
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】运行 SQL,从 iceberg 表跑数,写数进另一个 iceberg 表,显示运行成功,实际数据大量缺失
【背景】产出数据结果正常应该是300w量级,实际时常丢失 50w-150w 左右数据,非必现;相同 SQL (使用 trino 语法)通过 trino 产出一切正常
【业务影响】数据部分缺失
【是否存算分离】是
【StarRocks版本】例如:3.4.2
【集群规模】例如:3fe(1 follower+2observer)+40cn
【机器信息】CPU虚拟核/内存/网卡,例如:8C/60G/万兆
【联系方式】xlrei@163.com
【附件】
- fe.log/beINFO/相应截图
fe.log (535.4 KB)
- 慢查询:
- Profile信息
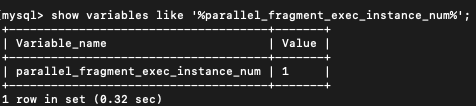
profile.txt (41.0 KB) - 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
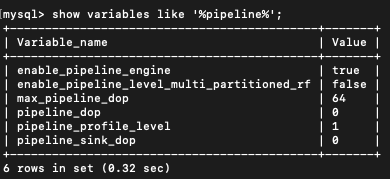
- pipeline是否开启:show variables like ‘%pipeline%’;
- Profile信息
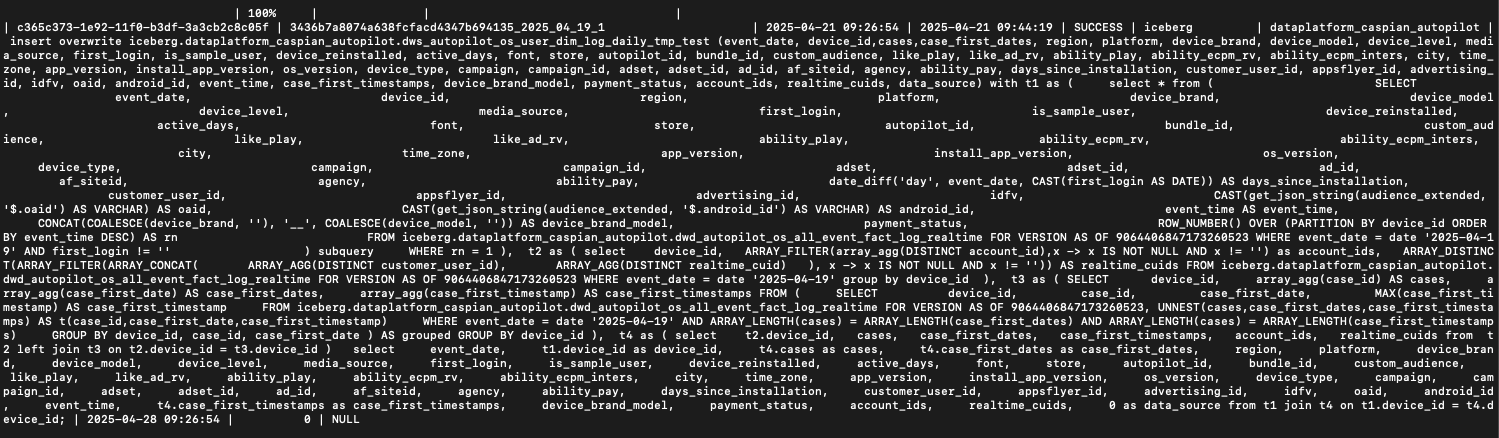
PS:这个出问题的 SQL 在 3.4.0 版本运行会直接报错,排查发现是这段子 SQL 的问题:
SELECT device_id, case_id, case_first_date, MAX(case_first_timestamp) AS case_first_timestamp FROM iceberg.dataplatform_caspian_autopilot.dwd_autopilot_os_all_event_fact_log_realtime FOR VERSION AS OF 9064406847173260523, UNNEST(cases,case_first_dates,case_first_timestamps) AS t(case_id,case_first_date,case_first_timestamp) WHERE event_date = date ‘2025-04-19’ AND ARRAY_LENGTH(cases) = ARRAY_LENGTH(case_first_dates) AND ARRAY_LENGTH(cases) = ARRAY_LENGTH(case_first_timestamps) GROUP BY device_id, case_id, case_first_date
必报错误信息:
ERROR 5025 (HY000): FileReader::get_next failed. reason = Internal error: DictDecoder GetBatchWithDict failed
be/src/formats/parquet/stored_column_reader.cpp:338 _read_values_on_levels(num_values, content_type, dst, false)
be/src/formats/parquet/complex_column_reader.cpp:81 _element_reader->read_range(range, filter, child_column)
be/src/formats/parquet/group_reader.cpp:275 _column_readers[slot_id]->read_range(range, filter, (*chunk)->get_column_by_slot_id(slot_id))
be/src/formats/parquet/group_reader.cpp:242 _read_range(_lazy