
【详述】
收到业务方反馈,说很多查询无法返回结果。fe.warn.log 中有大量的 kill query timeout 警告。执行 show processlist 有60多个查询一直堵在那儿,包括很简单的 select 1 语句。由于这是第二次出现同样问题,于是直接重启了 be、fe 得到解决(先重启的 be,问题仍存在;重启 fe 后警告消失,恢复正常)。
【背景】集群一直在运行,所在 EC2 未出现底层故障,starrocks 也未挂掉或重启。
【业务影响】查询无法返回结果。
【是否存算分离】否,存算一体。
【StarRocks版本】ARM 3.3.5
【集群规模】1 * fe(4c 16g) + 1 * be(4c 32g)
【机器信息】fe aws m7g.xlarge,be aws r7g.xlarge
【联系方式】StarRocks-存算分离2群 飞速土豆
【附件】
以下是最早出现警告信息的时间
2025-02-11 02:38:33.275Z WARN (Connect-Scheduler-Check-Timer-0|12) [ConnectContext.checkTimeout():936] kill query timeout, remote: 10.85.130.95:58144, query timeout: 300, query id: 962bdfff-e820-11ef-a3a9-02732c344fe1
从 EC2 监控看,BE 节点 CPU 指标有点异常。
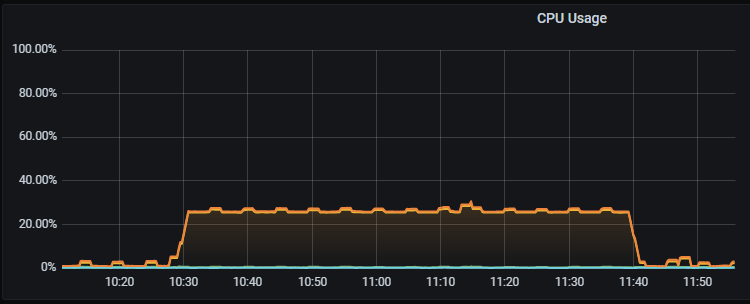
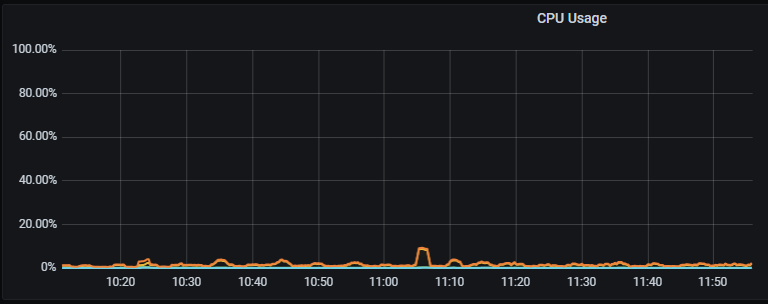
FE 节点 CPU 指标正常
通过对 fe.warn.log 进行统计,发现 kill query timeout 只有4条 SQL 出现,次数都较多。从 2025-02-11 02:38:33.275Z 开始至 2025-02-11 04:12:00.275Z 重启 fe 后结束。
sorted_sql.txt (16.9 KB)
除此之外,未能在 fe、be 的日志中找到更多的信息。
