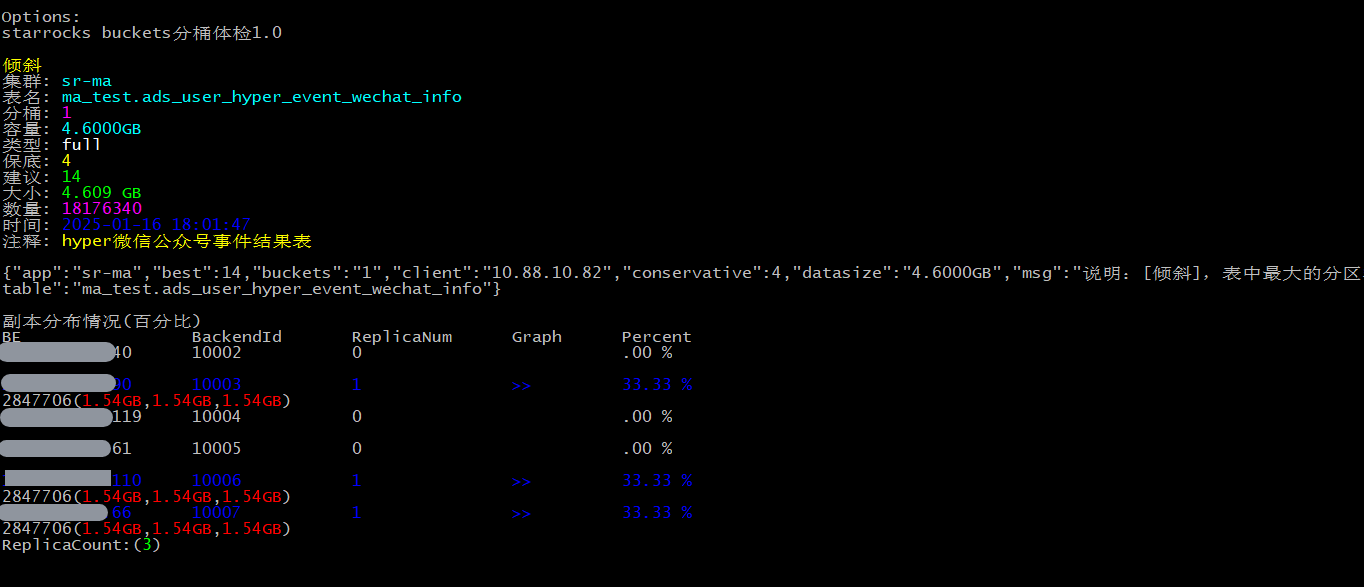
这个工具的产生主要是为了解决一些库表出现分桶倾斜(分桶大了,或者小了)。我们生产的表正常在3w左右,所以当用户建表时,没有按照规范进行分配bucket,可能后期就会出现分桶倾斜。
Usage: setbuckets [-s adhoc] [-h]
Options:
StarRocks Buckets分桶修复工具
-a 启用自动模式匹配表最佳分桶,完成覆盖
-b int
buckets
-c 重建表时可以指定是否过滤空分区
-h show help information
-id string
根据backendId1,根据backendId2...展示节点内存储的分片信息
-l 展示排序键信息
-m string
execution method: create,insert,alter,drop (default "create,insert,alter,drop")
-n int
按单个Tablet容量进行切割/MB
-s string
starrocks:adhoc|app|scct|cdp|api|dmp|emr(企业版),emrc(社区版)|qa
-sk string
splitkey1,splitkey2..., 重建表时可以重新指定分桶键
-t string
schema.tablename
-thread int
当启用自动模式匹配表最佳分桶,-t填写多个表名时,可触发并行模式 (default 3)
预览模式
一、可以很直观的看到某个集群下,某个表最大的分桶top1是4.6000GB,而数据量是18176340,还有创建时间和表注释。
二、也可以看到每个机器下,存放了多少个tablet,以及每个tablet的大小。也可以使用-id指定backendid,查看这个表固定的be节点下的tablet分布情况。

三、排序键筛选功能,能解析DUPLICATE KEY和DISTRIBUTED BY HASH中的字段,进行count 1000去重,从而判断分桶列和排序键是否合理,是否属于低基数。

设置模式
一、调整分桶
使用-b参数指定需要调整后的分桶数
直接一步到位,3700w,9秒。
setbuckets -s <集群名称> -t <库名.表名> -b <分桶数>
____ _ ____ _
/ ___|| |_ __ _ _ __| _ \ ___ ___| | _____
\___ \| __/ __ | ___| |_) / _ \ / __| |/ / __|
___) | || (_| | | | _ < (_) | (__| <\__ \
|____/ \__\____|_| |_| \_\___/ \___|_|\_\___/
setbuckets v1.0.4
md5sum @cac91b522563082752afc4b087a6b017
author @xxxxx
system @xxxxx
update @2025-01-23 16:00:47
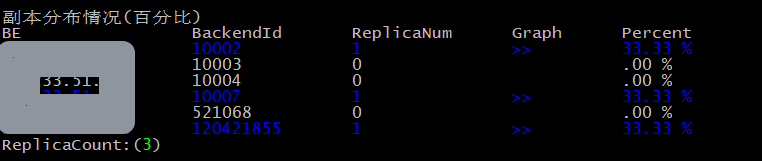
副本分布情况(百分比)
BE BackendId ReplicaNum Graph Percent
************* 10002 1 >> 33.33 %
************* 10003 0 .00 %
************* 10004 0 .00 %
************* 10007 1 >> 33.33 %
************* 521068 0 .00 %
************* 120421855 1 >> 33.33 %
ReplicaCount:(3)
2025-02-11T16:16:26.326+0800 info service/ScanSchemaSetBuckets.go:61 原始SQL:
CREATE TABLE `ads_user_sams_member_action_tag_info` (
`member_nbr` varchar(200) NULL COMMENT "17位会员号",
`channel` int(11) NULL COMMENT "行为渠道(0:app,1:小程序)",
`earliest_login_date` varchar(200) NULL COMMENT "自23年以来用户最早登录的日期",
`last_login_date` varchar(200) NULL COMMENT "自23年以来用户最近登录的日期",
`etl_load_time` varchar(200) NULL COMMENT "etl处理时间",
`etl_owner` varchar(200) NULL COMMENT "etl责任人",
`device_system` varchar(200) NULL COMMENT "操作设备系统",
`device_brand` varchar(200) NULL COMMENT "手机品牌",
`last_login_app_version` varchar(200) NULL COMMENT "自23年以来用户最近登录的APP版本"
) ENGINE=OLAP
DUPLICATE KEY(`member_nbr`)
COMMENT "Sams会员用户行为标签表"
DISTRIBUTED BY HASH(`member_nbr`) BUCKETS 1
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"compression" = "LZ4"
);
2025-02-11T16:16:26.326+0800 info service/ScanSchemaSetBuckets.go:150 原始BUCKETS:[ BUCKETS 1 ], length:11
2025-02-11T16:16:26.326+0800 info service/ScanSchemaSetBuckets.go:157 o:[ BUCKETS 1 ],n:[ BUCKETS 5]
2025-02-11T16:16:26.327+0800 info service/ScanSchemaSetBuckets.go:165 重构后表名过长,进行裁剪:原表名:ads_user_sams_member_action_tag_info,新表名:buckets_1739261786327_ads_user
2025-02-11T16:16:26.327+0800 info service/ScanSchemaSetBuckets.go:170 新生SQL:
use ma_test;create table if not exists `buckets_1739261786327_ads_user` (
`member_nbr` varchar(200) NULL COMMENT "17位会员号",
`channel` int(11) NULL COMMENT "行为渠道(0:app,1:小程序)",
`earliest_login_date` varchar(200) NULL COMMENT "自23年以来用户最早登录的日期",
`last_login_date` varchar(200) NULL COMMENT "自23年以来用户最近登录的日期",
`etl_load_time` varchar(200) NULL COMMENT "etl处理时间",
`etl_owner` varchar(200) NULL COMMENT "etl责任人",
`device_system` varchar(200) NULL COMMENT "操作设备系统",
`device_brand` varchar(200) NULL COMMENT "手机品牌",
`last_login_app_version` varchar(200) NULL COMMENT "自23年以来用户最近登录的APP版本"
) ENGINE=OLAP
DUPLICATE KEY(`member_nbr`)
COMMENT "Sams会员用户行为标签表"
DISTRIBUTED BY HASH(`member_nbr`) BUCKETS 5
PROPERTIES (
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"compression" = "LZ4"
);
2025-02-11T16:16:26.327+0800 info service/ScanSchemaSetBuckets.go:172 新生SQL执行中, 此过程会根据创建分区的多少, 耗费一定的时间...
2025-02-11T16:16:27.374+0800 info service/ScanSchemaSetBuckets.go:189 建表完成: ma_test.buckets_1739261786327_ads_user
2025-02-11T16:16:27.374+0800 info service/ScanSchemaSetBuckets.go:198 select count(*) as count from ma_test.ads_user_sams_member_action_tag_info
2025-02-11T16:16:27.482+0800 info service/ScanSchemaSetBuckets.go:237 submit /*+set_var(query_timeout=7200,pipeline_dop=0,exec_mem_limit=214748364800)*/ task setbuckets_culgemudrqp8kk75b2sg_1739261787482065 as insert into ma_test.buckets_1739261786327_ads_user select * from ma_test.ads_user_sams_member_action_tag_info
2025-02-11 16:16:28 RUNNING 0% ma_test.buckets_1739261786327_ads_user
2025-02-11T16:16:50.968+0800 info service/ScanSchemaSetBuckets.go:279 insert into done!
2025-02-11T16:16:50.968+0800 info service/ScanSchemaSetBuckets.go:282 __End__Data_Finished[buckets_1739261786327_ads_user] (37550635.00/37550635.00)##################################################100%
2025-02-11T16:16:50.968+0800 info service/ScanSchemaSetBuckets.go:283 数据写入成功
计算两端数据量
[37550635]: ma_test.buckets_1739261786327_ads_user
[37550635]: ma_test.ads_user_sams_member_action_tag_info
2025-02-11T16:16:51.037+0800 info service/ScanSchemaSetBuckets.go:296 开始交换表名
2025-02-11T16:16:51.037+0800 info service/ScanSchemaSetBuckets.go:298 use ma_test;alter table ads_user_sams_member_action_tag_info rename buckets_swap_bts_1739261811
2025-02-11T16:16:51.123+0800 info service/ScanSchemaSetBuckets.go:305 use ma_test;alter table buckets_1739261786327_ads_user rename ads_user_sams_member_action_tag_info
2025-02-11T16:16:51.127+0800 info service/ScanSchemaSetBuckets.go:311 数据交互完成, 分桶修改完成!
2025-02-11T16:16:51.127+0800 info service/ScanSchemaSetBuckets.go:316 删除旧表
2025-02-11T16:16:51.127+0800 info service/ScanSchemaSetBuckets.go:318 drop table ma_test.buckets_swap_bts_1739261811
2025-02-11T16:16:51.161+0800 info service/ScanSchemaSetBuckets.go:324 删除成功!
2025-02-11T16:16:51.161+0800 info service/ScanSchemaSetBuckets.go:325 完成整改: ma_test.ads_user_sams_member_action_tag_info
2025-02-11T16:16:51.162+0800 info service/ScanSchemaSetBuckets.go:32 [ma_test.ads_user_sams_member_action_tag_info]耗时: 24.875629443s
副本分布情况(百分比)
BE BackendId ReplicaNum Graph Percent
************* 10002 2 > 13.33 %
************* 10003 3 >> 20.00 %
************* 10004 2 > 13.33 %
************* 10007 2 > 13.33 %
************* 521068 3 >> 20.00 %
************* 120421855 3 >> 20.00 %
ReplicaCount:(15)
2025-02-11T16:16:51.179+0800 info service/main.go:17 done.
为避免有些用户不合理的设置参数,代码里内嵌了过滤一些参数。

调整前:
调整后:
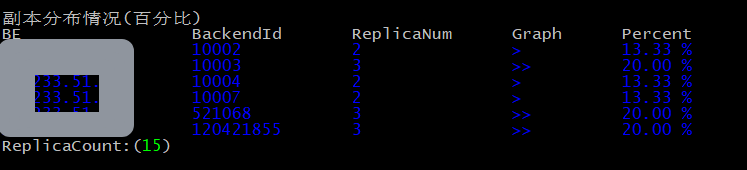
分摊均匀,更利于并发。
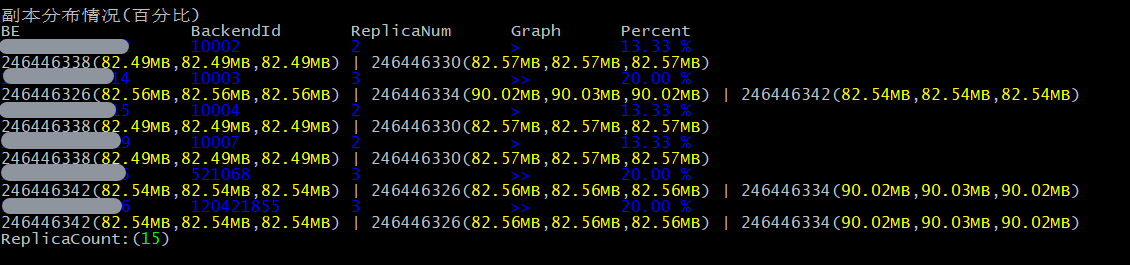
这种方式属于全局调整,直接建个新表,把旧表数据写入新表,这样对于分区表来说,就是历史数据也能打散均匀。
二、建表时,过滤空分区
使用-c参数,对于一些空分区,在新表中将不会存在,这样做的目标是减少空分区的数据,减少元数据扫描的压力。
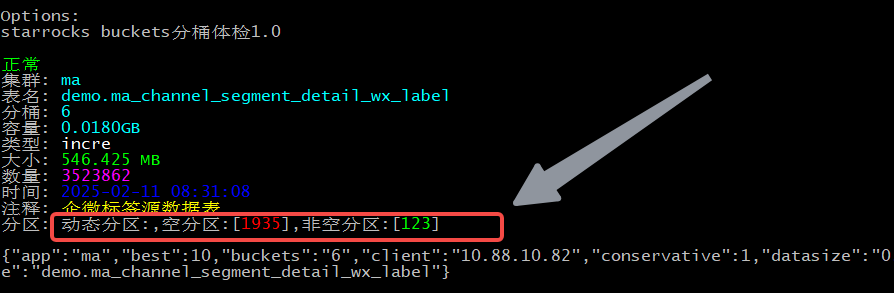
那么使用-c指定清理空分区,保留实用分区。
setbuckets -s ma -t demo.ma_channel_segment_detail_wx_label -b 2 -c
____ _ ____ _
/ ___|| |_ __ _ _ __| _ \ ___ ___| | _____
\___ \| __/ __ | ___| |_) / _ \ / __| |/ / __|
___) | || (_| | | | _ < (_) | (__| <\__ \
|____/ \__\____|_| |_| \_\___/ \___|_|\_\___/
setbuckets v1.0.4
md5sum @cac91b522563082752afc4b087a6b017
author @***
system @***
update @2025-01-23 16:00:47
副本分布情况(百分比)
BE BackendId ReplicaNum Graph Percent
************* 10002 6174 > 16.67 %
************* 10003 6174 > 16.67 %
************* 10004 6174 > 16.67 %
************* 10007 6174 > 16.67 %
************* 521068 6174 > 16.67 %
************* 120421855 6174 > 16.67 %
ReplicaCount:(37044)
2025-02-11T16:34:26.756+0800 info service/ScanSchemaSetBuckets.go:61 原始SQL:
CREATE TABLE `ma_channel_segment_detail_wx_label` (
`channel_type` varchar(20) NOT NULL COMMENT "渠道类型,10流程画布,20短信营销,30App Push,40App 发券,50App 站内信,60人货匹配,70企微标签推送,80SNG上券,90WMDJ发券,100WMDJ用户推送",
`brand_type` int(11) NOT NULL COMMENT "业态,0hyper,1山姆",
`channel_id` bigint(20) NULL COMMENT "各单渠道自增的id,对于流程画布就是campaign_version_id",
`campaign_config_id` bigint(20) NULL COMMENT "本次营销所属的流程画布ID。其他单渠道为null",
`node_id` varchar(128) NULL COMMENT "当为流程画布时,为画布中对应的节点id.其他单渠道为null",
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT "创建时间",
`qw_unionid` varchar(200) NULL COMMENT "企微unionid",
`member_nbr` varchar(200) NULL COMMENT "17位会员卡号",
`user_id` varchar(50) NULL COMMENT "用户标识oneid",
`friend_union_id` varchar(200) NULL COMMENT "sams企微union_id"
) ENGINE=OLAP
DUPLICATE KEY(`channel_type`, `brand_type`, `channel_id`)
COMMENT "企微标签源数据表"
PARTITION BY RANGE(`channel_id`)
(PARTITION p1 VALUES [("1"), ("2")),
PARTITION p5406 VALUES [("5406"), ("5407")),
PARTITION p5498 VALUES [("5498"), ("5499")),
PARTITION p5520 VALUES [("5520"), ("5521")),
PARTITION p5539 VALUES [("5539"), ("5540")),
...
PARTITION p5550 VALUES [("5550"), ("5551")),
PARTITION p5554 VALUES [("5554"), ("5555")),
PARTITION p5556 VALUES [("5556"), ("5557")),
PARTITION p1015520047 VALUES [("1015520047"), ("1015520048")))
DISTRIBUTED BY HASH(`qw_unionid`) BUCKETS 6
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"compression" = "LZ4"
);
2025-02-11T16:34:26.872+0800 info service/ScanSchemaPartition.go:48 [1935]空历史分区,[123]非空分区
2025-02-11T16:34:27.066+0800 info service/ScanSchemaSetBuckets.go:70 去除空分区后SQL:
CREATE TABLE `ma_channel_segment_detail_wx_label` (
`channel_type` varchar(20) NOT NULL COMMENT "渠道类型,10流程画布,20短信营销,30App Push,40App 发券,50App 站内信,60人货匹配,70企微标签推送,80SNG上券,90WMDJ发券,100WMDJ用户推送",
`brand_type` int(11) NOT NULL COMMENT "业态,0hyper,1山姆",
`channel_id` bigint(20) NULL COMMENT "各单渠道自增的id,对于流程画布就是campaign_version_id",
`campaign_config_id` bigint(20) NULL COMMENT "本次营销所属的流程画布ID。其他单渠道为null",
`node_id` varchar(128) NULL COMMENT "当为流程画布时,为画布中对应的节点id.其他单渠道为null",
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT "创建时间",
`qw_unionid` varchar(200) NULL COMMENT "企微unionid",
`member_nbr` varchar(200) NULL COMMENT "17位会员卡号",
`user_id` varchar(50) NULL COMMENT "用户标识oneid",
`friend_union_id` varchar(200) NULL COMMENT "sams企微union_id"
) ENGINE=OLAP
DUPLICATE KEY(`channel_type`, `brand_type`, `channel_id`)
COMMENT "企微标签源数据表"
PARTITION BY RANGE(`channel_id`)
(PARTITION p10264404 VALUES [("10264404"), ("10264405")),
PARTITION p10264405 VALUES [("10264405"), ("10264406")),
...
PARTITION p102683322 VALUES [("102683322"), ("102683323")),
PARTITION p102683364 VALUES [("102683364"), ("102683365")),
PARTITION p102683365 VALUES [("102683365"), ("102683366")),
PARTITION p102683369 VALUES [("102683369"), ("102683370")),
PARTITION p
PARTITION p1015520047 VALUES [("1015520047"), ("1015520048")))
DISTRIBUTED BY HASH(`qw_unionid`) BUCKETS 6
PROPERTIES (
"replication_num" = "3",
"in_memory" = "false",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"compression" = "LZ4"
);
2025-02-11T16:34:27.066+0800 info service/ScanSchemaSetBuckets.go:150 原始BUCKETS:[ BUCKETS 6 ], length:11
2025-02-11T16:34:27.066+0800 info service/ScanSchemaSetBuckets.go:157 o:[ BUCKETS 6 ],n:[ BUCKETS 2]
2025-02-11T16:34:27.066+0800 info service/ScanSchemaSetBuckets.go:165 重构后表名过长,进行裁剪:原表名:ma_channel_segment_detail_wx_label,新表名:buckets_1739262867066_ma_chann
2025-02-11T16:34:27.066+0800 info service/ScanSchemaSetBuckets.go:170 新生SQL:
use demo;create table if not exists `buckets_1739262867066_ma_chann` (
`channel_type` varchar(20) NOT NULL COMMENT "渠道类型,10流程画布,20短信营销,30App Push,40App 发券,50App 站内信,60人货匹配,70企微标签推送,80SNG上券,90WMDJ发券,100WMDJ用户推送",
`brand_type` int(11) NOT NULL COMMENT "业态,0hyper,1山姆",
`channel_id` bigint(20) NULL COMMENT "各单渠道自增的id,对于流程画布就是campaign_version_id",
`campaign_config_id` bigint(20) NULL COMMENT "本次营销所属的流程画布ID。其他单渠道为null",
`node_id` varchar(128) NULL COMMENT "当为流程画布时,为画布中对应的节点id.其他单渠道为null",
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT "创建时间",
`qw_unionid` varchar(200) NULL COMMENT "企微unionid",
`member_nbr` varchar(200) NULL COMMENT "17位会员卡号",
`user_id` varchar(50) NULL COMMENT "用户标识oneid",
`friend_union_id` varchar(200) NULL COMMENT "sams企微union_id"
) ENGINE=OLAP
DUPLICATE KEY(`channel_type`, `brand_type`, `channel_id`)
COMMENT "企微标签源数据表"
PARTITION BY RANGE(`channel_id`)
(PARTITION p10264404 VALUES [("10264404"), ("10264405")),
PARTITION p10264405 VALUES [("10264405"), ("10264406")),
...
PARTITION p1015520018 VALUES [("1015520018"), ("1015520019")),
PARTITION p1015520038 VALUES [("1015520038"), ("1015520039")),
PARTITION p1015520039 VALUES [("1015520039"), ("1015520040")),
PARTITION p1015520040 VALUES [("1015520040"), ("1015520041")),
PARTITION p1015520047 VALUES [("1015520047"), ("1015520048")))
DISTRIBUTED BY HASH(`qw_unionid`) BUCKETS 2
PROPERTIES (
"storage_format" = "DEFAULT",
"enable_persistent_index" = "false",
"compression" = "LZ4"
);
2025-02-11T16:34:27.067+0800 info service/ScanSchemaSetBuckets.go:172 新生SQL执行中, 此过程会根据创建分区的多少, 耗费一定的时间...
2025-02-11T16:34:27.454+0800 info service/ScanSchemaSetBuckets.go:189 建表完成: demo.buckets_1739262867066_ma_chann
2025-02-11T16:34:27.454+0800 info service/ScanSchemaSetBuckets.go:198 select count(*) as count from demo.ma_channel_segment_detail_wx_label
2025-02-11T16:34:27.485+0800 info service/ScanSchemaSetBuckets.go:237 submit /*+set_var(query_timeout=7200,pipeline_dop=0,exec_mem_limit=214748364800)*/ task setbuckets_culgn4udrqp4ka1rg41g_1739262867485052 as insert into demo.buckets_1739262867066_ma_chann select * from demo.ma_channel_segment_detail_wx_label
2025-02-11 16:34:28 RUNNING 0% demo.buckets_1739262867066_ma_chann
2025-02-11T16:34:31.496+0800 info service/ScanSchemaSetBuckets.go:279 insert into done!
2025-02-11T16:34:31.496+0800 info service/ScanSchemaSetBuckets.go:282 __End__Data_Finished[buckets_1739262867066_ma_chann] (3523862.00/3523862.00)##################################################100%
2025-02-11T16:34:31.496+0800 info service/ScanSchemaSetBuckets.go:283 数据写入成功
计算两端数据量
[3523862]: demo.buckets_1739262867066_ma_chann
[3523862]: demo.ma_channel_segment_detail_wx_label
2025-02-11T16:34:31.525+0800 info service/ScanSchemaSetBuckets.go:296 开始交换表名
2025-02-11T16:34:31.525+0800 info service/ScanSchemaSetBuckets.go:298 use demo;alter table ma_channel_segment_detail_wx_label rename buckets_swap_bts_1739262871
2025-02-11T16:34:31.529+0800 info service/ScanSchemaSetBuckets.go:305 use demo;alter table buckets_1739262867066_ma_chann rename ma_channel_segment_detail_wx_label
2025-02-11T16:34:31.533+0800 info service/ScanSchemaSetBuckets.go:311 数据交互完成, 分桶修改完成!
2025-02-11T16:34:31.533+0800 info service/ScanSchemaSetBuckets.go:316 删除旧表
2025-02-11T16:34:31.533+0800 info service/ScanSchemaSetBuckets.go:318 drop table demo.buckets_swap_bts_1739262871
2025-02-11T16:34:31.542+0800 info service/ScanSchemaSetBuckets.go:324 删除成功!
2025-02-11T16:34:31.543+0800 info service/ScanSchemaSetBuckets.go:325 完成整改: demo.ma_channel_segment_detail_wx_label
2025-02-11T16:34:31.543+0800 info service/ScanSchemaSetBuckets.go:32 [demo.ma_channel_segment_detail_wx_label]耗时: 4.81731853s
副本分布情况(百分比)
BE BackendId ReplicaNum Graph Percent
************* 10002 123 > 16.67 %
************* 10003 123 > 16.67 %
************* 10004 123 > 16.67 %
************* 10007 123 > 16.67 %
************* 521068 123 > 16.67 %
************* 120421855 123 > 16.67 %
ReplicaCount:(738)
2025-02-11T16:34:31.554+0800 info service/main.go:17 done.
这个时候 ReplicaCount:(37044) 降到了 ReplicaCount:(738),实际上总数据量没有变化。这里分桶由6调整到了2,空分区铲掉。
分区: 动态分区:,空分区:[0],非空分区:[123]
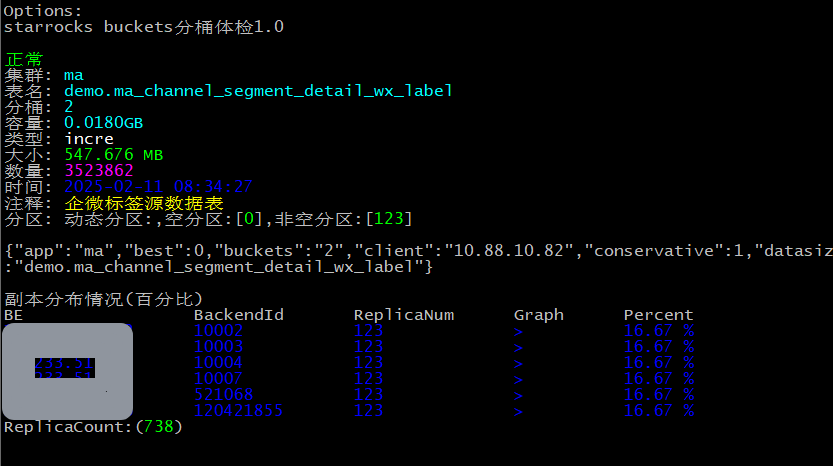
如果我有10个表需要修改,那么也不需要一次一次来,-a参数只能识别最大分区给予最佳分桶数,-t支持逗号分隔多个表名,这个时候就能多表处理,1个命令即可。
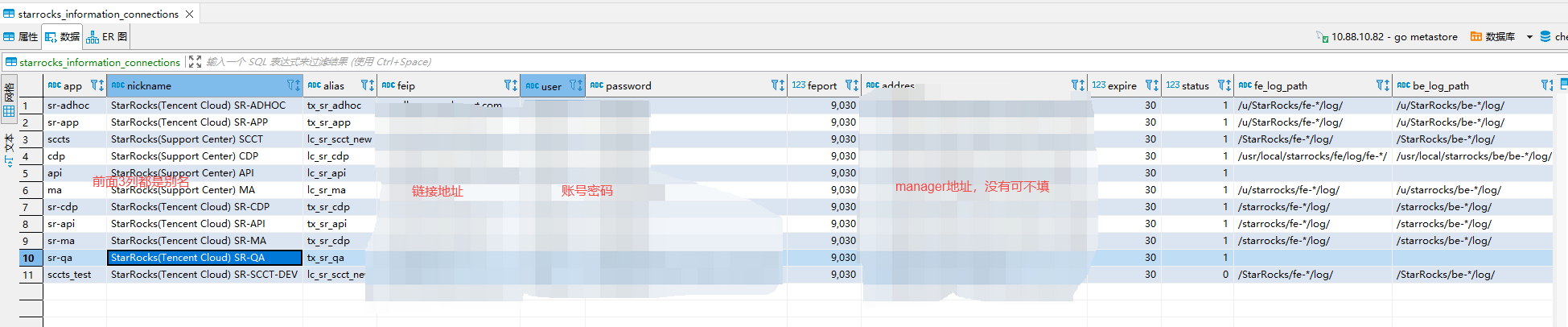
该工具依赖 【 集群连接信息表】点击 搜索
“集群连接信息表” 有相关表结构。