为了更快的定位您的问题,请提供以下信息,谢谢
【详述】问题详细描述
【背景】做过哪些操作?
查询 task_runs:
SELECT TASK_NAME,STATE,ERROR_MESSAGE AS ERR_MSG FROM default_catalog.information_schema.task_runs where task_name=‘79d9161dd9c28e08c25fff22f6d24833_2025_02_16_1’;
当前 new_planner_optimize_timeout 设置的 300000(300s), default_catalog.information_schema.task_runs 总条数为 2448 条,并不算多,为何执行计划需要耗时如此之久?
【业务影响】查询计划超时
【是否存算分离】是
【StarRocks版本】例如:3.3.5
【集群规模】例如:3fe(1 follower+2observer)+35cn(fe与cn混部)
【机器信息】CN 节点 CPU虚拟核/内存/网卡,例如:8C/60G/万兆
【联系方式】xlrei@163.com
【附件】
- fe.log/beINFO/相应截图
- 慢查询:
- Profile信息
- 并行度:show variables like ‘%parallel_fragment_exec_instance_num%’;
±------------------------------------±------+
| Variable_name | Value |
±------------------------------------±------+
| parallel_fragment_exec_instance_num | 1 |
±------------------------------------±------+ - pipeline是否开启:show variables like ‘%pipeline%’;
±-------------------------------------------±------+
| Variable_name | Value |
±-------------------------------------------±------+
| enable_pipeline_engine | true |
| enable_pipeline_level_multi_partitioned_rf | false |
| max_pipeline_dop | 64 |
| pipeline_dop | 0 |
| pipeline_profile_level | 1 |
| pipeline_sink_dop | 0 |
±-------------------------------------------±------+
执行计划:
explain SELECT TASK_NAME,STATE,ERROR_MESSAGE AS ERR_MSG FROM default_catalog.information_schema.task_runs where task_name=‘79d9161dd9c28e08c25fff22f6d24833_2025_02_16_1’;
±----------------------------------------------------------------------------+
| Explain String |
±----------------------------------------------------------------------------+
| EXECUTE IN FE |
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:2: TASK_NAME | 5: STATE | 11: ERROR_MESSAGE |
| PARTITION: UNPARTITIONED |
| |
| RESULT SINK |
| |
| 0:UNION |
| constant exprs: |
| ‘79d9161dd9c28e08c25fff22f6d24833_2025_02_16_1’ | ‘SUCCESS’ | NULL |
±----------------------------------------------------------------------------+
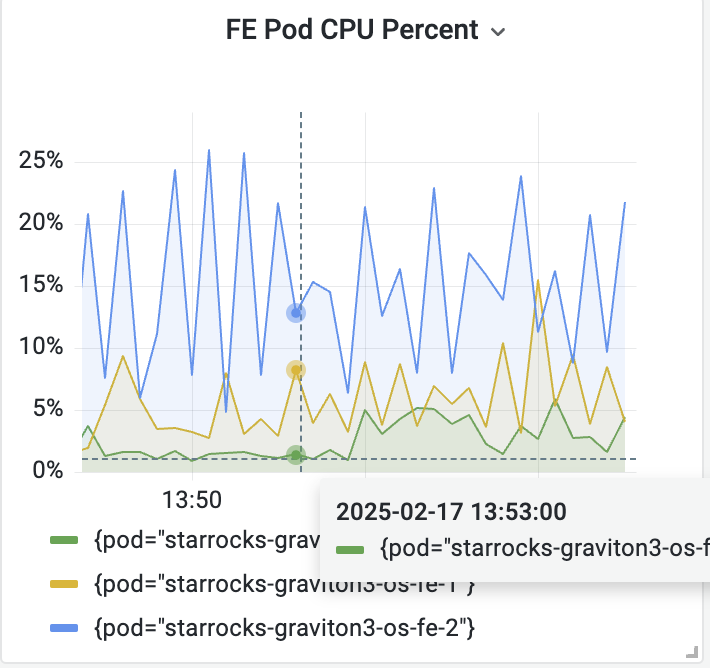
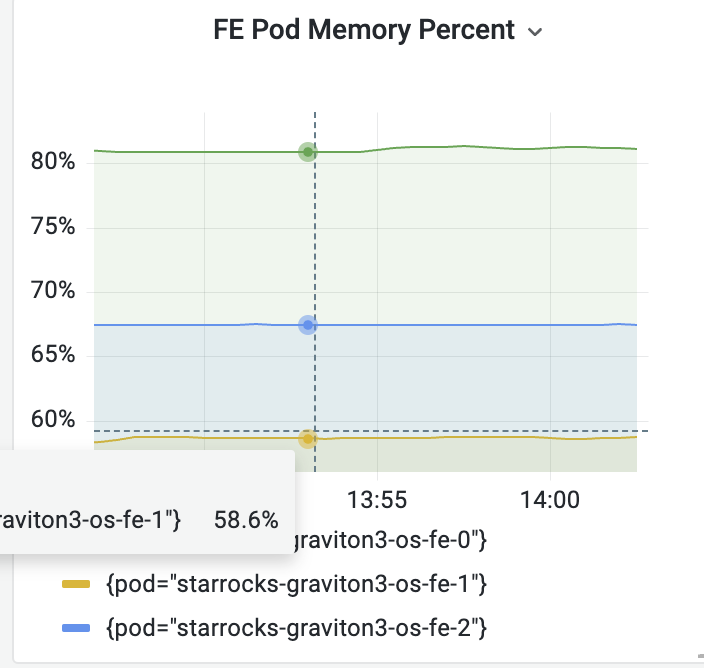
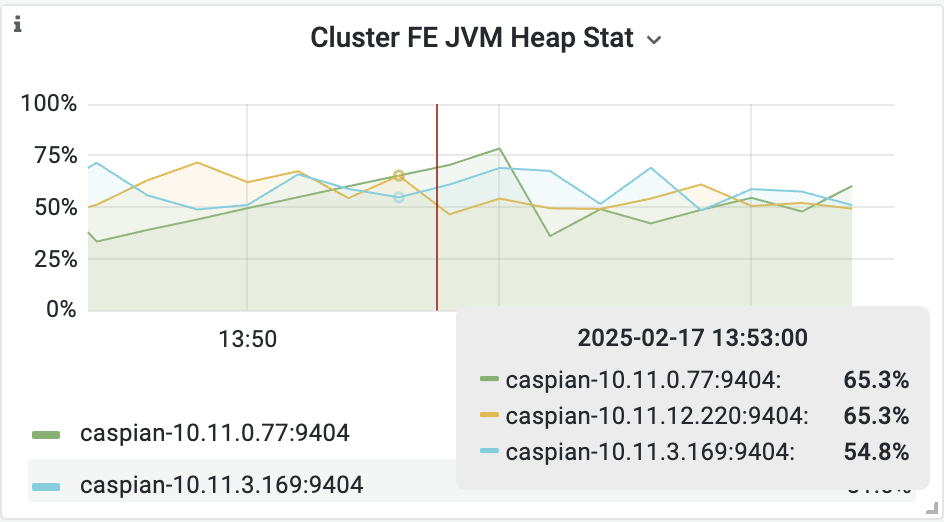
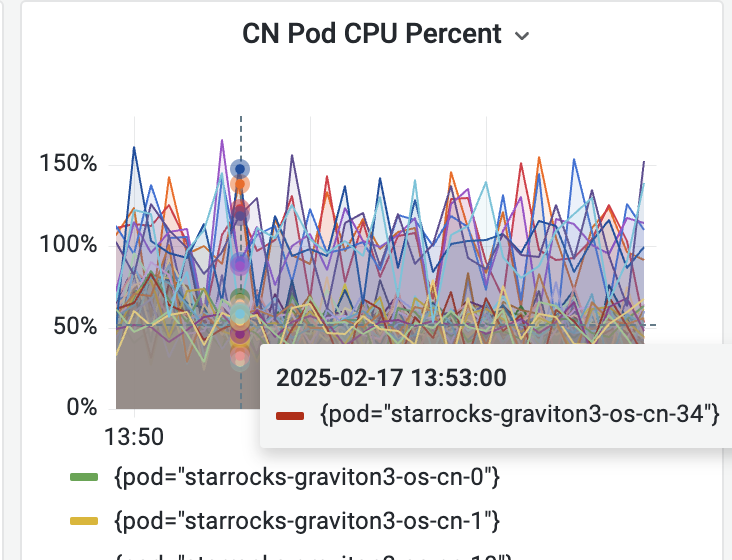
- cn节点cpu和内存使用率截图
- 查询报错:
[2025-02-17T13:53:03.043+0000] {pod_manager.py:367} INFO - Query execution timed out or an error occurred: 1064 (HY000): StarRocks planner use long time 300000 ms in logical phase, This probably because 1. FE Full GC, 2. Hive external table fetch metadata took a long time, 3. The SQL is very complex. You could 1. adjust FE JVM config, 2. try query again, 3. enlarge new_planner_optimize_timeout session variable