否有大量导入
grafana 的 BE 模块可以观察下导入字节和行数是否有大的变化

1.4.4 是否有创建物化视图、schema change 等操作
创建物化视图,schema change 是异步操作,耗用资源和实际数据量有关
可通过以下指令查看物化视图进度
SHOW ALTER MATERIALIZED VIEW FROM db_name;
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
| JobId | TableName | CreateTime | FinishedTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
| 22324 | sales_records | 2020-09-27 01:02:49 | 2020-09-27 01:03:13 | sales_records | store_amt | 22325 | 672 | FINISHED | | NULL | 86400 |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+----------+------+----------+---------+
可通过如下指令查看 schema change 任务进度
SHOW ALTER TABLE COLUMN;
建议在业务低峰期做大表的物化视图创建以及 schema change
1.4.5 如果还不能判断 I/O 负载上升原因,则登录io负载高的机器判断
- iotop 查看哪些进程占用 I/O 负载
可以使用 iotop 工具去分析监视磁盘 I/O 使用状况,iotop 具有与 top 相似的 UI,其中包括 pid、user、I/O、进程等相关信息等
yum -y install iotop
执行 iotop 显示:
iotop
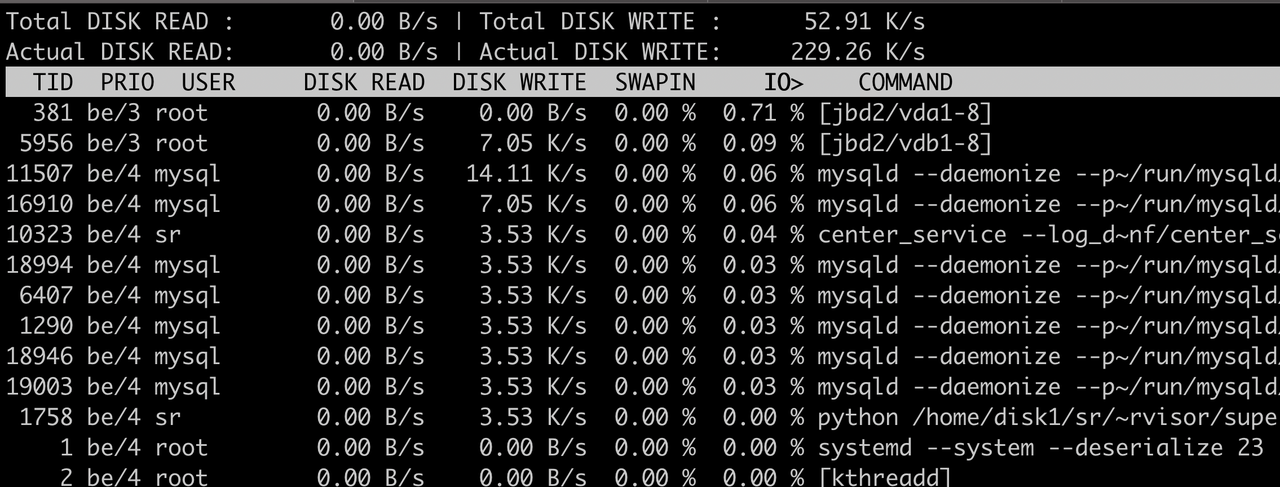
输出解释:
Total DISK READ:从磁盘中读取的总速率
Total DISK WRITE:往磁盘里写入的总速率
Actual DISK READ:从磁盘中读取的实际速率
Actual DISK WRITE:往磁盘里写入的实际速率
TID:线程ID,按p可转换成进程ID
PRIO:优先级
USER:线程所有者
DISK READ:从磁盘中读取的速率
DISK WRITE:往磁盘里写入的速率
SWAPIN:swap交换百分比
IO>:IO等待所占用的百分比
COMMAND:具体的进程命令
详情见指标和使用方式见 --help
父子进程和运行中的环境变量查看

ls /proc/$pid


- iostat 判断读还是写
可以使用 iostat 工具去分析 磁盘的具体使用情况 iostat 是位于 sysstat 包中的,可以使用 yum 可以对其直接进行安装
yum install sysstat -y
iostat 命令的基本格式如下所示:
iostat <options> <device name>
- -c: 显示 CPU 使用情况
- -d: 显示磁盘使用情况
- –dec={ 0 | 1 | 2 }: 指定要使用的小数位数,默认为 2
- -g GROUP_NAME { DEVICE […] | ALL } 显示一组设备的统计信息
- -H 此选项必须与选项 -g 一起使用,指示只显示组的全局统计信息,而不显示组中单个设备的统计信息
- -h 以可读格式打印大小
- -j { ID | LABEL | PATH | UUID | … } [ DEVICE […] | ALL ] 显示永久设备名。选项 ID、LABEL 等用于指定持久名称的类型
- -k 以 KB 为单位显示
- -m 以 MB 为单位显示
- -N 显示磁盘阵列(LVM) 信息
- -n 显示NFS 使用情况
- -p [ { DEVICE [,…] | ALL } ] 显示磁盘和分区的情况
- -t 打印时间戳。时间戳格式可能取决于 S_TIME_FORMAT 环境变量
- -V 显示版本信息并退出
- -x 显示详细信息(显示一些扩展列的数据)
- -y 如果在给定的时间间隔内显示多个记录,则忽略自系统启动以来的第一个统计信息
- -z 省略在采样期间没有活动的任何设备的输出
常见的命令行的使用如下所示:
iostat -d -k 1 10 #查看TPS和吞吐量信息(磁盘读写速度单位为KB),每1s收集1次数据,共收集10次
iostat -d -m 2 #查看TPS和吞吐量信息(磁盘读写速度单位为MB),每2s收集1次数据
iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)等详细数据, 每1s收集1次数据,总共收集10次
iostat -c 1 10 #查看cpu状态,每1s收集1次数据,总共收集10次
iostat 输出内容分析:
在 linux 命令行中输入 iostat,通常将会出现下面的输出:
[root@localhost ~]# iostat
Linux 5.14.0-284.11.1.el9_2.x86_64 (localhost.localdomain) 08/07/2023
x86_64
(4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.31 0.01 0.44 0.02 0.00 99.22
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
dm-0 3.19 72.63 35.90 0.00 202007 99835 0
dm-1 0.04 0.84 0.00 0.00 2348 0 0
nvme0n1 3.36 93.22 36.64 0.00 259264 101903 0
sr0 0.02 0.75 0.00 0.00 2096 0 0
首先第一行:
Linux 5.14.0-284.11.1.el9_2.x86_64 (localhost.localdomain) 08/07/2023 x86_64 (4 CPU)
Linux 5.14.0-284.11.1.el9_2.x86_64是内核的版本号,localhost.localdomain则是主机的名字, 08/07/2023 当前的日期, _x86_64_是 CPU 的架构, (4 CPU)显示了当前系统的 CPU 的数量。
接着看第二部分,这部分是 CPU 的相关信息,其实和 top 命令的输出是类似的。
avg-cpu: %user %nice %system %iowait %steal %idle
0.31 0.01 0.44 0.02 0.00 99.22
cpu 属性值说明:
- %user:CPU 处在用户模式下的时间百分比。
- %nice:CPU 处在带 NICE 值的用户模式下的时间百分比。
- %system:CPU 处在系统模式下的时间百分比。
- %iowait:CPU 等待输入输出完成时间的百分比。
- %steal:管理程序维护另一个虚拟处理器时,虚拟 CPU 的无意识等待时间百分比。
- %idle:CPU 空闲时间百分比。
看第三部分的输出结果。
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
dm-0 3.19 72.63 35.90 0.00 202007 99835 0
dm-1 0.04 0.84 0.00 0.00 2348 0 0
nvme0n1 3.36 93.22 36.64 0.00 259264 101903 0
sr0 0.02 0.75 0.00 0.00 2096 0 0
其每一列的含义如下所示:
- Device:/dev 目录下的磁盘(或分区)名称
- tps:该设备每秒的传输次数。一次传输即一次 I/O 请求,多个逻辑请求可能会被合并为一次 I/O 请求。一次传输请求的大小是未知的
- kB_read/s:每秒从磁盘读取数据大小,单位 KB/s
- kB_wrtn/s:每秒写入磁盘的数据的大小,单位 KB/s
- kB_dscd/s: 每秒磁盘的丢块数,单数 KB/s
- kB_read:从磁盘读出的数据总数,单位 KB
- kB_wrtn:写入磁盘的的数据总数,单位 KB
- kB_dscd: 磁盘总的丢块数量
实际使用的时候 ,我们一般执行的都是 iostat -kx 1 ,查看输出为:

从 wkB 指标得知,现在磁盘的写入速度在多少。从 %util 指标得知,目前磁盘的使用率是多少右。
- 查看是哪些文件
然后查看是读写那些文件导致的,过滤的时候需要将盘符换成目录,例如上面被打满的盘符是vdb,通过df -h可以看到vdb被挂载到/data1,所以下面过滤的时候需要使用/data1
lsof -p $be_pid|grep '/data1'|grep 'w'
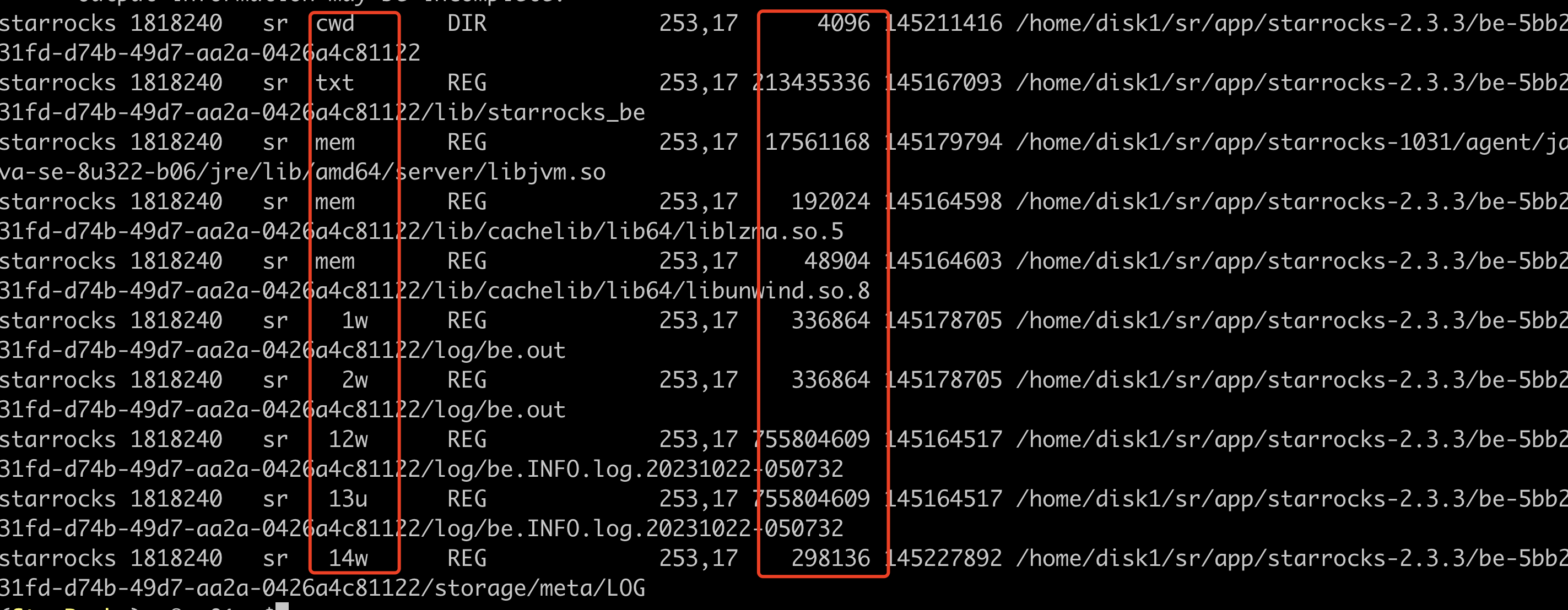
这里主要关注第4列和第7列,可以定位到是读写哪些文件导致的磁盘io被打满
第4列表示的 FD,一般只需要关注u、w、r,
(1)u:表示该文件被打开并处于读取/写入模式
(2)r:表示该文件被打开并处于只读模式
(3)w:表示该文件被打开并处于写入模式
第7列表示的文件大小,单位 bytes,可以多执行几遍,看看是不是频繁刷新文件,大概能判断哪个文件写吞吐比较大
紧急处理:
- 视情况紧急减少不必要的业务流量 ,并可以紧急重启 I/O 使用高的 BE 节点,释放I/O
- 长期打算如果是资源正常打满,则可以考虑进行扩容磁盘或者扩容节点 (推荐)
1.5 BE磁盘已用容量
PromSQL
(SUM(starrocks_be_disks_total_capacity{job="$job"}) by (host, path) - SUM(starrocks_be_disks_avail_capacity{job="$job"}) by (host, path)) / SUM(starrocks_be_disks_total_capacity{job="$job"}) by (host, path) * 100 > 90
报警描述
当磁盘容量使用率超过 90% 时发送报警。
处理方法:
1.5.1 排查导入数据量是否有变化

查看导入数据量是否有变化。可以关注 Grafana 监控中的 load_bytes 监控项,如果新增大量数据导入,建议您扩容系统资源。
1.5.2 排查是否有 drop 操作
如果数据导入量没有发生太大变化,show backends 中看到的 dataused 和磁盘占用不一致,可以核对下近期是否做过 drop database、drop table 或者 drop 分区的操作(fe.audit.log)
select timestamp,queryTime,stmt,state from starrocks_audit_db__.starrocks_audit_tbl__ where stmt like 'drop%';
这些操作涉及的元数据信息会在 fe 内存中保留1天(一天之内可以通过 recover 恢复数据,避免误操作),这个时候可能会出现,磁盘占用大于 show backends 中显示的已用空间,内存中保留1天可通过fe的参数 catalog_trash_expire_second调整,调整方式
admin set frontend config ("catalog_trash_expire_second"="86400") #如果需要持久化,记得加到fe.conf中
drop的数据在fe内存中过了1天后进入到了be的trash目录下(${storage_root_path}/trash),该数据默认会在trash目录保留3天,这个时候也会出现磁盘占用大于show backends中显示的已用空间,trash保留时间由be的配置 trash_file_expire_time_sec(默认259200,3天,自 v2.5.17、v3.0.9 以及 v3.1.6 起,默认值由 259,200 变为 86,400。),调整方式
update information_schema.be_configs set value=xxx where name="trash_file_expire_time_sec"; #如果需要持久化需要在be.conf新增该配置
建议:
- 清理数据推荐使用 truncate 命令 ,drop操作会进trash目录,一次删除较大的数据,如果能确认数据是无用数据,谨慎执行命令,推荐使用 drop force( DROP TABLE FORCE 语句会快速释放磁盘空间。执行 DROP TABLE FORCE 语句删除表时不会检查该表是否存在未完成的事务,而是直接将表删除。建议谨慎使用 DROP TABLE FORCE 语句,因为使用该语句删除的表不能恢复)
- 可以使用df -h、df -ih 、du -sh等命令辅助定位下占据磁盘空间比较多的非数据文件目录是哪个,例如fe日志或者be日志生成比较多,占用的空间比较大可以进行删除 、trash目录进行清理等。
1.6 根目录剩余空间不足
PromSQL
node_filesystem_free_bytes{mountpoint="/"} /1024/1024/1024 < 5
报警描述
当根目录空间容量剩余不足 5GB 时发送报警。
处理方法:
可以使用如下命令分析哪个目录空间占用较多,及时清理不需要的文件,一般可能占用空间较大的目录是/var,/opt,/tmp
du -h / --max-depth=1
1.7 FE元数据挂载点剩余空间不足
PromSQL
node_filesystem_free_bytes{mountpoint="${meta_path}"} /1024/1024/1024 < 10
报警描述
FE 元数据磁盘容量剩余不足 10GB 时发送报警。
处理方法:
可以使用如下命令分析哪个目录空间占用较多,及时清理不需要的文件,meta路径为fe.conf中配置meta_dir指定的路径
du -h /${meta_dir} --max-depth=1
如果是meta目录占用空间比较大,一般都是因为bdb目录占用比较大,可能是checkpoint失败,可参考2.3排查,如果无进展,可以在论坛提帖子排查。

2. 集群服务异常
2.1 服务挂起
FE服务挂起
PromSQL
count(up{group="fe", job="$job_name"}) >= 3
报警描述
当存活的 FE 节点个数小于该值时发送报警。您可以根据实际 FE 节点个数调整。
处理方法:
2.1.1 常见 Case1
FE之间时钟不同步,超过5s
Caused by: com.sleepycat.je.EnvironmentFailureException: Environment invalid because of previous exception: (JE 7.3.7) 10.99.70.11_9010_1708740261959(1):/data/StarRockfe/fe/meta/bdb Clock delta: -6146 ms.
解决方法:
同步时钟,重启拉起FE
2.1.2 常见 Case2
meta 所在磁盘空间小于 5g
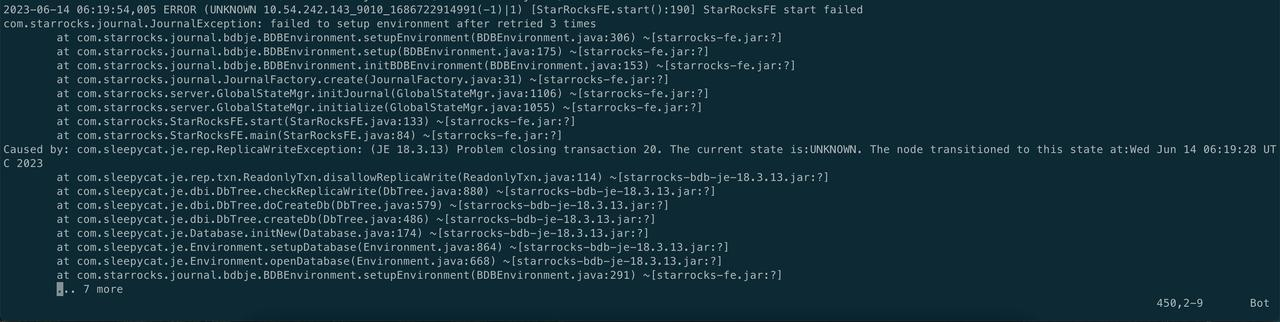
解决办法:
扩容 meta 所在的磁盘,bdb 启动时需要保证有大于5g的磁盘空间。
2.1.3 常见 Case3
一些功能回放的时候异常
catch exception when replaying journal, id: 310080247
com.starrocks.journal.JournalInconsistentException: failed to load journal type 210
fe.conf 中加下报错的journal id尝试拉起恢复,另外在 github 提交 issue
metadata_journal_skip_bad_journal_ids=310080247
2.1.4 常见 Case4
一些功能回放的时候异常
Caused by: java.io.IOException: UNKNOWN Operation Type 10005
解决方法:
- 停止所有 FE 节点。
- 备份所有 FE 节点的元数据目录
meta_dir。 - 在所有 FE 节点的配置文件 fe.conf 中添加配置
metadata_ignore_unknown_operation_type = true。 - 启动所有 FE 节点,并检查数据和元数据是否完整。
- 如果数据和元数据都完整,请执行以下语句为元数据创建镜像文件:
ALTER SYSTEM CREATE IMAGE;
- 在新的镜像文件传输到所有 FE 节点的目录 meta/image 之后,需要从所有 FE 节点的配置文件中移除配置项
metadata_ignore_unknown_operation_type = true,并重新启动 FE 节点。
其他case可参考 https://docs.starrocks.io/zh/docs/3.3/administration/Meta_recovery/#基于备份在新-fe-节点恢复元数据
紧急处理:
- 如果只是其中一台非 leader FE 异常,可以先从负载均衡器摘除该FE流量,然后通过下线扩容的方式重新加入集群
BE 服务挂起
PromSQL
node_info{type="be_node_num", job="$job_name",state="dead"} > 1
报警描述
当挂起的 BE 节点个数大于 1 时发送报警。
处理方法:
参考 [问题排查]BE Crash 处理
常见 Case1
加载 tablet 元数据失败,导致be启动失败
#检查日志是否存在 load tablets encounter failure 错误:
grep -a 'load tablets encounter failure' be.INFO
#检查日志是否存在 there is failure when scan rockdb tablet metas 错误:
grep -a 'there is failure when scan rockdb tablet metas' be.INFO
#如果 there is failure when scan rockdb tablet metas 不存在,执行以下步骤:
在 be.conf 文件中添加以下配置:ignore_load_tablet_failure = true
#保存配置后,重启 BE 服务。
常见 Case2
磁盘故障,一般报错如下
store read/write test file occur IO Error. path=
解决方法:
从 storage_root_path 中去掉故障磁盘( 注意如果有单副本的表的副本在这块盘上,数据就丢失了 ),重新拉起 BE 恢复
常见 Case3
某个查询触发了 bug,导致 be crash,一般 be.out 中会打印 query_id,日志如下
3.2.3-ee RELEASE (build 3a4a58a)
query_id:609db622-3385-11ef-9a6e-fa202031603d, fragment_instance:609db622-3385-11ef-9a6e-fa202031603e
……
tracker:replication consumption: 0
*** Aborted at 1719383341 (unix time) try "date -d @1719383341" if you are using GNU date ***
PC: @ 0x341de7d starrocks::Chunk::clone_empty()
*** SIGSEGV (@0x8) received by PID 168622 (TID 0x2ad680c13700) from PID 8; stack trace: ***
@ 0x674c5c2 google::(anonymous namespace)::FailureSignalHandler()
@ 0x2ad63bc0fe92 os::Linux::chained_handler()
@ 0x2ad63bc16526 JVM_handle_linux_signal
@ 0x2ad63bc0cb03 signalHandler()
@ 0x2adb612da17d (/tmp/libjfs-amd64.7.so (deleted)+0x6da17c)
解决方法:
如果频繁都是同一个 SQL,可以将该 SQL 加入黑名单
SQL 加黑名单, 需要多个 fe 添加
ADMIN SET FRONTEND CONFIG ("enable_sql_blacklist" = "true");
ADD SQLBLACKLIST “sql”;
例如 select 的话可以使用如下方式
ADD SQLBLACKLIST "select\s+(.*)from\s+${table_name}"
2.2 JVM空间不足
PromSQL
sum(jvm_heap_size_bytes{job="$job_name", type="used"}) * 100 / sum(jvm_heap_size_bytes{job="$job_name", type="max"}) > 90
报警描述
当 FE 节点 JVM 使用率持续超过 90% 时发送报警。
处理方法:
可以部署以下脚本在对应 fe 节点,${fe_path} 为 fe 部署路径
#!/bin/bash
mkdir -p mem_alloc_log
while true
do
current_time=$(date +'%Y-%m-%d-%H-%M-%S')
file_name="mem_alloc_log/alloc-profile-${current_time}.html"
${fe_path}/bin/async-profiler/bin/asprof -e alloc --alloc 2m -d 60 -f "$file_name" `cat ${fe_path}/bin/fe.pid`
done
3.2+ 版本,可以开启 fe 的 mem profile 功能,默认会5分钟抓取 profile,默认存储路径在 fe/log/proc_profile
mysql> admin show frontend config like '%mem%';
+--------------------------------------------------+------------+-----------+---------+-----------+--------------------------------------------------+
| Key | AliasNames | Value | Type | IsMutable | Comment |
+--------------------------------------------------+------------+-----------+---------+-----------+--------------------------------------------------+
| iceberg_metadata_memory_cache_capacity | [] | 536870912 | long | true | |
| iceberg_metadata_memory_cache_expiration_seconds | [] | 86500 | long | true | |
| memory_tracker_enable | [] | true | boolean | true | |
| memory_tracker_interval_seconds | [] | 60 | long | true | |
| proc_profile_mem_enable | [] | true | boolean | true | true to enable collect proc memory alloc profile |
+--------------------------------------------------+------------+-----------+---------+-----------+--------------------------------------------------+
5 rows in set (0.00 sec)
打开 mem profile 的文件,可以看到类似如下内存占用,如下图所示,可以看到该问题是由于 alter replica 相关的任务引起
紧急处理:
- 持续打高不释放的情况下可以重启下对应的FE节点或者调大 jvm(Xmx)重启 fe 服务恢复
- 一般瞬间内存被打满,可能是有复杂 SQL,可以排查出问题时间点附近的审计日志,将复杂 SQL 加入黑名单临时规避
2.3 checkpoint 异常
PromSQL
starrocks_fe_meta_log_count{job="$job_name",instance="$fe_master"} > 100000
报警描述
当 FE 节点 BDB 日志数量超过 100000 时发送报警。默认设置下,BDB 日志数量超过 50000 时,系统会进行 CheckPoint。BDB 日志数量将会重置为 0 并重新累加。
处理办法
该报警是由于未进行 CheckPoint 导致,需要通过 FE 日志排查 CheckPoint 的情况并解决问题:
在 Leader FE 节点的 fe.log 中搜索是否存在 begin to generate new image: image.xxxx 条目。如果存在,则表明系统已开始生成 Image。继续查看该线程的后续日志,如果出现 checkpoint finished save image.xxxx 条目,则说明 Image 写入成功,如果出现 Exception when generate new image file ,则表示 Image 生成失败。随后您需要根据具体的错误信息 ,谨慎操作元数据。建议在此之前联系支持人员进行分析。
2.4 FE 线程数过多
PromSQL
starrocks_fe_thread_pool{job="$job_name"} > 3000
报警描述
当 FE 线程池大小超过 3000 时发送报警。
处理办法
FE 和 BE 节点的线程数默认是 4096。通常情况下,大量的 UNION ALL 查询会导致过高的线程数。建议您调低 UNION ALL 查询的并发,并调整系统变量 pipeline_dop 。如果无法调整 SQL 粒度,可以全局调整 pipeline_dop :
SET GLOBAL pipeline_dop=8;
紧急情况下,为尽快恢复服务,可以选择调大 FE 动态参数 thrift_server_max_worker_threads (默认值:4096)。
ADMIN SET FRONTEND CONFIG ("thrift_server_max_worker_threads"="8192");
2.5 compaction异常:
2.5.1 Cumulative Compaction 失败报警
PromSQL
increase(starrocks_be_engine_requests_total{job="$job_name" ,status="failed",type="cumulative_compaction"}[1m]) > 3
increase(starrocks_be_engine_requests_total{job="$job_name" ,status="failed",type="base_compaction"}[1m]) > 3
报警描述
最近 1 分钟内有三次 Cumulative Compaction 失败或三次 Base Compaction 失败时发送报警。
处理办法
在对应 BE 节点日志中搜索以下关键字,确定失败涉及的 Tablet。
grep -E 'compaction' be.INFO | grep failed
如果有如下日志,则表示存在 Compaction 失败。
W0924 17:52:56:537041 123639 comaction_task_cpp:193] compaction task:8482. tablet:8423674 failed.
您可以获取该 Tablet 对应日志的上下文排查失败原因。通常情况下,失败可能是在 Compaction 过程中进行了 DROP TABLE 或 PARTITION 操作导致。系统内部有 Compaction 重试策略,您也可以手动设置 Tablet 状态为 BAD 并触发重新 Clone 任务以修复。
进行以下操作前需保证当前表至少有三个副本完整。
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "$tablet_id", "backend_id" = "$backend_id", "status" = "bad");
2.5.2 Compaction 压力大报警
PromSQL
starrocks_fe_max_tablet_compaction_score{job="$job_name",instance="$fe_leader"} > 100
报警描述
当最大 Compaction Score 超过 100,即 Compaction 压力较大时发送报警。
处理办法
该报警通常是由于发起了高频率(每秒 1 次)的导入、INSERT INTO VALUES 或 DELETE 任务所导致。建议为导入或 DELETE 任务设置 5 秒以上的间隔。不建议高并发提交 DELETE 任务。
2.5.3 版本个数超限制报警
PromSQL
starrocks_be_max_tablet_rowset_num{job="$job_name"} > 700
报警描述
当有 BE 节点中 Tablet 最大的版本个数超过 700 时发送报警。
处理办法
通过以下语句查看版本数过多的 Tablet:
SELECT BE_ID,TABLET_ID FROM information_schema.be_tablets WHERE NUM_ROWSET>700;
以下以 ID 为 2889156 的 Tablet 为例:
SHOW TABLET 2889156;
执行 DetailCmd 字段中返回的指令:
SHOW PROC '/dbs/2601148/2889154/partitions/2889153/2889155/2889156';
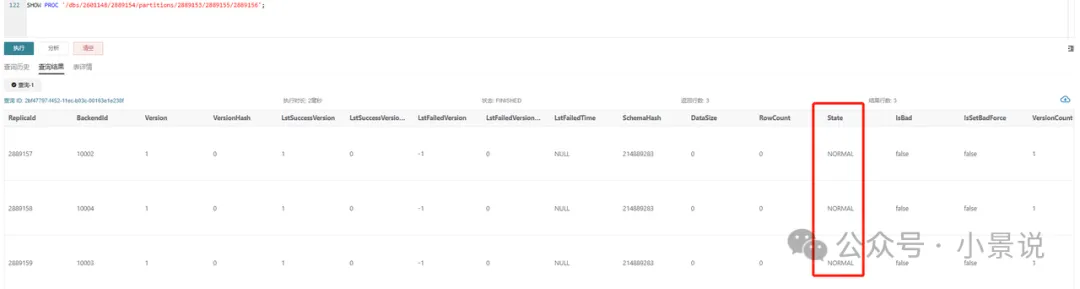
正常情况下,如图所示,三副本都应该为 NORMAL 状态,且其余指标基本保持一致,例如 RowCount 以及 DataSize 。如果只有一个副本版本数超过 700,则可以通过如下指令触发基于其他副本的 Clone 任务:
ADMIN SET REPLICA STATUS PROPERTIES("tablet_id" = "$tablet_id", "backend_id" = "$backend_id", "status" = "bad");
如果有 2 个以上副本都超过了版本限制,您可暂时调大版本个数限制:
以下 be_ip 为上述过程中查到版本超过限制的 BE 节点的 IP,be_http_port 默认为 8040。
# tablet_max_versions 默认值为 1000。
update information_schema.be_configs set value=2000 where name="tablet_max_versions";
3. 业务可用性异常
3.1 查询服务异常
3.1.1 查询失败:
PromSQL
sum by (job,instance)(starrocks_fe_query_err_rate{job="$job_name"}) * 100 > 10
# 该 PromSQL 自 v3.1.15、v3.2.11 及 v3.3.3 起支持。
increase(starrocks_fe_query_internal_err{job="$job_name"})[1m] >10
报警描述
当查询失败率高于 0.1/秒或者 1 分钟内查询失败新增 10 个时发送报警。
处理方法:
当该报警被触发时,您可以首先通过日志来确认有哪些查询报错:
grep 'State=ERR' fe.audit.log
如果您安装了 AuditLoder 插件,则可以通过如下方式查找对应的查询:
SELECT stmt FROM starrocks_audit_db__.starrocks_audit_tbl__ WHERE state='ERR';
需要注意的是,当前语法错误、超时等类型的查询也会被记录为 starrocks_fe_query_err_rate 中失败的查询。
由于SR内核异常导致查询失败的SQL,需要获取fe.log中完整的异常栈(在 fe.log 中搜索报错的sql)和 https://docs.starrocks.io/zh/docs/faq/Dump_query/ 在论坛开帖子排查。
3.1.2 连接数或者 QPS 过载
PromSQL
abs((sum by (exported_job)(rate(starrocks_fe_query_total{process="FE",job="$job_name"}[3m]))-sum by (exported_job)(rate(starrocks_fe_query_total{process="FE",job="$job_name"}[3m] offset 1m)))/sum by (exported_job)(rate(starrocks_fe_query_total{process="FE",job="$job_name"}[3m]))) * 100 > 100
abs((sum(starrocks_fe_connection_total{job="$job_name"})-sum(starrocks_fe_connection_total{job="$job_name"} offset 3m))/sum(starrocks_fe_connection_total{job="$job_name"})) * 100 > 100
报警描述
当最近 1 分钟的 QPS 或连接数环比增加 100% 时发送报警。
处理办法
查看 fe.audit.log 中高频出现的查询是否符合预期。如果业务上有正常行为变更(比如新业务上线了或业务数据量变更),需要关注机器负载并及时扩容 BE 节点。
3.1.3 用户粒度连接数超限报警
PromSQL
sum(starrocks_fe_connection_total{job="$job_name"}) by(user) > 90
报警描述
当用户粒度连接数大于 90 时发送报警。(用户粒度连接数从 v3.1.16、v3.2.12 及 v3.3.4 起支持)
处理办法
您可通过 SQL 语句 SHOW PROCESSLIST 查看当前连接数是否符合预期,并通过 KILL 语句终止不符合预期的连接。此后需检查是否前端有业务侧使用不当导致连接长时间未释放,也可通过调整系统变量 wait_timeout (单位:秒)加速系统自动终止空闲时间过久的连接。
SET wait_timeout = 3600;
紧急情况下,为尽快恢复服务,可以通过调大对应用户的连接数限制解决:
- v3.1.16、v3.2.12 及 v3.3.4 及其以后版本:
ALTER USER 'jack' SET PROPERTIES ("max_user_connections" = "1000");
- v2.5 及上述版本以前版本:
SET PROPERTY FOR 'jack' 'max_user_connections' = '1000';
3.1.4 查询 P95 耗时升高
PromSQL
starrocks_fe_query_latency_ms{job="$job_name", quantile="0.95"} > 5000
报警描述
当查询耗时 P95 大于 5 秒时发送报警。
处理办法
- 排查是否存在大查询。您需要查看在监控指标异常的时间段,是否有部分大查询占用了大量的机器资源导致其他查询超时失败或者失败。
- 您可以执行
show proc '/current_queries';查看大查询的QueryId。如需快速恢复服务,可以通过 KILL 语句终止执行时间最长的查询。
mysql> SHOW PROC '/current_queries';
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
| QueryId | ConnectionId | Database | User | ScanBytes | ProcessRows | CPUCostSeconds | MemoryUsageBytes | ExecTime |
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
| 7c56495f-ae8b-11ed-8ebf-00163e00accc | 4 | tpcds_100g | root | 37.88 MB | 1075769 Rows | 11.13 Seconds | 146.70 MB | 3804 |
| 7d543160-ae8b-11ed-8ebf-00163e00accc | 6 | tpcds_100g | root | 13.02 GB | 487873176 Rows | 81.23 Seconds | 6.37 GB | 2090 |
+--------------------------------------+--------------+------------+------+-----------+----------------+----------------+------------------+----------+
2 rows in set (0.01 sec)
- 您也可以选择直接重启 CPU 利用率较高的 BE 节点。
- 查看机器资源是否充足。您需要确认异常对应时间段的 CPU、内存、Disk I/O、网络流量监控信息是否正常。如果对应时间段内有异常,可以通过峰值流量的变化、集群资源的使用等方式来确认查询失败或卡住的原因。如果异常持续,您可以重启对应的节点。
紧急情况下,为尽快恢复服务,可以通过以下方式处理:
- 如果是异常峰值流量激增导致资源占用高引起的查询失败,可通过紧急减少业务流量,并重启对应的 BE 节点释放积压的查询。
- 如果是正常情况下资源占用高触发报警,则可以考虑扩容节点。
紧急处理:
- 如果是异常峰值流量激增导致资源打满的查询失败 可以紧急减少业务流量 并重启对应的BE节点 释放积压的查询
- 如果是资源正常打满触发告警值 则可以考虑进行扩容节点
3.2 写失败
PromSQL
rate(starrocks_fe_txn_failed{job="$job_name",instance="$fe_master"}[5m]) * 100 > 5
报警描述
当导入失败事务个数超过总量的 5% 时发送报警。
处理办法
查看 leader fe 日志
搜索导入报错的相关信息,可以搜索"status: ABORTED"关键字,查看导入失败的任务,可参考https://forum.mirrorship.cn/t/topic/4923/19排查
2024-04-09 18:34:02.363+08:00 INFO (thrift-server-pool-8845163|12111749) [DatabaseTransactionMgr.abortTransaction():1279] transaction:[TransactionState. txn_id: 7398864, label: 967009-2f20a55e-368d-48cf-833a-762cf1fe07c5, db id: 10139, table id list: 155532, callback id: 967009, coordinator: FE: 192.168.2.1, transaction status: ABORTED, error replicas num: 0, replica ids: , prepare time: 1712658795053, commit time: -1, finish time: 1712658842360, total cost: 47307ms, reason: [E1008]Reached timeout=30000ms @192.168.1.1:8060 attachment: RLTaskTxnCommitAttachment [filteredRows=0, loadedRows=0, unselectedRows=0, receivedBytes=1033110486, taskExecutionTimeMs=0, taskId=TUniqueId(hi:3395895943098091727, lo:-8990743770681178171), jobId=967009, progress=KafkaProgress [partitionIdToOffset=2_1211970882|7_1211893755]]] successfully rollback
常见case
errmsg=[E1008]Reached timeout=300000ms @10.128.8.78:8060
关注grafana模版中的 BE LOAD 模块,关注是否有队列被打满,是否有写入耗时比较久的模块
紧急处理:
如果有大量错误告警,可尝试重启 leader fe 或者写入报错的 be
3.3 Routine load 消费延迟
PromSQL
(sum by (job_name)(starrocks_fe_routine_load_max_lag_of_partition{job="$job_name",instance="$fe_mater"})) > 300000
starrocks_fe_routine_load_jobs{job="$job_name",host="$fe_mater",state="NEED_SCHEDULE"} > 3
starrocks_fe_routine_load_jobs{job="$job_name",host="$fe_mater",state="PAUSED"} > 0
报警描述
- 当消费延迟超过 300000 条时发送报警。
- 当待调度的 Routine Load 任务个数超过 3 时发送报警。
- 当有状态为 PAUSED 的任务时发送报警。
处理办法
- 首先排查routine load任务状态是否为RUNNING
show routine load from $db; #关注State字段
- 如果 routine load 任务状态为 PAUSED
关注上一步返回的 ReasonOfStateChanged 、 ErrorLogUrls 或 TrackingSQL,一般执行 TrackingSQL 对应的 SQL 可以看到具体的报错信息,例如

- 如果 routine load 任务状态为 RUNNING
可尝试调大任务并行度,单个 Routine Load Job 的并发度由以下四个值的最小值决定:
kafka_partition_num,kafka topic的分区个数
desired_concurrent_number,任务设置的并行度
alive_be_num,存活的be节点
max_routine_load_task_concurrent_num,fe的配置,默认5
一般需要调整任务的并行度或者 kafka 的 topic 分区个数(联系 kafka 的同学处理),以下是调整任务并行度的方法
ALTER ROUTINE LOAD FOR ${routine_load_jobname}
PROPERTIES
(
"desired_concurrent_number" = "5"
);
3.4 写入超过 db txn 限制
PromSQL
sum(starrocks_fe_txn_running{job="$job_name"}) by(db) > 900
报警描述
当单个 DB 导入事务个数超过 900 (v3.1 之前为 90)时发送报警。
处理办法
通常该报警是由于新增较多的导入任务或者写入事物变慢导致,您可以临时调大单个 DB 导入事务限制:
ADMIN SET FRONTEND CONFIG ("max_running_txn_num_per_db" = "2000");
写入变慢
在 leader fe 日志里面搜索对应的的事物统计信息或者开启 profile
常见 case1
2025-04-10 15:38:02.159+05:00 INFO (PUBLISH_VERSION|56) [DatabaseTransactionMgr.finishTransaction():1250] finish transaction TransactionState. txn_id: 880396384, label: 701691298-e1738d95-243c-494e-b6b0-75042a7358b2, db id: 373966221, table id list: 701691160, callback id: 701691298, coordinator: FE: sr01, transaction status: VISIBLE, error replicas num: 0, replica ids: , prepare time: 1744281475123, write end time: 1744281481873, allow commit time: -1, commit time: 1744281481873, finish time: 1744281482159, write cost: 6750ms, wait for publish cost: 126ms, publish rpc cost: 147ms, finish txn cost: 13ms, publish total cost: 286ms, total cost: 7036ms, reason: , attachment: RLTaskTxnCommitAttachment [filteredRows=0, loadedRows=5, unselectedRows=0, receivedBytes=16645, taskExecutionTimeMs=2121, taskId=TUniqueId(hi:-2201260121156466354, lo:-5282593702153070414), jobId=701691298, progress=KafkaProgress [partitionIdToOffset=7_32115547]], partition commit info:[partitionId=701691159, version=629502, versionTime=1744281481873, isDoubleWrite=false,] successfully
可以看到上面的任务主要耗时在写入阶段,write cost: 6750ms,可以分析 grafana 模版中的 BE LOAD 模块监控,如果队列有被打满,可能是因为写入比较慢,需要调整相应的参数
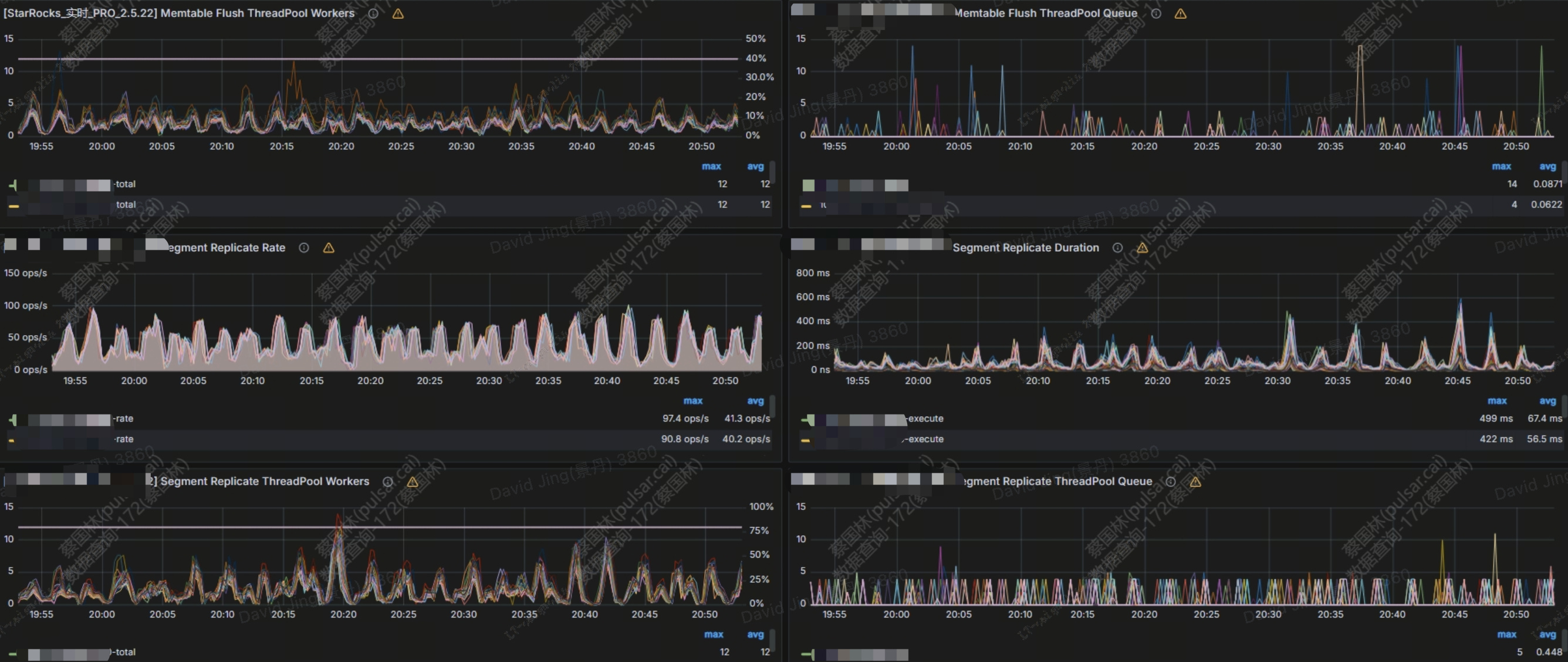
如上图,replica 线程池 20:20 左右被打满,可以调大对应的 flush 线程数

常见 case2 主键模型 publish 比较慢
由于 build index 耗时比较长导致主键模型 publish 比较慢
grep "build persistent index finish tablet" be.INFO|grep -E 'time: [0-9]{4,}ms'
当前在优化中,可以尝试关闭 skip_pk_preload = true(be.conf)
3.5 物化视图刷新失败
PromSQL
increase(starrocks_fe_mv_refresh_total_failed_jobs[5m]) > 0
报警描述
最近 5 分钟新增物化视图刷新失败次数超过 1 时发送报警。
处理办法
- 失败的是哪些物化视图
select TABLE_NAME,IS_ACTIVE,INACTIVE_REASON,TASK_NAME from information_schema.materialized_views where LAST_REFRESH_STATE !=" SUCCESS"
- 可先尝试手动刷新一次
REFRESH MATERIALIZED VIEW ${mv_name};
- 如果物化视图状态为 INACTIVE,可通过如下方式尝试置为 ACTIVE
ALTER MATERIALIZED VIEW ${mv_name} ACTIVE;
- 排查失败的原因
SELECT * FROM information_schema.task_runs WHERE task_name ='mv-112517' \G
3.6 Schema change 失败
PromSQL
increase(starrocks_be_engine_requests_total{job="$job",type="schema_change", status="failed"}[1m]) > 1
报警描述
当最近一分钟失败的 Schema Change 任务个数超过 1 时发送报警。
处理方法:
先排查以下命令返回的字段 Msg 是否有对应的对应的报错信息
show alter column from $db;
如果没有,则在 leader fe日志中搜索上一步返回的 JobId 上下文
3.6.1 schema change 内存不足
可在对应时间节点的 be.WARNING 日志中搜索是否存在 failed to process the version、failed to process the schema change. from tablet 、 Memory of schema change task exceed limit信息,确认上下文,查看 fail to execute schema change:
内存超限错误日志为: fail to execute schema change: Memory of schema change task exceed limit. DirectSchemaChange Used: 2149621304, Limit: 2147483648. You can change the limit by modify BE config [memory_limitation_per_thread_for_schema_change]

这个报错是由于单次 schema change 使用的内存超过了默认的内存限制 2G 引起的,该默认值是由以下 be 参数控制的。
修改方式
update information_schema.be_configs set value=8 where name="memory_limitation_per_thread_for_schema_change";
3.6.2 Schema change 超时
Schema change的实现是创建一堆新的tablet,然后将原来的数据重写
Create replicas failed. Error: Error replicas:21539953=99583471, 21539953=99583467, 21539953=99599851
调大创建 tablet 的超时时间
admin set frontend config ("tablet_create_timeout_second"="60"); #默认10
调大创建 tablet 的线程数
update information_schema.be_configs set value=6 where name="alter_tablet_worker_count";
3.6.3 tablet 有不 normal 的副本
可在 be.WARNING 日志中搜索是否存在 tablet is not normal 信息。
在编辑器页面输入 show proc '/statistic' 可以看到集群级别的 UnhealthyTabletNum 信息
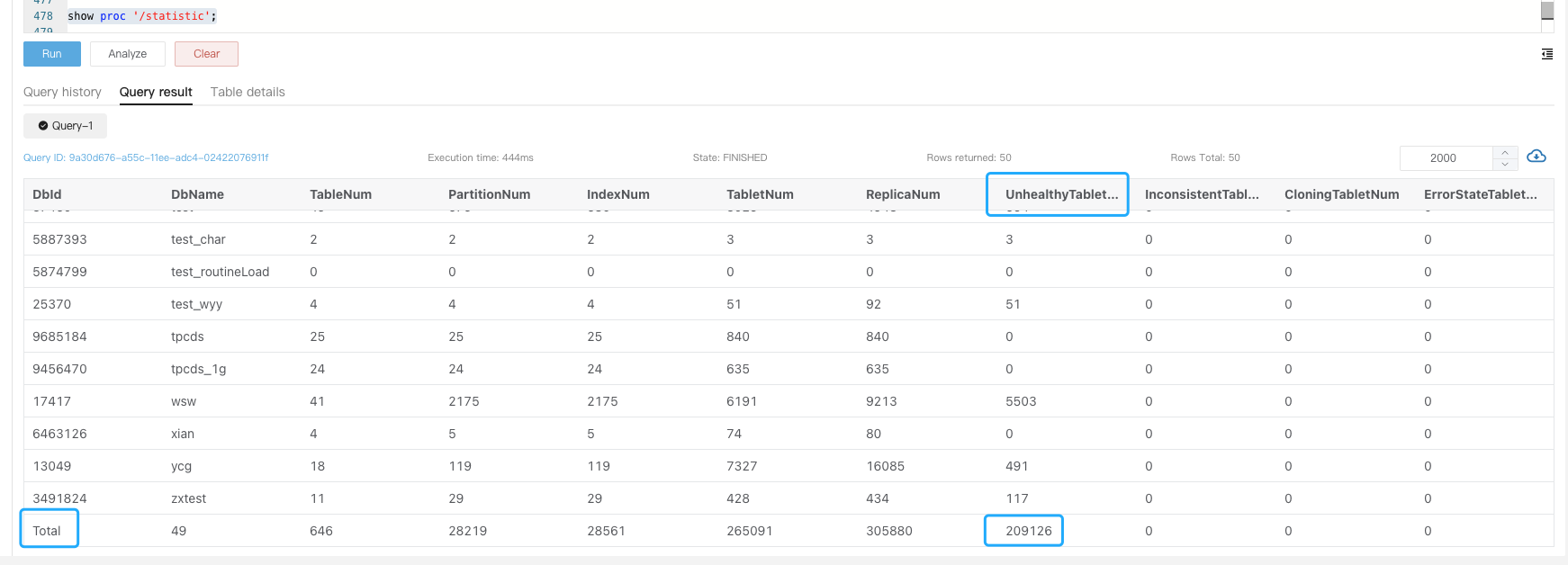
可以进一步输入 show proc ‘/statistic/Dbid’ 看到指定 DB 内的不健康副本数
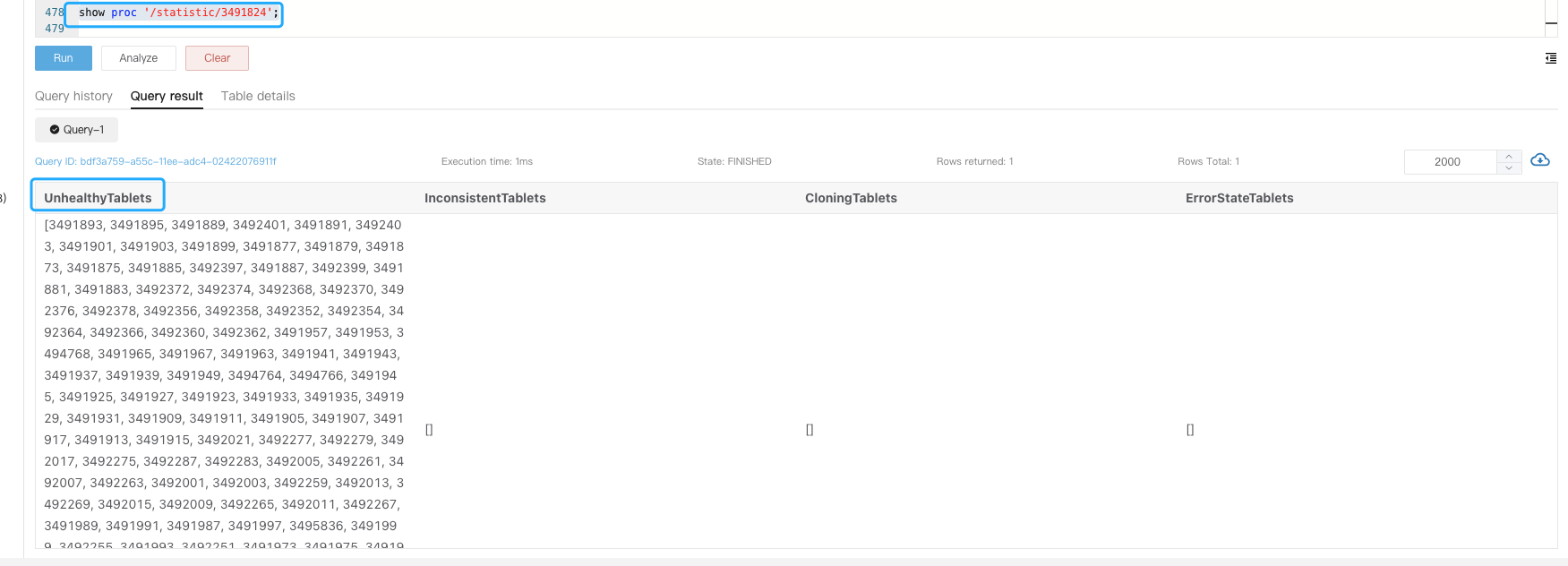
进一步可通过 show tablet tabletid 查看对应表信息
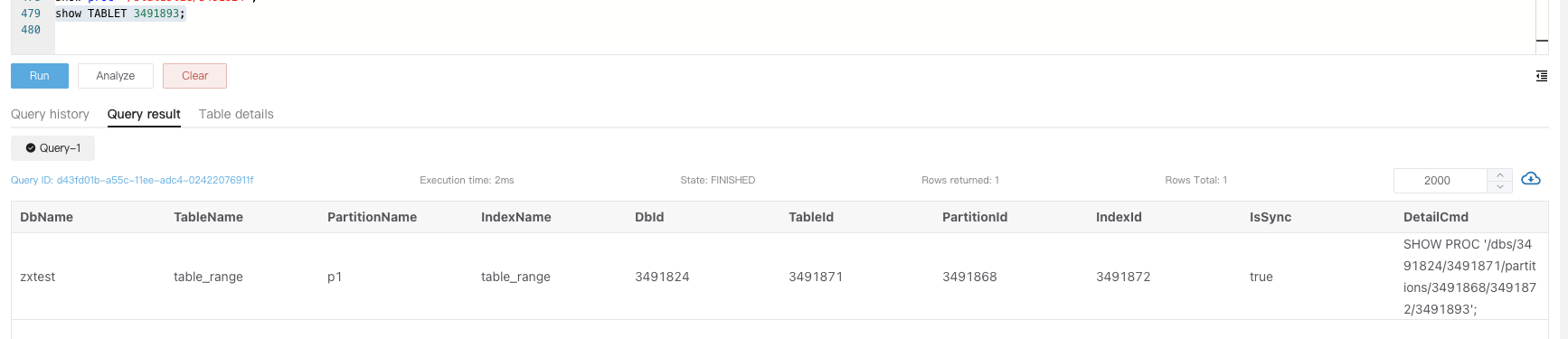
执行 DetailCmd 里面的内容来确认不健康的原因

一般来讲不健康以及不一致副本和高频导入有关,可以检查该表是否有大量实时写入,这种不健康或者不一致跟3副本写入进度不同步有关,在降低频率或者短暂停掉服务后会降下去,可以再重试该任务。
紧急处理:
- 任务失败后需要通过上述的方式去排查后重试。
- 线上环境是严格要求配置成3副本的,如果存在有1个tablet是不 normal 的副本,可以执行强制设置成 bad 的命令(前提是保证三副本,只有一个副本损坏)
「轻松赚积分」
参与方式:
- 单篇文章完成:
 点赞 +转发(技术群or朋友圈)+
点赞 +转发(技术群or朋友圈)+  在看(需全部完成)
在看(需全部完成) - 将 完整截图 发送至 StarRocks 公众号后台(有效截图参考下方)
积分规则
- 每篇符合要求的文章可获得20积分
- 同一用户每日上限5篇(即100积分/日)
- 工作人员将在3个工作日内审核发放
重要说明:
- 活动期限:即日起至2025年12月31日
- 严禁刷量行为(如短时间集中转发相同内容)
- 最终解释权归社区所有
积分商城注册操作详情:https://mp.weixin.qq.com/s/61WKxjHiB-pIwdItbRPnPA
积分商城一览: