为了更快的定位您的问题,请提供以下信息,谢谢
【详述】存算分离集群上,接入了 iceberg catalog(使用 aws glue),数据比较多,在 starrocks dbt 场景下查询 iceberg.INFORMATION_SCHEMA.columns 表查不动,查看元数据 columns 表没有索引
【背景】select * from iceberg.INFORMATION_SCHEMA.columns where TABLE_SCHEMA=‘xxxx’ and table_name=‘xxxxxxxxx’ 查询耗时长
select TABLE_CATALOG,count(1) from iceberg.INFORMATION_SCHEMA.columns group by TABLE_CATALOG 查询失败
【业务影响】查询耗时过长或者失败
【是否存算分离】
【StarRocks版本】例如:3.4.0
【集群规模】例如:3fe(1 follower+2observer)+20cn(fe与cn混部)
【机器信息】CPU虚拟核/内存/网卡,例如:7C/60G/万兆
【联系方式】xlrei@163.com
【附件】
- fe.log/beINFO/相应截图
- 慢查询:
-
Profile信息
查询耗时过长
ea17f8bd-fe21-11ef-9b3b-3e0bec17c82cprofile.txt (7.0 KB)
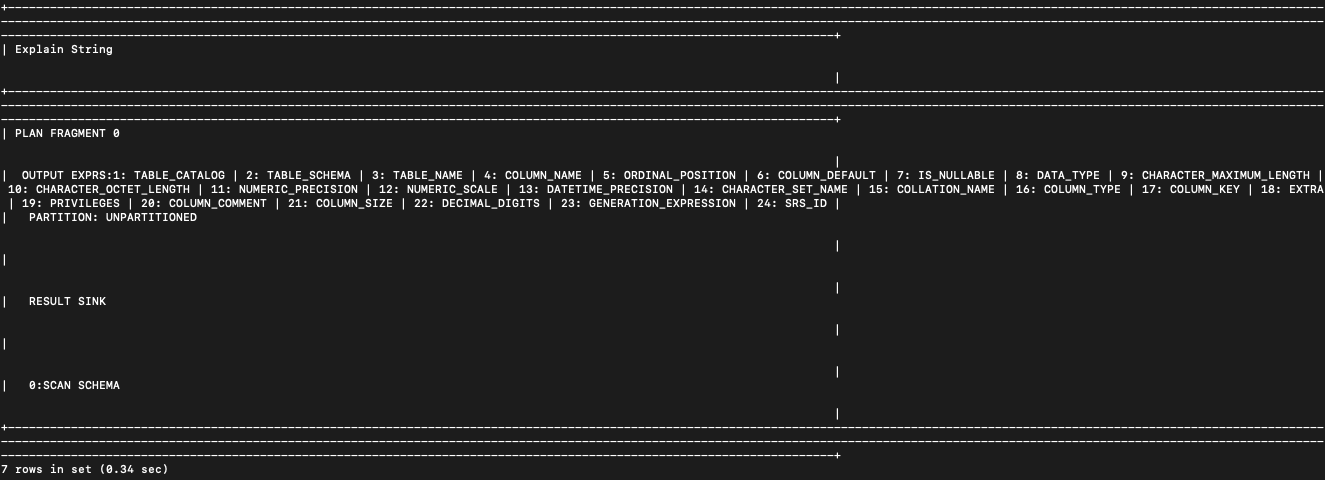
对应执行计划
查询失败(count(1))
3bdfdfd4-fe24-11ef-9b3b-3e0bec17c82cprofile.txt (14.3 KB) -
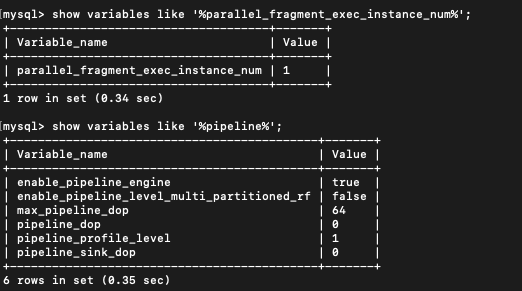
并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
-
pipeline是否开启:show variables like ‘%pipeline%’;
-