
【StarRocks版本】2.0.1-f0de9ec
【集群规模】:3fe +5be
【机器信息】32C/128G
背景:数仓任务中很多增量任务需要 查询本表的最大 的 id ,根据此id 查询其他表的数据增量写入。
比如: insert into tablea select * from tableb where id > ( select max(id) from tablea);
这种类似 sql 在where条件中加入子查询后发现执行特别缓慢。
这里举个简单的查询例子
两个SQL分别查询耗时很短,但是如果拼接到一起,查询时间就会变得很长具体如图:
猜测应该是执行计划有问题?
SQL1:
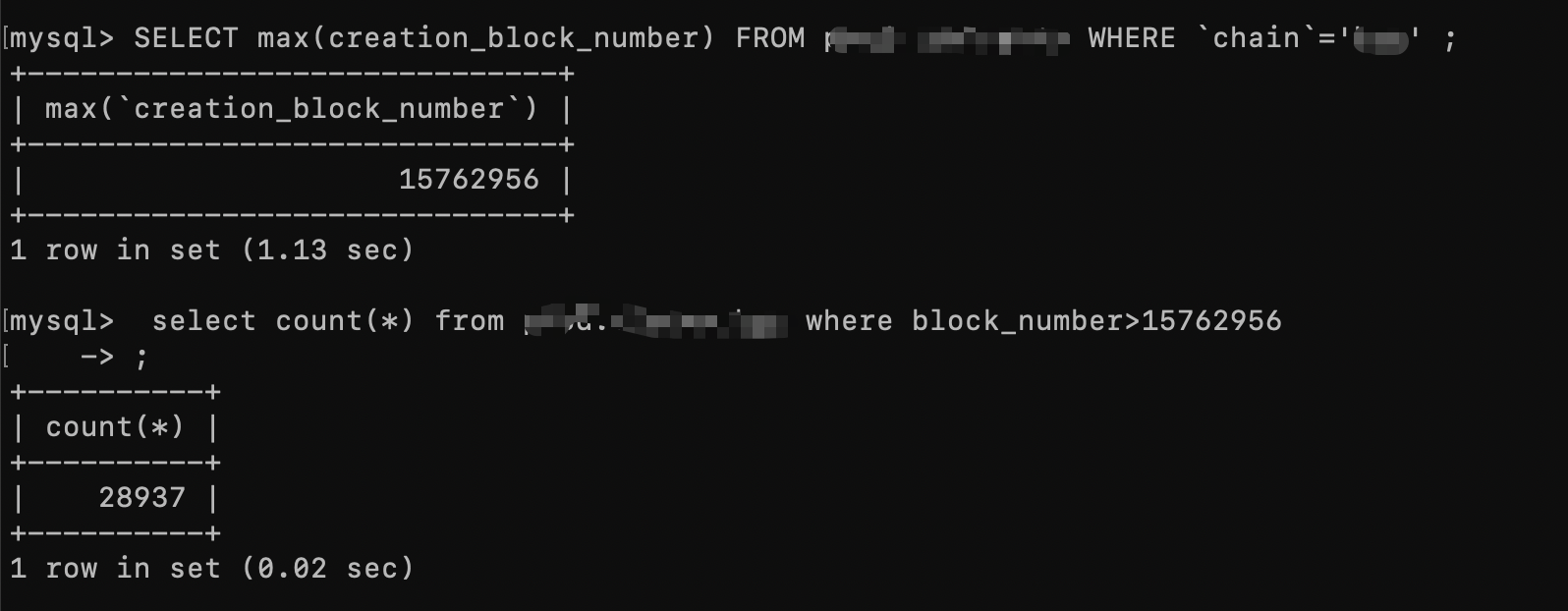
SQL2:

目前的方案是把SQL1 的结果先用脚本查出来,再通过脚本拼到SQL2里执行。
但是数仓任务 理想状态下是纯SQL。。希望这个执行计划可以优化下 。
资料:
执行计划以及profile:
explain.sql (570.1 KB)