
为了更快的定位您的问题,请提供以下信息,谢谢
【详述】
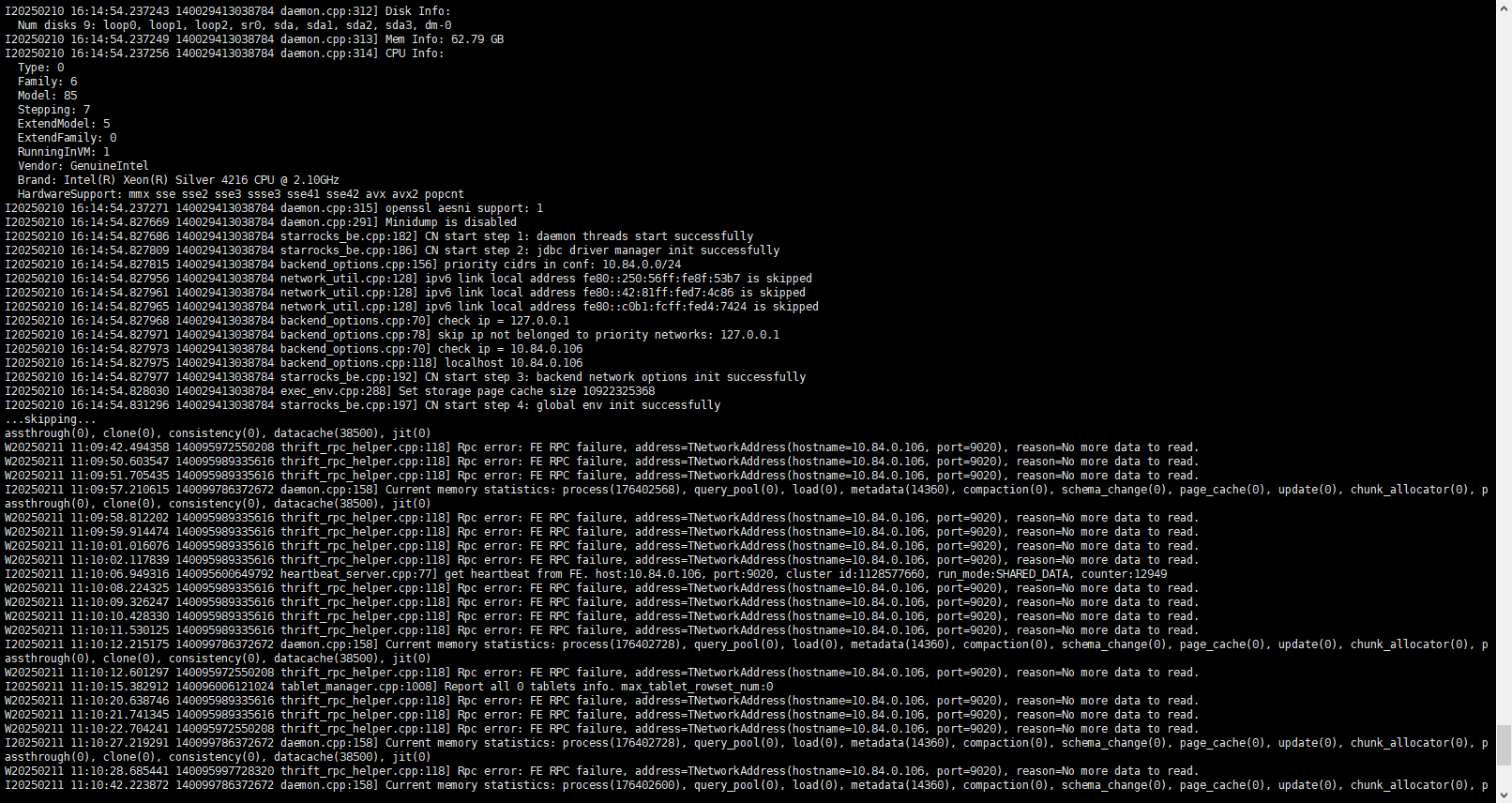
部署完 StarRocks 3.4.0 FE 正常启动 CN 启动时也没有报错信息,使用mysql客户端连接时 fe和cn的Alive 都为true,后面查看CN日志报错Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
【背景】
清理过meta 数据重新部署报错依旧还在
【是否存算分离】
是纯算分离结构
【StarRocks版本】
StarRocks版本:3.4.0
【集群规模】
1台机器 包含 1fe+1cn
【机器信息】CPU虚拟核/内存/网卡,例如:48C/64G/万兆
CPU:
CPU(s): 16
Thread(s) per core: 1
Core(s) per socket: 1
内存:
62Gi
【联系方式】
17633823064@163.com
【附件】
I20250210 16:14:54.236124 140029413038784 daemon.cpp:305] version 3.4.0-e94580b
BuildType: RELEASE
Build distributor id: ubuntu
Build arch: x86_64
Built on 2025-01-23 11:55:42 by StarRocks@localhost (Ubuntu 22.04.4 LTS)
I20250210 16:14:54.237191 140029413038784 mem_info.cpp:104] Physical Memory: 62.79 GB
I20250210 16:14:54.237212 140029413038784 daemon.cpp:311] Cpu Info:
Model: Intel® Xeon® Silver 4216 CPU @ 2.10GHz
Cores: 16
Max Possible Cores: 16
L1 Cache: 32.00 KB (Line: 64.00 B)
L2 Cache: 1.00 MB (Line: 64.00 B)
L3 Cache: 22.00 MB (Line: 64.00 B)
Hardware Supports:
ssse3
sse4_1
sse4_2
popcnt
avx
avx2
avx512f
avx512bw
Numa Nodes: 1
Numa Nodes of Cores: 0->0 | 1->0 | 2->0 | 3->0 | 4->0 | 5->0 | 6->0 | 7->0 | 8->0 | 9->0 | 10->0 | 11->0 | 12->0 | 13->0 | 14->0 | 15->0 |
Cores from CGroup CPUSET: None
Offline Cores: None
I20250210 16:14:54.237243 140029413038784 daemon.cpp:312] Disk Info:
Num disks 9: loop0, loop1, loop2, sr0, sda, sda1, sda2, sda3, dm-0
I20250210 16:14:54.237249 140029413038784 daemon.cpp:313] Mem Info: 62.79 GB
I20250210 16:14:54.237256 140029413038784 daemon.cpp:314] CPU Info:
Type: 0
Family: 6
Model: 85
Stepping: 7
ExtendModel: 5
ExtendFamily: 0
RunningInVM: 1
Vendor: GenuineIntel
Brand: Intel® Xeon® Silver 4216 CPU @ 2.10GHz
HardwareSupport: mmx sse sse2 sse3 ssse3 sse41 sse42 avx avx2 popcnt
I20250210 16:14:54.237271 140029413038784 daemon.cpp:315] openssl aesni support: 1
I20250210 16:14:54.827669 140029413038784 daemon.cpp:291] Minidump is disabled
I20250210 16:14:54.827686 140029413038784 starrocks_be.cpp:182] CN start step 1: daemon threads start successfully
I20250210 16:14:54.827809 140029413038784 starrocks_be.cpp:186] CN start step 2: jdbc driver manager init successfully
I20250210 16:14:54.827815 140029413038784 backend_options.cpp:156] priority cidrs in conf: 10.84.0.0/24
I20250210 16:14:54.827956 140029413038784 network_util.cpp:128] ipv6 link local address fe80::250:56ff:fe8f:53b7 is skipped
I20250210 16:14:54.827961 140029413038784 network_util.cpp:128] ipv6 link local address fe80::42:81ff:fed7:4c86 is skipped
I20250210 16:14:54.827965 140029413038784 network_util.cpp:128] ipv6 link local address fe80::c0b1:fcff:fed4:7424 is skipped
I20250210 16:14:54.827968 140029413038784 backend_options.cpp:70] check ip = 127.0.0.1
I20250210 16:14:54.827971 140029413038784 backend_options.cpp:78] skip ip not belonged to priority networks: 127.0.0.1
I20250210 16:14:54.827973 140029413038784 backend_options.cpp:70] check ip = 10.84.0.106
I20250210 16:14:54.827975 140029413038784 backend_options.cpp:118] localhost 10.84.0.106
I20250210 16:14:54.827977 140029413038784 starrocks_be.cpp:192] CN start step 3: backend network options init successfully
I20250210 16:14:54.828030 140029413038784 exec_env.cpp:288] Set storage page cache size 10922325368
I20250210 16:14:54.831296 140029413038784 starrocks_be.cpp:197] CN start step 4: global env init successfully
…skipping…
assthrough(0), clone(0), consistency(0), datacache(38500), jit(0)
W20250211 11:09:42.494358 140095972550208 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
W20250211 11:09:50.603547 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
W20250211 11:09:51.705435 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
I20250211 11:09:57.210615 140099786372672 daemon.cpp:158] Current memory statistics: process(176402568), query_pool(0), load(0), metadata(14360), compaction(0), schema_change(0), page_cache(0), update(0), chunk_allocator(0), passthrough(0), clone(0), consistency(0), datacache(38500), jit(0)
W20250211 11:09:58.812202 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
W20250211 11:09:59.914474 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
W20250211 11:10:01.016076 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
W20250211 11:10:02.117839 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
I20250211 11:10:06.949316 140095600649792 heartbeat_server.cpp:77] get heartbeat from FE. host:10.84.0.106, port:9020, cluster id:1128577660, run_mode:SHARED_DATA, counter:12949
W20250211 11:10:08.224325 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
W20250211 11:10:09.326247 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
W20250211 11:10:10.428330 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
W20250211 11:10:11.530125 140095989335616 thrift_rpc_helper.cpp:118] Rpc error: FE RPC failure, address=TNetworkAddress(hostname=10.84.0.106, port=9020), reason=No more data to read.
I20250211 11:10:12.215175 140099786372672 daemon.cpp:158] Current memory statistics: process(176402728), query_pool(0), load(0), metadata(14360), compaction(0), schema_change(0), page_cache(0), update(0), chunk_allocator(0), passthrough(0), clone(0), consistency(0), datacache(38500), jit(0)